Refine search
Actions for selected content:
200 results
Chapter 2 - Reflections on Some Strategies for Causal Inference in Psychiatry
- from Section 1
-
-
- Book:
- Causal Concepts in Psychopathology
- Published online:
- 11 May 2026
- Print publication:
- 16 July 2026, pp 8-41
-
- Chapter
- Export citation
The internalising blind spot in ADHD pharmacotherapy research
-
- Journal:
- The British Journal of Psychiatry , FirstView
- Published online by Cambridge University Press:
- 14 July 2026, pp. 1-2
-
- Article
- Export citation
Mixed-effects two-stage residual inclusion methods for individual patient data meta-analysis: A methodological framework for causal inference in survival analysis
-
- Journal:
- Research Synthesis Methods ,
- Published online by Cambridge University Press:
- 29 June 2026, pp. 1-18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Individual patient data meta-analyses (IPDMAs) provide powerful tools for synthesizing evidence across studies, yet methods for addressing unmeasured confounding in observational IPDMAs with survival outcomes are rarely implemented. Instrumental variable (IV) approaches offer causal inference capabilities but face practical challenges in hierarchical data structures, particularly the lack of standard diagnostics for instrument strength in nonlinear mixed-effects models. We adapt and evaluate a frequentist mixed-effects two-stage residual inclusion (2SRI) framework for survival IPDMAs, extending traditional IV methods to accommodate study-level and temporal clustering while handling time-to-event outcomes through Cox proportional hazards models. Because classical F-statistics are unavailable for logistic mixed-effects first-stage models, we propose the Wald $\chi ^2$
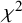 statistic as a practical instrument-strength diagnostic and empirically characterize its relationship to estimator performance. Through a comprehensive simulation study with 48 scenarios—varying unmeasured confounding (weak to very strong), instrument–treatment association strength (0.3–1.0), and cross-study IV allocation patterns—we evaluated 2SRI against naive mixed-effects Cox models using bias, coverage, variance, and mean squared error. The design was anchored to realistic IPDMA structure (10 studies, $N \approx 4,357$
statistic as a practical instrument-strength diagnostic and empirically characterize its relationship to estimator performance. Through a comprehensive simulation study with 48 scenarios—varying unmeasured confounding (weak to very strong), instrument–treatment association strength (0.3–1.0), and cross-study IV allocation patterns—we evaluated 2SRI against naive mixed-effects Cox models using bias, coverage, variance, and mean squared error. The design was anchored to realistic IPDMA structure (10 studies, $N \approx 4,357$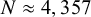 ) from pooled Ebola data, with 1,000 replications per scenario. Results show that under weak confounding, naive models dominate on all metrics. With moderate-to-strong confounding and realized Wald $\chi ^2$
) from pooled Ebola data, with 1,000 replications per scenario. Results show that under weak confounding, naive models dominate on all metrics. With moderate-to-strong confounding and realized Wald $\chi ^2$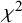 exceeding 150–200, mixed-effects 2SRI substantially reduces bias and achieves near-nominal coverage, though with inflated variance. We provide empirical guideposts linking realized first-stage strength to expected performance, enabling analysts to judge when 2SRI will outperform conventional approaches in hierarchical survival IPDMAs. All simulations assume a common treatment effect across studies. Performance under heterogeneous effects remains to be established.
exceeding 150–200, mixed-effects 2SRI substantially reduces bias and achieves near-nominal coverage, though with inflated variance. We provide empirical guideposts linking realized first-stage strength to expected performance, enabling analysts to judge when 2SRI will outperform conventional approaches in hierarchical survival IPDMAs. All simulations assume a common treatment effect across studies. Performance under heterogeneous effects remains to be established.
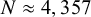
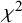
On the Foundations of the Design-Based Approach
-
- Journal:
- Political Analysis , First View
- Published online by Cambridge University Press:
- 25 June 2026, pp. 1-16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Estimating Treatment Effects on Proportions with Synthetic Controls
-
- Journal:
- Political Analysis , First View
- Published online by Cambridge University Press:
- 21 May 2026, pp. 1-17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

From Collective Punishment to Constraints on Authority
- Rethinking the Impact of US Sanctions on Venezuela
-
- Published online:
- 16 May 2026
- Print publication:
- 11 June 2026
-
- Element
-
- You have access
- Open access
- HTML
- Export citation
Introduction
-
- Book:
- Causal Processes and their Warrant
- Published online:
- 30 April 2026
- Print publication:
- 14 May 2026, pp 1-36
-
- Chapter
-
- You have access
- HTML
- Export citation
Smartphone CBT engagement and depressive symptoms: secondary analysis of the RESiLIENT trial using a time-varying exposure approach
-
- Journal:
- Psychological Medicine / Volume 56 / 2026
- Published online by Cambridge University Press:
- 13 May 2026, e145
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
4 - The Exogeneity Question
- from Part I - Preliminary Questions
-
- Book:
- A Practical Guide to Time Series Analysis
- Published online:
- 18 June 2026
- Print publication:
- 07 May 2026, pp 107-144
-
- Chapter
- Export citation
Measuring the effects of campaign events: Specifying and comparing estimates of the effect of Trump’s conviction
-
- Journal:
- Political Science Research and Methods , First View
- Published online by Cambridge University Press:
- 04 May 2026, pp. 1-16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
21 - Causal Inference
- from Part V - Reaching Out to New Domains
-
-
- Book:
- Working with Concepts
- Published online:
- 22 April 2026
- Print publication:
- 09 April 2026, pp 426-433
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
The Precision Psychiatry Imperative: Response to Seyedsalehi et al
-
- Journal:
- The British Journal of Psychiatry , FirstView
- Published online by Cambridge University Press:
- 07 April 2026, pp. 1-2
-
- Article
- Export citation
Inference at the Data’s Edge: Gaussian Processes for Estimation and Inference in the Face of Extrapolation Uncertainty
-
- Journal:
- Political Analysis , First View
- Published online by Cambridge University Press:
- 10 March 2026, pp. 1-20
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Antipsychotic-induced weight gain in psychosis: causal mediation analysis and feasibility study of causal actionable prediction model development using counterfactuals to target obesity
-
- Journal:
- The British Journal of Psychiatry , FirstView
- Published online by Cambridge University Press:
- 09 March 2026, pp. 1-10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Circulating fatty acids and osteoarthritis: evidence from observational and genetic analyses
-
- Journal:
- British Journal of Nutrition , First View
- Published online by Cambridge University Press:
- 16 February 2026, pp. 1-11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Analyzing the impact of events through surveys: formalizing biases and introducing the dual randomized survey design
-
- Journal:
- Political Science Research and Methods / Volume 14 / Issue 2 / April 2026
- Published online by Cambridge University Press:
- 12 February 2026, pp. 255-275
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Synthesis challenges in complex evidence: A critical analysis of systematic reviews of face mask efficacy
-
- Journal:
- Research Synthesis Methods / Volume 17 / Issue 4 / July 2026
- Published online by Cambridge University Press:
- 06 February 2026, pp. 714-733
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Causal Mediation and Functional Outcome Analysis with Process Data
-
- Journal:
- Psychometrika / Volume 91 / Issue 2 / April 2026
- Published online by Cambridge University Press:
- 23 January 2026, pp. 424-444
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Navigating the mismeasurement of intermediary variables in message-based experiments
-
- Journal:
- Political Science Research and Methods , First View
- Published online by Cambridge University Press:
- 21 January 2026, pp. 1-14
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
How federalism influences welfare spending: Belgium federalism reform through the perspective of the synthetic control method
-
- Journal:
- European Journal of Political Research / Volume 56 / Issue 3 / August 2017
- Published online by Cambridge University Press:
- 02 January 2026, pp. 680-702
-
- Article
- Export citation
