Refine search
Actions for selected content:
48202 results in Computer Science
Coevolutionary strategies at the collective level for improved generalism
-
- Journal:
- Data-Centric Engineering / Volume 4 / 2023
- Published online by Cambridge University Press:
- 06 February 2023, e6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A rewriting coherence theorem with applications in homotopy type theory
-
- Journal:
- Mathematical Structures in Computer Science / Volume 32 / Issue 7 / August 2022
- Published online by Cambridge University Press:
- 06 February 2023, pp. 982-1014
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
How to do human evaluation: A brief introduction to user studies in NLP
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 5 / September 2023
- Published online by Cambridge University Press:
- 06 February 2023, pp. 1199-1222
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Random effects in dynamic network actor models
-
- Journal:
- Network Science / Volume 11 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 06 February 2023, pp. 249-266
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On function spaces equipped with Isbell topology and Scott topology
-
- Journal:
- Mathematical Structures in Computer Science / Volume 32 / Issue 8 / September 2022
- Published online by Cambridge University Press:
- 05 February 2023, pp. 1099-1116
-
- Article
- Export citation
-
In this paper, we mainly study the function spaces related to H-sober spaces. For an irreducible subset system H and
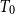 $T_{0}$ spaces X and Y, it is proved that the following three conditions are equivalent: (1) the Scott space
$T_{0}$ spaces X and Y, it is proved that the following three conditions are equivalent: (1) the Scott space 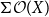 $\Sigma \mathcal O(X)$ of the lattice of all open sets of X is H-sober; (2) for every H-sober space Y, the function space
$\Sigma \mathcal O(X)$ of the lattice of all open sets of X is H-sober; (2) for every H-sober space Y, the function space 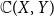 $\mathbb{C}(X, Y)$ of all continuous mappings from X to Y equipped with the Isbell topology is H-sober; (3) for every H-sober space Y, the Isbell topology on
$\mathbb{C}(X, Y)$ of all continuous mappings from X to Y equipped with the Isbell topology is H-sober; (3) for every H-sober space Y, the Isbell topology on 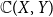 $\mathbb{C}(X, Y)$ has property S with respect to H. One immediate corollary is that for a
$\mathbb{C}(X, Y)$ has property S with respect to H. One immediate corollary is that for a 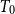 $T_{0}$ space X, Y is a d-space (resp., well-filtered space) iff the function space
$T_{0}$ space X, Y is a d-space (resp., well-filtered space) iff the function space 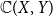 $\mathbb{C}(X, Y)$ equipped with the Isbell topology is a d-space (resp., well-filtered space). It is shown that for any
$\mathbb{C}(X, Y)$ equipped with the Isbell topology is a d-space (resp., well-filtered space). It is shown that for any 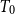 $T_0$ space X for which the Scott space
$T_0$ space X for which the Scott space 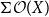 $\Sigma \mathcal O(X)$ is non-sober, the function space
$\Sigma \mathcal O(X)$ is non-sober, the function space 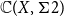 $\mathbb{C}(X, \Sigma 2)$ equipped with the Isbell topology is not sober. The function spaces
$\mathbb{C}(X, \Sigma 2)$ equipped with the Isbell topology is not sober. The function spaces 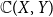 $\mathbb{C}(X, Y)$ equipped with the Scott topology, the compact-open topology and the pointwise convergence topology are also discussed. Our study also leads to a number of questions, whose answers will deepen our understanding of the function spaces related to H-sober spaces.
$\mathbb{C}(X, Y)$ equipped with the Scott topology, the compact-open topology and the pointwise convergence topology are also discussed. Our study also leads to a number of questions, whose answers will deepen our understanding of the function spaces related to H-sober spaces.
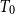
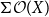
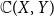
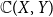
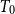
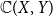
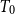
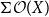
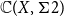
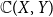
Pareto-optimal reinsurance with default risk and solvency regulation
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 2 / April 2023
- Published online by Cambridge University Press:
- 03 February 2023, pp. 518-545
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Bipartite-ness under smooth conditions
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 4 / July 2023
- Published online by Cambridge University Press:
- 03 February 2023, pp. 546-558
-
- Article
- Export citation
-
Given a family
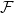 $\mathcal{F}$ of bipartite graphs, the Zarankiewicz number
$\mathcal{F}$ of bipartite graphs, the Zarankiewicz number 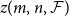 $z(m,n,\mathcal{F})$ is the maximum number of edges in an
$z(m,n,\mathcal{F})$ is the maximum number of edges in an 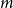 $m$ by
$m$ by  $n$ bipartite graph
$n$ bipartite graph 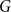 $G$ that does not contain any member of
$G$ that does not contain any member of 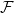 $\mathcal{F}$ as a subgraph (such
$\mathcal{F}$ as a subgraph (such 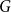 $G$ is called
$G$ is called 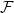 $\mathcal{F}$-free). For
$\mathcal{F}$-free). For 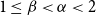 $1\leq \beta \lt \alpha \lt 2$, a family
$1\leq \beta \lt \alpha \lt 2$, a family 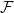 $\mathcal{F}$ of bipartite graphs is
$\mathcal{F}$ of bipartite graphs is 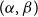 $(\alpha,\beta )$-smooth if for some
$(\alpha,\beta )$-smooth if for some 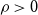 $\rho \gt 0$ and every
$\rho \gt 0$ and every 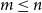 $m\leq n$,
$m\leq n$, 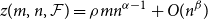 $z(m,n,\mathcal{F})=\rho m n^{\alpha -1}+O(n^\beta )$. Motivated by their work on a conjecture of Erdős and Simonovits on compactness and a classic result of Andrásfai, Erdős and Sós, Allen, Keevash, Sudakov and Verstraëte proved that for any
$z(m,n,\mathcal{F})=\rho m n^{\alpha -1}+O(n^\beta )$. Motivated by their work on a conjecture of Erdős and Simonovits on compactness and a classic result of Andrásfai, Erdős and Sós, Allen, Keevash, Sudakov and Verstraëte proved that for any 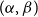 $(\alpha,\beta )$-smooth family
$(\alpha,\beta )$-smooth family 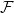 $\mathcal{F}$, there exists
$\mathcal{F}$, there exists 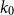 $k_0$ such that for all odd
$k_0$ such that for all odd 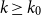 $k\geq k_0$ and sufficiently large
$k\geq k_0$ and sufficiently large  $n$, any
$n$, any  $n$-vertex
$n$-vertex 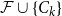 $\mathcal{F}\cup \{C_k\}$-free graph with minimum degree at least
$\mathcal{F}\cup \{C_k\}$-free graph with minimum degree at least 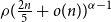 $\rho (\frac{2n}{5}+o(n))^{\alpha -1}$ is bipartite. In this paper, we strengthen their result by showing that for every real
$\rho (\frac{2n}{5}+o(n))^{\alpha -1}$ is bipartite. In this paper, we strengthen their result by showing that for every real 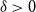 $\delta \gt 0$, there exists
$\delta \gt 0$, there exists 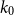 $k_0$ such that for all odd
$k_0$ such that for all odd 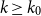 $k\geq k_0$ and sufficiently large
$k\geq k_0$ and sufficiently large  $n$, any
$n$, any  $n$-vertex
$n$-vertex 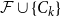 $\mathcal{F}\cup \{C_k\}$-free graph with minimum degree at least
$\mathcal{F}\cup \{C_k\}$-free graph with minimum degree at least 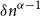 $\delta n^{\alpha -1}$ is bipartite. Furthermore, our result holds under a more relaxed notion of smoothness, which include the families
$\delta n^{\alpha -1}$ is bipartite. Furthermore, our result holds under a more relaxed notion of smoothness, which include the families 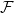 $\mathcal{F}$ consisting of the single graph
$\mathcal{F}$ consisting of the single graph 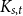 $K_{s,t}$ when
$K_{s,t}$ when 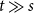 $t\gg s$. We also prove an analogous result for
$t\gg s$. We also prove an analogous result for 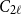 $C_{2\ell }$-free graphs for every
$C_{2\ell }$-free graphs for every 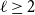 $\ell \geq 2$, which complements a result of Keevash, Sudakov and Verstraëte.
$\ell \geq 2$, which complements a result of Keevash, Sudakov and Verstraëte.
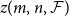
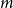

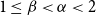
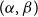
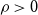
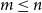
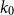
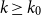


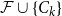
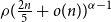
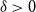
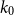
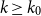


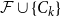
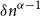
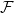
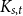
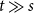
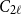
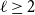

Reimagining Shakespeare Education
- Teaching and Learning through Collaboration
-
- Published online:
- 02 February 2023
- Print publication:
- 23 February 2023

Age of Information
- Foundations and Applications
-
- Published online:
- 02 February 2023
- Print publication:
- 09 February 2023

Legal Tech and the Future of Civil Justice
-
- Published online:
- 02 February 2023
- Print publication:
- 09 February 2023
-
- Book
-
- You have access
- Open access
- Export citation
Multiphase segmentation of digital material images
-
- Journal:
- Data-Centric Engineering / Volume 4 / 2023
- Published online by Cambridge University Press:
- 02 February 2023, e5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Multiphase segmentation of pore-scale features and identification of mineralogy from digital images of materials is critical for many applications in the natural resources sector. However, the materials involved (rocks, catalyst pellets, and synthetic alloys) have complex and unpredictable composition. Algorithms that can be extended for multiphase segmentation of images of these materials are relatively few and very human-intensive. Challenges lie in designing algorithms that are context free, can function with less training data, and can handle the unpredictability of material composition. Semisupervised algorithms have shown success in classification in situations characterized by limited training data; they use unlabeled data in addition to labeled data to produce classification. The segmentation obtained can be more accurate than fully supervised learning approaches. This work proposes using a semisupervised clustering algorithm named Continuous Iterative Guided Spectral Class Rejection (CIGSCR) toward multiphase segmentation of digital scans of materials. CIGSCR harnesses spectral cohesion, splitting the intensity histogram of the input image down into clusters. This splitting provides the foundation for classification strategies that can be implemented as postprocessing steps to get the final segmentation. One classification strategy is presented. Micro-computed tomography scans of rocks are used to present the results. It is demonstrated that CIGSCR successfully enables distinguishing features up to the uniqueness of grayscale values, and extracting features present in full image stacks (3D), including features not presented in the training data. Results including instances of success and limitations are presented. Scalability to data sizes
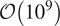 $ \mathcal{O}\left({10}^9\right) $ voxels is briefly discussed.
$ \mathcal{O}\left({10}^9\right) $ voxels is briefly discussed.
Monotonicity in undirected networks
-
- Journal:
- Network Science / Volume 11 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 02 February 2023, pp. 351-373
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Graph transformation in engineering design: an overview of the last decade
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Preface for the special issue in homage to Martin Hofmann Part 2
-
- Journal:
- Mathematical Structures in Computer Science / Volume 32 / Issue 6 / June 2022
- Published online by Cambridge University Press:
- 02 February 2023, pp. 682-684
-
- Article
-
- You have access
- HTML
- Export citation
NLP startup funding in 2022
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 1 / January 2023
- Published online by Cambridge University Press:
- 31 January 2023, pp. 162-176
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Editorial: Socially engaged sound practices, part 2
-
- Journal:
- Organised Sound / Volume 28 / Issue 1 / April 2023
- Published online by Cambridge University Press:
- 30 January 2023, pp. 1-2
- Print publication:
- April 2023
-
- Article
-
- You have access
- HTML
- Export citation
