Refine search
Actions for selected content:
49417 results in Computer Science
A zero-inflated Poisson latent position cluster model
-
- Journal:
- Network Science / Volume 14 / 2026
- Published online by Cambridge University Press:
- 23 January 2026, e2
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Stochastic dominance results under multivariate chain majorization for extreme order statistics of a generalized Gompertz distribution
-
- Journal:
- Probability in the Engineering and Informational Sciences , First View
- Published online by Cambridge University Press:
- 23 January 2026, pp. 1-25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
1 - Intelligence in Biological Systems
-
- Book:
- Introduction to Neuromorphic Computing
- Published online:
- 01 January 2026
- Print publication:
- 22 January 2026, pp 1-14
-
- Chapter
-
- You have access
- Export citation
3 - Techniques
- from Part I - Conceptual Introduction
-
- Book:
- A Hands-On Introduction to Data Science with R
- Published online:
- 07 February 2026
- Print publication:
- 22 January 2026, pp 75-108
-
- Chapter
- Export citation
Index
-
- Book:
- A Hands-On Introduction to Data Science with Python
- Published online:
- 07 February 2026
- Print publication:
- 22 January 2026, pp 385-404
-
- Chapter
- Export citation
11 - Hands-On with Solving Data Problems
- from Part IV - Applications, Evaluations, and Methods
-
- Book:
- A Hands-On Introduction to Data Science with R
- Published online:
- 07 February 2026
- Print publication:
- 22 January 2026, pp 311-340
-
- Chapter
- Export citation
Appendices
-
- Book:
- A Hands-On Introduction to Data Science with R
- Published online:
- 07 February 2026
- Print publication:
- 22 January 2026, pp 341-365
-
- Chapter
- Export citation
5 - Python for Statistical Analysis
- from Part II - Tools for Data Science
-
- Book:
- A Hands-On Introduction to Data Science with Python
- Published online:
- 07 February 2026
- Print publication:
- 22 January 2026, pp 132-150
-
- Chapter
- Export citation
3 - Artificial Synapses
-
- Book:
- Introduction to Neuromorphic Computing
- Published online:
- 01 January 2026
- Print publication:
- 22 January 2026, pp 27-76
-
- Chapter
- Export citation
Index
-
- Book:
- Introduction to Neuromorphic Computing
- Published online:
- 01 January 2026
- Print publication:
- 22 January 2026, pp 189-191
-
- Chapter
- Export citation
8 - Supervised Learning
- from Part III - Machine Learning for Data Science
-
- Book:
- A Hands-On Introduction to Data Science with R
- Published online:
- 07 February 2026
- Print publication:
- 22 January 2026, pp 203-256
-
- Chapter
- Export citation
Appendix D: - Introduction to Other Popular Databases
-
- Book:
- A Hands-On Introduction to Data Science with R
- Published online:
- 07 February 2026
- Print publication:
- 22 January 2026, pp 359-360
-
- Chapter
- Export citation
Appendix A: - Useful Formulas
-
- Book:
- A Hands-On Introduction to Data Science with Python
- Published online:
- 07 February 2026
- Print publication:
- 22 January 2026, pp 359-361
-
- Chapter
- Export citation
Part II - Tools for Data Science
-
- Book:
- A Hands-On Introduction to Data Science with R
- Published online:
- 07 February 2026
- Print publication:
- 22 January 2026, pp 109-174
-
- Chapter
- Export citation
3 - Techniques
- from Part I - Conceptual Introductions
-
- Book:
- A Hands-On Introduction to Data Science with Python
- Published online:
- 07 February 2026
- Print publication:
- 22 January 2026, pp 75-108
-
- Chapter
- Export citation
CONTRADICTIONS WITHOUT NEGATION AND A PROOF-THEORETIC, BILATERALIST ACCOUNT OF CONNEXIVE LOGICS
- Part of
-
- Journal:
- The Review of Symbolic Logic , First View
- Published online by Cambridge University Press:
- 22 January 2026, pp. 1-28
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This paper investigates the negation-free fragment of the bi-connexive logic 2C, called 2C
 $_-$, from the perspective of bilateralist proof-theoretic semantics (PTS). It is argued that eliminating primitive negation has two important conceptual consequences. First, it requires a reconceptualization of contradictory logics: in a bilateralist framework, contradiction need not be understood in terms of negation inconsistency, but rather as the coexistence of proofs and refutations for certain formulas within a non-trivial system. Second, it challenges the standard definition of connexive logics, which typically rely on negation-based schemata. Instead, a rule-based conception of connexivity, grounded in bilateralist PTS, is proposed. This reconception avoids dependence on the validation of specific formula schemata and thereby also dependence on negation. The paper also addresses the issue of proof–refutation duality in the absence of strong negation, which can be formalized and recovered at a meta-level by extending the system with a two-sorted typed
$_-$, from the perspective of bilateralist proof-theoretic semantics (PTS). It is argued that eliminating primitive negation has two important conceptual consequences. First, it requires a reconceptualization of contradictory logics: in a bilateralist framework, contradiction need not be understood in terms of negation inconsistency, but rather as the coexistence of proofs and refutations for certain formulas within a non-trivial system. Second, it challenges the standard definition of connexive logics, which typically rely on negation-based schemata. Instead, a rule-based conception of connexivity, grounded in bilateralist PTS, is proposed. This reconception avoids dependence on the validation of specific formula schemata and thereby also dependence on negation. The paper also addresses the issue of proof–refutation duality in the absence of strong negation, which can be formalized and recovered at a meta-level by extending the system with a two-sorted typed 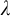 $\lambda $-calculus.
$\lambda $-calculus.

Appendix A: - Useful Formulas
-
- Book:
- A Hands-On Introduction to Data Science with R
- Published online:
- 07 February 2026
- Print publication:
- 22 January 2026, pp 341-343
-
- Chapter
- Export citation
Preface
-
- Book:
- Introduction to Neuromorphic Computing
- Published online:
- 01 January 2026
- Print publication:
- 22 January 2026, pp xi-xii
-
- Chapter
- Export citation
11 - Hands-On with Solving Data Problems
- from Part IV - Applications, Evaluations, and Methods
-
- Book:
- A Hands-On Introduction to Data Science with Python
- Published online:
- 07 February 2026
- Print publication:
- 22 January 2026, pp 329-358
-
- Chapter
- Export citation
Copyright page
-
- Book:
- A Hands-On Introduction to Data Science with R
- Published online:
- 07 February 2026
- Print publication:
- 22 January 2026, pp iv-iv
-
- Chapter
- Export citation
