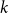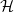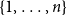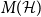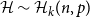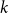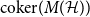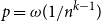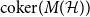Refine search
Actions for selected content:
48287 results in Computer Science
Distributed Subweb Specifications for Traversing the Web
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 2 / March 2024
- Published online by Cambridge University Press:
- 25 April 2023, pp. 394-420
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
WHAT MODEL COMPANIONSHIP CAN SAY ABOUT THE CONTINUUM PROBLEM
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 17 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 25 April 2023, pp. 546-585
- Print publication:
- June 2024
-
- Article
- Export citation
-
We present recent results on the model companions of set theory, placing them in the context of a current debate in the philosophy of mathematics. We start by describing the dependence of the notion of model companionship on the signature, and then we analyze this dependence in the specific case of set theory. We argue that the most natural model companions of set theory describe (as the signature in which we axiomatize set theory varies) theories of
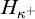 $H_{\kappa ^+}$, as
$H_{\kappa ^+}$, as 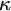 $\kappa $ ranges among the infinite cardinals. We also single out
$\kappa $ ranges among the infinite cardinals. We also single out 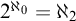 $2^{\aleph _0}=\aleph _2$ as the unique solution of the continuum problem which can (and does) belong to some model companion of set theory (enriched with large cardinal axioms). While doing so we bring to light that set theory enriched by large cardinal axioms in the range of supercompactness has as its model companion (with respect to its first order axiomatization in certain natural signatures) the theory of
$2^{\aleph _0}=\aleph _2$ as the unique solution of the continuum problem which can (and does) belong to some model companion of set theory (enriched with large cardinal axioms). While doing so we bring to light that set theory enriched by large cardinal axioms in the range of supercompactness has as its model companion (with respect to its first order axiomatization in certain natural signatures) the theory of 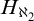 $H_{\aleph _2}$ as given by a strong form of Woodin’s axiom
$H_{\aleph _2}$ as given by a strong form of Woodin’s axiom  $(*)$ (which holds assuming
$(*)$ (which holds assuming 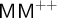 $\mathsf {MM}^{++}$). Finally this model-theoretic approach to set-theoretic validities is explained and justified in terms of a form of maximality inspired by Hilbert’s axiom of completeness.
$\mathsf {MM}^{++}$). Finally this model-theoretic approach to set-theoretic validities is explained and justified in terms of a form of maximality inspired by Hilbert’s axiom of completeness.
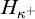
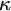
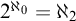
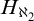

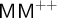
Problems and results on 1-cross-intersecting set pair systems
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 4 / July 2023
- Published online by Cambridge University Press:
- 24 April 2023, pp. 691-702
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The notion of cross-intersecting set pair system of size
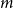 $m$,
$m$, 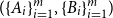 $ (\{A_i\}_{i=1}^m, \{B_i\}_{i=1}^m )$ with
$ (\{A_i\}_{i=1}^m, \{B_i\}_{i=1}^m )$ with 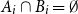 $A_i\cap B_i=\emptyset$ and
$A_i\cap B_i=\emptyset$ and 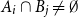 $A_i\cap B_j\ne \emptyset$, was introduced by Bollobás and it became an important tool of extremal combinatorics. His classical result states that
$A_i\cap B_j\ne \emptyset$, was introduced by Bollobás and it became an important tool of extremal combinatorics. His classical result states that 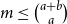 $m\le\binom{a+b}{a}$ if
$m\le\binom{a+b}{a}$ if 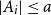 $|A_i|\le a$ and
$|A_i|\le a$ and 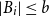 $|B_i|\le b$ for each
$|B_i|\le b$ for each 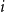 $i$. Our central problem is to see how this bound changes with the additional condition
$i$. Our central problem is to see how this bound changes with the additional condition 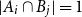 $|A_i\cap B_j|=1$ for
$|A_i\cap B_j|=1$ for 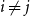 $i\ne j$. Such a system is called
$i\ne j$. Such a system is called 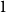 $1$-cross-intersecting. We show that these systems are related to perfect graphs, clique partitions of graphs, and finite geometries. We prove that their maximum size is
$1$-cross-intersecting. We show that these systems are related to perfect graphs, clique partitions of graphs, and finite geometries. We prove that their maximum size isat least
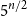 $5^{n/2}$ for
$5^{n/2}$ for  $n$ even,
$n$ even, 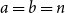 $a=b=n$,
$a=b=n$,equal to
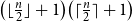 $\bigl (\lfloor \frac{n}{2}\rfloor +1\bigr )\bigl (\lceil \frac{n}{2}\rceil +1\bigr )$ if
$\bigl (\lfloor \frac{n}{2}\rfloor +1\bigr )\bigl (\lceil \frac{n}{2}\rceil +1\bigr )$ if 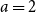 $a=2$ and
$a=2$ and 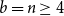 $b=n\ge 4$,
$b=n\ge 4$,at most
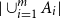 $|\cup _{i=1}^m A_i|$,
$|\cup _{i=1}^m A_i|$,asymptotically
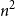 $n^2$ if
$n^2$ if 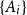 $\{A_i\}$ is a linear hypergraph (
$\{A_i\}$ is a linear hypergraph (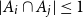 $|A_i\cap A_j|\le 1$ for
$|A_i\cap A_j|\le 1$ for 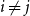 $i\ne j$),
$i\ne j$),asymptotically
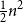 ${1\over 2}n^2$ if
${1\over 2}n^2$ if 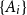 $\{A_i\}$ and
$\{A_i\}$ and 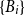 $\{B_i\}$ are both linear hypergraphs.
$\{B_i\}$ are both linear hypergraphs.
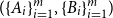
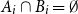
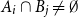
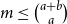
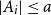
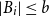
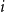
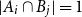
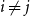
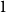
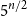

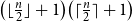
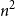
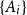
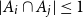
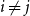
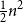
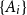
A physics-based domain adaptation framework for modeling and forecasting building energy systems
-
- Journal:
- Data-Centric Engineering / Volume 4 / 2023
- Published online by Cambridge University Press:
- 24 April 2023, e10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Operationalizing digital self-determination
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 24 April 2023, e14
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Clique-factors in graphs with sublinear
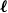 $\boldsymbol\ell$-independence number
$\boldsymbol\ell$-independence number
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 4 / July 2023
- Published online by Cambridge University Press:
- 24 April 2023, pp. 665-681
-
- Article
- Export citation
-
Given a graph
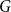 $G$ and an integer
$G$ and an integer 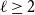 $\ell \ge 2$, we denote by
$\ell \ge 2$, we denote by 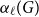 $\alpha _{\ell }(G)$ the maximum size of a
$\alpha _{\ell }(G)$ the maximum size of a 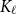 $K_{\ell }$-free subset of vertices in
$K_{\ell }$-free subset of vertices in 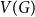 $V(G)$. A recent question of Nenadov and Pehova asks for determining the best possible minimum degree conditions forcing clique-factors in
$V(G)$. A recent question of Nenadov and Pehova asks for determining the best possible minimum degree conditions forcing clique-factors in  $n$-vertex graphs
$n$-vertex graphs 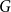 $G$ with
$G$ with 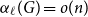 $\alpha _{\ell }(G) = o(n)$, which can be seen as a Ramsey–Turán variant of the celebrated Hajnal–Szemerédi theorem. In this paper we find the asymptotical sharp minimum degree threshold for
$\alpha _{\ell }(G) = o(n)$, which can be seen as a Ramsey–Turán variant of the celebrated Hajnal–Szemerédi theorem. In this paper we find the asymptotical sharp minimum degree threshold for 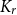 $K_r$-factors in
$K_r$-factors in  $n$-vertex graphs
$n$-vertex graphs 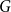 $G$ with
$G$ with 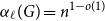 $\alpha _\ell (G)=n^{1-o(1)}$ for all
$\alpha _\ell (G)=n^{1-o(1)}$ for all 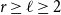 $r\ge \ell \ge 2$.
$r\ge \ell \ge 2$.
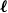
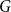
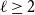
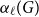
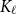
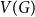

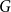
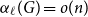
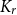

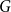
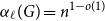
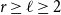
Design and optimization of a decoupled serial constant force microgripper for force sensitive objects manipulation
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
To address coupling motion issues and realize large constant force range of microgrippers, we present a serial two-degree-of-freedom compliant constant force microgripper (CCFMG) in this paper. To realize a large output displacement in a compact structure, Scott–Russell displacement amplification mechanisms, bridge-type displacement amplification mechanisms, and lever amplification mechanisms are combined to compensate stroke of piezoelectric actuators. In addition, constant force modules are utilized to achieve a constant force output. We investigated CCFMG’s performances by means of pseudo-rigid body models and finite element analysis. Simulation results show that the proposed CCFMG has a stroke of 781.34
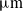 ${\unicode[Times]{x03BC}}\mathrm{m}$ in the X-direction and a stroke of 258.05
${\unicode[Times]{x03BC}}\mathrm{m}$ in the X-direction and a stroke of 258.05 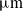 ${\unicode[Times]{x03BC}}\mathrm{m}$ in the Y-direction, and the decoupling rates in two directions are 1.1% and 0.9%, respectively. The average output constant force of the clamp is 37.49 N. The amplification ratios of the bridge-type amplifier and the Scott–Russell amplifier are 7.02 and 3, respectively. Through finite element analysis-based optimization, the constant force stroke of CCFMG is increased from the initial 1.6 to 3 mm.
${\unicode[Times]{x03BC}}\mathrm{m}$ in the Y-direction, and the decoupling rates in two directions are 1.1% and 0.9%, respectively. The average output constant force of the clamp is 37.49 N. The amplification ratios of the bridge-type amplifier and the Scott–Russell amplifier are 7.02 and 3, respectively. Through finite element analysis-based optimization, the constant force stroke of CCFMG is increased from the initial 1.6 to 3 mm.
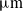
Expected number of faces in a random embedding of any graph is at most linear
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 4 / July 2023
- Published online by Cambridge University Press:
- 24 April 2023, pp. 682-690
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
A random two-cell embedding of a given graph
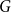 $G$ is obtained by choosing a random local rotation around every vertex. We analyse the expected number of faces of such an embedding, which is equivalent to studying its average genus. In 1991, Stahl [5] proved that the expected number of faces in a random embedding of an arbitrary graph of order
$G$ is obtained by choosing a random local rotation around every vertex. We analyse the expected number of faces of such an embedding, which is equivalent to studying its average genus. In 1991, Stahl [5] proved that the expected number of faces in a random embedding of an arbitrary graph of order  $n$ is at most
$n$ is at most 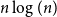 $n\log (n)$. While there are many families of graphs whose expected number of faces is
$n\log (n)$. While there are many families of graphs whose expected number of faces is 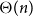 $\Theta (n)$, none are known where the expected number would be super-linear. This led the authors of [1] to conjecture that there is a linear upper bound. In this note we confirm their conjecture by proving that for any
$\Theta (n)$, none are known where the expected number would be super-linear. This led the authors of [1] to conjecture that there is a linear upper bound. In this note we confirm their conjecture by proving that for any  $n$-vertex multigraph, the expected number of faces in a random two-cell embedding is at most
$n$-vertex multigraph, the expected number of faces in a random two-cell embedding is at most 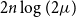 $2n\log (2\mu )$, where
$2n\log (2\mu )$, where 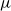 $\mu$ is the maximum edge-multiplicity. This bound is best possible up to a constant factor.
$\mu$ is the maximum edge-multiplicity. This bound is best possible up to a constant factor.
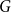

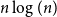
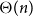

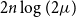
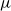
Open data as an anticorruption tool? Using distributed cognition to understand breakdowns in the creation of transparency data
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 24 April 2023, e13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Idea evaluation as a design process: understanding how experts develop ideas and manage fixations
-
- Journal:
- Design Science / Volume 9 / 2023
- Published online by Cambridge University Press:
- 24 April 2023, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Introduction to the Special Issue on Logic Rules and Reasoning: Selected Papers from the 4th International Joint Conference on Rules and Reasoning (RuleML+RR 2020)
-
- Journal:
- Theory and Practice of Logic Programming / Volume 23 / Issue 3 / May 2023
- Published online by Cambridge University Press:
- 24 April 2023, pp. 503-506
-
- Article
-
- You have access
- HTML
- Export citation
Index
-
- Book:
- 200 Problems on Languages, Automata, and Computation
- Published online:
- 14 April 2023
- Print publication:
- 20 April 2023, pp 251-256
-
- Chapter
- Export citation
List of Notation
-
- Book:
- 200 Problems on Languages, Automata, and Computation
- Published online:
- 14 April 2023
- Print publication:
- 20 April 2023, pp ix-x
-
- Chapter
- Export citation
8 - Theory of Computation
- from Part II - Solutions
-
- Book:
- 200 Problems on Languages, Automata, and Computation
- Published online:
- 14 April 2023
- Print publication:
- 20 April 2023, pp 193-249
-
- Chapter
- Export citation
Probabilistic selection and design of concrete using machine learning
-
- Journal:
- Data-Centric Engineering / Volume 4 / 2023
- Published online by Cambridge University Press:
- 20 April 2023, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Abelian groups from random hypergraphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 4 / July 2023
- Published online by Cambridge University Press:
- 20 April 2023, pp. 654-664
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
For a
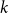 $k$-uniform hypergraph
$k$-uniform hypergraph 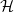 $\mathcal{H}$ on vertex set
$\mathcal{H}$ on vertex set 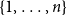 $\{1, \ldots, n\}$ we associate a particular signed incidence matrix
$\{1, \ldots, n\}$ we associate a particular signed incidence matrix 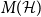 $M(\mathcal{H})$ over the integers. For
$M(\mathcal{H})$ over the integers. For 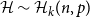 $\mathcal{H} \sim \mathcal{H}_k(n, p)$ an Erdős–Rényi random
$\mathcal{H} \sim \mathcal{H}_k(n, p)$ an Erdős–Rényi random 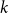 $k$-uniform hypergraph,
$k$-uniform hypergraph, 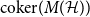 ${\mathrm{coker}}(M(\mathcal{H}))$ is then a model for random abelian groups. Motivated by conjectures from the study of random simplicial complexes we show that for
${\mathrm{coker}}(M(\mathcal{H}))$ is then a model for random abelian groups. Motivated by conjectures from the study of random simplicial complexes we show that for 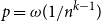 $p = \omega (1/n^{k - 1})$,
$p = \omega (1/n^{k - 1})$, 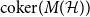 ${\mathrm{coker}}(M(\mathcal{H}))$ is torsion-free.
${\mathrm{coker}}(M(\mathcal{H}))$ is torsion-free.