Refine search
Actions for selected content:
95780 results in Archaeology
Edge of England: landfall in Lincolnshire. By Derek Turner. 215mm. Pp xxi + 446, 32 col ills. Hurst, London, 2022. isbn 9781787386983. £12.99 (pbk).
-
- Journal:
- The Antiquaries Journal / Volume 103 / October 2023
- Published online by Cambridge University Press:
- 11 October 2023, pp. 458-460
- Print publication:
- October 2023
-
- Article
- Export citation
In Search of Mary Seacole: the making of a cultural icon. By Helen Rappaport. 240mm. Pp 405, figs and pls (some col). Simon and Schuster, London, 2022. isbn 9781398504431. £20 (hbk).
-
- Journal:
- The Antiquaries Journal / Volume 103 / October 2023
- Published online by Cambridge University Press:
- 05 October 2023, pp. 462-463
- Print publication:
- October 2023
-
- Article
- Export citation

RDC volume 65 issue 5 Cover and Back matter
-
- Journal:
- Radiocarbon / Volume 65 / Issue 5 / October 2023
- Published online by Cambridge University Press:
- 07 December 2023, pp. b1-b2
- Print publication:
- October 2023
-
- Article
-
- You have access
- Export citation
Rome Fellowships: Imperial heroism and the aesthetics of masculinity in Mussolini's Italy: the case of Rodolfo Graziani
-
- Journal:
- Papers of the British School at Rome / Volume 91 / October 2023
- Published online by Cambridge University Press:
- 16 November 2023, pp. 356-357
- Print publication:
- October 2023
-
- Article
- Export citation
BAYESIAN MODELING OF A PERIPHERAL MIDDLE BRONZE AGE SETTLEMENT AT ZAHRAT ADH-DHRA‘ 1, JORDAN
-
- Journal:
- Radiocarbon / Volume 65 / Issue 5 / October 2023
- Published online by Cambridge University Press:
- 07 November 2023, pp. 1022-1037
- Print publication:
- October 2023
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
THE PLUTONIUM PROJECT, HADRIAN'S VILLA, TIVOLI (COMUNE DI TIVOLI, PROVINCIA DI ROMA, REGIONE LAZIO)
-
- Journal:
- Papers of the British School at Rome / Volume 91 / October 2023
- Published online by Cambridge University Press:
- 16 November 2023, pp. 328-331
- Print publication:
- October 2023
-
- Article
- Export citation
NOTES FROM ROME 2022–23
-
- Journal:
- Papers of the British School at Rome / Volume 91 / October 2023
- Published online by Cambridge University Press:
- 16 November 2023, pp. 307-319
- Print publication:
- October 2023
-
- Article
- Export citation
Hugh Last Fellowship: Trimalchio and the monuments: material culture, self-fashioning, and social aesthetics in Petronius’ Satyricon
-
- Journal:
- Papers of the British School at Rome / Volume 91 / October 2023
- Published online by Cambridge University Press:
- 16 November 2023, pp. 350-351
- Print publication:
- October 2023
-
- Article
- Export citation
Rome Awards: Restorations of empire in Africa: ancient Rome and modern Italy's African colonies
-
- Journal:
- Papers of the British School at Rome / Volume 91 / October 2023
- Published online by Cambridge University Press:
- 16 November 2023, pp. 357-358
- Print publication:
- October 2023
-
- Article
- Export citation
Archaeologies & Antiquaries: essays by Dai Morgan Evans. Edited by Howard Williams, Kara Critchell and Sheena Evans. 245mm. Pp 298, 44 figs. Archaeopress, Oxford, 2022. ISBN 9781803271583. £48 (pbk).
-
- Journal:
- The Antiquaries Journal / Volume 103 / October 2023
- Published online by Cambridge University Press:
- 07 December 2023, pp. 460-461
- Print publication:
- October 2023
-
- Article
- Export citation
Senior Associate Fellowship: Museum practices in world literature: postcolonial objects in care at the Museo Italo Africano ‘Ilaria Alpi’
-
- Journal:
- Papers of the British School at Rome / Volume 91 / October 2023
- Published online by Cambridge University Press:
- 16 November 2023, pp. 352-353
- Print publication:
- October 2023
-
- Article
- Export citation
HELEN PATTERSON (1958–2022)
-
- Journal:
- Papers of the British School at Rome / Volume 91 / October 2023
- Published online by Cambridge University Press:
- 16 November 2023, pp. 1-7
- Print publication:
- October 2023
-
- Article
-
- You have access
- HTML
- Export citation
On Sherds, Vessels, and Pragmatics: Reaction to Feathers
-
- Journal:
- American Antiquity / Volume 88 / Issue 4 / October 2023
- Published online by Cambridge University Press:
- 03 November 2023, pp. 583-586
- Print publication:
- October 2023
-
- Article
- Export citation
A NEW RAMPED OXIDATION-14C ANALYSIS FACILITY AT THE NEIF RADIOCARBON LABORATORY, EAST KILBRIDE, UK
-
- Journal:
- Radiocarbon / Volume 65 / Issue 5 / October 2023
- Published online by Cambridge University Press:
- 31 October 2023, pp. 1213-1229
- Print publication:
- October 2023
-
- Article
- Export citation
Orfèvrerie de la Renaissance et des Temps Modernes, XVIe, XVIIe et XVIIIe siècles : La Collection du Musée du Louvre (3 vols). By Michèle Bimbenet-Privat, Florian Doux and Catherine Gougeon with Phillippe Palasi. 320mm. Pp 264, 392, 392, 2,270 ills. Louvre éditions, Paris, 2022. isbn 9782878443219. 165 euros (hbk).
-
- Journal:
- The Antiquaries Journal / Volume 103 / October 2023
- Published online by Cambridge University Press:
- 20 October 2023, pp. 457-458
- Print publication:
- October 2023
-
- Article
- Export citation
Amongst the Ruins: why civilizations collapse and communities disappear. By John Darlington. 240mm. Pp ix + 291, 77 col figs. Yale University Press, London and New York, 2023. ISBN 9780300259285. £25 (hbk).
-
- Journal:
- The Antiquaries Journal / Volume 103 / October 2023
- Published online by Cambridge University Press:
- 07 December 2023, pp. 438-439
- Print publication:
- October 2023
-
- Article
- Export citation
Paul Mellon Centre Fellowship: Henry Fuseli in Rome: defining a new, heroic style for British art
-
- Journal:
- Papers of the British School at Rome / Volume 91 / October 2023
- Published online by Cambridge University Press:
- 16 November 2023, pp. 364-365
- Print publication:
- October 2023
-
- Article
- Export citation
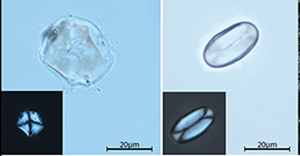
Human-plant interaction at the onset of agriculture: the PATH project
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
