Refine search
Actions for selected content:
49525 results in Computer Science
Bicategorical type theory: semantics and syntax
-
- Journal:
- Mathematical Structures in Computer Science / Volume 33 / Issue 10 / November 2023
- Published online by Cambridge University Press:
- 17 October 2023, pp. 868-912
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Business transactions and ownership ties between firms
-
- Journal:
- Network Science / Volume 12 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 16 October 2023, pp. 1-20
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The role of sustainability knowledge-action platforms in advancing multi-stakeholder engagement on sustainability
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 16 October 2023, e33
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Improving the sea state forecasts by using local wave observations and the ensembleBMA software
- Part of
-
- Journal:
- Environmental Data Science / Volume 2 / 2023
- Published online by Cambridge University Press:
- 13 October 2023, e36
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The main goal of this study is to investigate if the publicly available sea state forecasts for the Aran Islands region in the Republic of Ireland can be improved. This improvement is achieved by using the combination of local scale sea state forecasts and Bayesian Model Averaging techniques. The question of a good forecast has been around since the start of forecasting. With current state-of-the-art numerical models, computational power, and vast data availability, we consider whether it is possible to improve model forecasts only by using the combination of publicly available forecasts, free open-source software, and very moderate computational power. It is shown that it is possible to improve the sea state forecast by at least
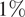 $ 1\% $, and in some cases up to
$ 1\% $, and in some cases up to 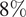 $ 8\% $. The reduction of error is between
$ 8\% $. The reduction of error is between 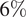 $ 6\% $ and
$ 6\% $ and 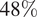 $ 48\% $. With a more careful and specific selection of training parameters, it is possible to improve the forecast accuracy even more. The possibility of extending this local improvement to the whole coastal area around the island of Ireland is explored. Unfortunately, it is currently impossible, due to a lack of live data buoys in the coastal waters. Nonetheless, it is shown that the proposed process is simple and can be implemented by anyone whose livelihood depends on an accurate sea state forecast. It does not require large computational power, model forecasts are publicly available, and there is minimal to no training in forecasting and statistics required to enable one to perform such improvements for one’s area of interest, provided one has access to live wave data.
$ 48\% $. With a more careful and specific selection of training parameters, it is possible to improve the forecast accuracy even more. The possibility of extending this local improvement to the whole coastal area around the island of Ireland is explored. Unfortunately, it is currently impossible, due to a lack of live data buoys in the coastal waters. Nonetheless, it is shown that the proposed process is simple and can be implemented by anyone whose livelihood depends on an accurate sea state forecast. It does not require large computational power, model forecasts are publicly available, and there is minimal to no training in forecasting and statistics required to enable one to perform such improvements for one’s area of interest, provided one has access to live wave data.
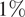
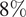
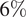
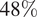

Virtual Reality
-
- Published online:
- 12 October 2023
- Print publication:
- 02 November 2023
Part II - Deep-Learning Architecture for Various Imaging Architectures
-
- Book:
- Deep Learning for Biomedical Image Reconstruction
- Published online:
- 15 September 2023
- Print publication:
- 12 October 2023, pp 87-88
-
- Chapter
- Export citation
Part III - Genome-Scale Index Structures
-
- Book:
- Genome-Scale Algorithm Design
- Published online:
- 28 September 2023
- Print publication:
- 12 October 2023, pp 143-144
-
- Chapter
- Export citation
Chapter 8 - Proving Central Theorem 4
-
- Book:
- A Theory of Truth
- Published online:
- 07 October 2023
- Print publication:
- 12 October 2023, pp 207-254
-
- Chapter
- Export citation
Chapter 5 - Proving Central Theorem 1
-
- Book:
- A Theory of Truth
- Published online:
- 07 October 2023
- Print publication:
- 12 October 2023, pp 107-130
-
- Chapter
- Export citation
1 - Formalizing Deep Neural Networks
- from Part I - Theory of Deep Learning for Image Reconstruction
-
-
- Book:
- Deep Learning for Biomedical Image Reconstruction
- Published online:
- 15 September 2023
- Print publication:
- 12 October 2023, pp 3-12
-
- Chapter
- Export citation
2 - Geometry of Deep Learning
- from Part I - Theory of Deep Learning for Image Reconstruction
-
-
- Book:
- Deep Learning for Biomedical Image Reconstruction
- Published online:
- 15 September 2023
- Print publication:
- 12 October 2023, pp 13-27
-
- Chapter
- Export citation
14 - Haplotype analysis
- from Part V - Applications
-
- Book:
- Genome-Scale Algorithm Design
- Published online:
- 28 September 2023
- Print publication:
- 12 October 2023, pp 333-343
-
- Chapter
- Export citation
9 - k-Space Deep Learning for MR Reconstruction and Artifact Removal
- from Part II - Deep-Learning Architecture for Various Imaging Architectures
-
-
- Book:
- Deep Learning for Biomedical Image Reconstruction
- Published online:
- 15 September 2023
- Print publication:
- 12 October 2023, pp 200-222
-
- Chapter
- Export citation
Preface
-
- Book:
- Deep Learning for Biomedical Image Reconstruction
- Published online:
- 15 September 2023
- Print publication:
- 12 October 2023, pp xix-xxii
-
- Chapter
- Export citation
Contents
-
- Book:
- Deep Learning for Biomedical Image Reconstruction
- Published online:
- 15 September 2023
- Print publication:
- 12 October 2023, pp vii-xiii
-
- Chapter
- Export citation
11 - Ultrasound Image Artifact Removal using Deep Neural Networks
- from Part II - Deep-Learning Architecture for Various Imaging Architectures
-
-
- Book:
- Deep Learning for Biomedical Image Reconstruction
- Published online:
- 15 September 2023
- Print publication:
- 12 October 2023, pp 252-276
-
- Chapter
- Export citation
7 - Hidden Markov models
- from Part II - Fundamentals of Biological Sequence Analysis
-
- Book:
- Genome-Scale Algorithm Design
- Published online:
- 28 September 2023
- Print publication:
- 12 October 2023, pp 129-142
-
- Chapter
- Export citation
9 - Burrows–Wheeler indexes
- from Part III - Genome-Scale Index Structures
-
- Book:
- Genome-Scale Algorithm Design
- Published online:
- 28 September 2023
- Print publication:
- 12 October 2023, pp 174-216
-
- Chapter
- Export citation
Computable soft separation axioms
-
- Journal:
- Mathematical Structures in Computer Science / Volume 33 / Issue 9 / October 2023
- Published online by Cambridge University Press:
- 12 October 2023, pp. 781-808
-
- Article
- Export citation
