Refine search
Actions for selected content:
48202 results in Computer Science
ROB volume 41 issue 2 Cover and Front matter
-
- Article
-
- You have access
- Export citation
Deep prior in variational assimilation to estimate an ocean circulation without explicit regularization
- Part of
-
- Journal:
- Environmental Data Science / Volume 2 / 2023
- Published online by Cambridge University Press:
- 11 January 2023, e2
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Interpretation of the electric vehicle operating point in real time
-
- Journal:
- Experimental Results / Volume 4 / 2023
- Published online by Cambridge University Press:
- 11 January 2023, e3
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ROB volume 41 issue 2 Cover and Back matter
-
- Article
-
- You have access
- Export citation
Z property for the shuffling calculus
-
- Journal:
- Mathematical Structures in Computer Science / Volume 32 / Issue 7 / August 2022
- Published online by Cambridge University Press:
- 10 January 2023, pp. 1015-1027
-
- Article
- Export citation
Democratizing electricity distribution network analysis
-
- Journal:
- Data-Centric Engineering / Volume 4 / 2023
- Published online by Cambridge University Press:
- 10 January 2023, e3
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Long-term stability and generalization of observationally-constrained stochastic data-driven models for geophysical turbulence
- Part of
-
- Journal:
- Environmental Data Science / Volume 2 / 2023
- Published online by Cambridge University Press:
- 10 January 2023, e1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Option pricing under a double-exponential jump-diffusion model with varying severity of jumps
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 10 January 2023, pp. 39-64
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Sine Wave in Music and Sound Art: A typology of artistic approaches
-
- Journal:
- Organised Sound / Volume 28 / Issue 1 / April 2023
- Published online by Cambridge University Press:
- 10 January 2023, pp. 133-145
- Print publication:
- April 2023
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Studying open government data: Acknowledging practices and politics
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 10 January 2023, e3
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
“Hey SyRI, tell me about algorithmic accountability”: Lessons from a landmark case
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 10 January 2023, e2
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Convergence of blanket times for sequences of random walks on critical random graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 3 / May 2023
- Published online by Cambridge University Press:
- 09 January 2023, pp. 478-515
-
- Article
- Export citation
-
Under the assumption that sequences of graphs equipped with resistances, associated measures, walks and local times converge in a suitable Gromov-Hausdorff topology, we establish asymptotic bounds on the distribution of the
 $\varepsilon$-blanket times of the random walks in the sequence. The precise nature of these bounds ensures convergence of the
$\varepsilon$-blanket times of the random walks in the sequence. The precise nature of these bounds ensures convergence of the  $\varepsilon$-blanket times of the random walks if the
$\varepsilon$-blanket times of the random walks if the  $\varepsilon$-blanket time of the limiting diffusion is continuous at
$\varepsilon$-blanket time of the limiting diffusion is continuous at  $\varepsilon$ with probability 1. This result enables us to prove annealed convergence in various examples of critical random graphs, including critical Galton-Watson trees and the Erdős-Rényi random graph in the critical window. We highlight that proving continuity of the
$\varepsilon$ with probability 1. This result enables us to prove annealed convergence in various examples of critical random graphs, including critical Galton-Watson trees and the Erdős-Rényi random graph in the critical window. We highlight that proving continuity of the  $\varepsilon$-blanket time of the limiting diffusion relies on the scale invariance of a finite measure that gives rise to realizations of the limiting compact random metric space, and therefore we expect our results to hold for other examples of random graphs with a similar scale invariance property.
$\varepsilon$-blanket time of the limiting diffusion relies on the scale invariance of a finite measure that gives rise to realizations of the limiting compact random metric space, and therefore we expect our results to hold for other examples of random graphs with a similar scale invariance property.





Multi-resolution dynamic mode decomposition for damage detection in wind turbine gearboxes
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 4 / 2023
- Published online by Cambridge University Press:
- 09 January 2023, e1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Rotation in age patterns of mortality decline: statistical evidence and modeling
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 2 / April 2023
- Published online by Cambridge University Press:
- 09 January 2023, pp. 621-652
-
- Article
- Export citation
Active-learning-based nonintrusive model order reduction
-
- Journal:
- Data-Centric Engineering / Volume 4 / 2023
- Published online by Cambridge University Press:
- 09 January 2023, e2
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Off-diagonal book Ramsey numbers
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 3 / May 2023
- Published online by Cambridge University Press:
- 09 January 2023, pp. 516-545
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The book graph
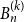 $B_n ^{(k)}$ consists of
$B_n ^{(k)}$ consists of  $n$ copies of
$n$ copies of 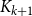 $K_{k+1}$ joined along a common
$K_{k+1}$ joined along a common 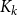 $K_k$. In the prequel to this paper, we studied the diagonal Ramsey number
$K_k$. In the prequel to this paper, we studied the diagonal Ramsey number 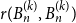 $r(B_n ^{(k)}, B_n ^{(k)})$. Here we consider the natural off-diagonal variant
$r(B_n ^{(k)}, B_n ^{(k)})$. Here we consider the natural off-diagonal variant 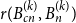 $r(B_{cn} ^{(k)}, B_n^{(k)})$ for fixed
$r(B_{cn} ^{(k)}, B_n^{(k)})$ for fixed 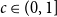 $c \in (0,1]$. In this more general setting, we show that an interesting dichotomy emerges: for very small
$c \in (0,1]$. In this more general setting, we show that an interesting dichotomy emerges: for very small  $c$, a simple
$c$, a simple 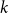 $k$-partite construction dictates the Ramsey function and all nearly-extremal colourings are close to being
$k$-partite construction dictates the Ramsey function and all nearly-extremal colourings are close to being 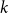 $k$-partite, while, for
$k$-partite, while, for  $c$ bounded away from
$c$ bounded away from 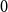 $0$, random colourings of an appropriate density are asymptotically optimal and all nearly-extremal colourings are quasirandom. Our investigations also open up a range of questions about what happens for intermediate values of
$0$, random colourings of an appropriate density are asymptotically optimal and all nearly-extremal colourings are quasirandom. Our investigations also open up a range of questions about what happens for intermediate values of  $c$.
$c$.
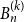

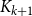
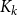
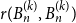
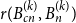
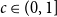

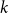
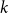

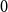

Incorporating covariate into mean and covariance function estimation of functional data under a general weighing scheme
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 09 January 2023, pp. 82-99
-
- Article
-
- You have access
- HTML
- Export citation
The forgotten preconditions for a well-functioning internet
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 09 January 2023, e1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On the dual risk model with Parisian implementation delays under a mixed dividend strategy
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 2 / April 2023
- Published online by Cambridge University Press:
- 09 January 2023, pp. 442-461
-
- Article
- Export citation
