Refine search
Actions for selected content:
48287 results in Computer Science

Regulating Cross-Border Data Flows
- Issues, Challenges and Impact
-
- Published by:
- Anthem Press
- Published online:
- 22 November 2022
- Print publication:
- 16 August 2022
Rewriting in Gray categories with applications to coherence
-
- Journal:
- Mathematical Structures in Computer Science / Volume 32 / Issue 5 / May 2022
- Published online by Cambridge University Press:
- 22 November 2022, pp. 574-647
-
- Article
- Export citation
A linear logic framework for multimodal logics
-
- Journal:
- Mathematical Structures in Computer Science / Volume 32 / Issue 9 / October 2022
- Published online by Cambridge University Press:
- 22 November 2022, pp. 1176-1204
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
One of the most fundamental properties of a proof system is analyticity, expressing the fact that a proof of a given formula F only uses subformulas of F. In sequent calculus, this property is usually proved by showing that the
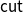 $\mathsf{cut}$ rule is admissible, i.e., the introduction of the auxiliary lemma H in the reasoning “if H follows from G and F follows from H, then F follows from G” can be eliminated. The proof of cut admissibility is usually a tedious, error-prone process through several proof transformations, thus requiring the assistance of (semi-)automatic procedures. In a previous work by Miller and Pimentel, linear logic (
$\mathsf{cut}$ rule is admissible, i.e., the introduction of the auxiliary lemma H in the reasoning “if H follows from G and F follows from H, then F follows from G” can be eliminated. The proof of cut admissibility is usually a tedious, error-prone process through several proof transformations, thus requiring the assistance of (semi-)automatic procedures. In a previous work by Miller and Pimentel, linear logic (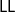 $\mathsf{LL}$) was used as a logical framework for establishing sufficient conditions for cut admissibility of object logical systems (OL). The OL’s inference rules are specified as an
$\mathsf{LL}$) was used as a logical framework for establishing sufficient conditions for cut admissibility of object logical systems (OL). The OL’s inference rules are specified as an 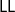 $\mathsf{LL}$ theory and an easy-to-verify criterion sufficed to establish the cut-admissibility theorem for the OL at hand. However, there are many logical systems that cannot be adequately encoded in
$\mathsf{LL}$ theory and an easy-to-verify criterion sufficed to establish the cut-admissibility theorem for the OL at hand. However, there are many logical systems that cannot be adequately encoded in 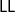 $\mathsf{LL}$, the most symptomatic cases being sequent systems for modal logics. In this paper, we use a linear-nested sequent (
$\mathsf{LL}$, the most symptomatic cases being sequent systems for modal logics. In this paper, we use a linear-nested sequent (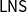 $\mathsf{LNS}$) presentation of
$\mathsf{LNS}$) presentation of 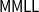 $\mathsf{MMLL}$ (a variant of LL with subexponentials), and show that it is possible to establish a cut-admissibility criterion for
$\mathsf{MMLL}$ (a variant of LL with subexponentials), and show that it is possible to establish a cut-admissibility criterion for 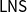 $\mathsf{LNS}$ systems for (classical or substructural) multimodal logics. We show that the same approach is suitable for handling the
$\mathsf{LNS}$ systems for (classical or substructural) multimodal logics. We show that the same approach is suitable for handling the 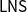 $\mathsf{LNS}$ system for intuitionistic logic.
$\mathsf{LNS}$ system for intuitionistic logic.
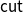
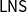
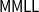
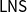
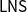
Semantic analysis of normalisation by evaluation for typed lambda calculus
-
- Journal:
- Mathematical Structures in Computer Science / Volume 32 / Issue 8 / September 2022
- Published online by Cambridge University Press:
- 22 November 2022, pp. 1028-1065
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Mean residual life order among largest order statistics arising from resilience-scale models with reduced scale parameters
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 1 / January 2023
- Published online by Cambridge University Press:
- 22 November 2022, pp. 72-85
-
- Article
- Export citation
OWL ontology evolution: understanding and unifying the complex changes
-
- Journal:
- The Knowledge Engineering Review / Volume 37 / 2022
- Published online by Cambridge University Press:
- 21 November 2022, e10
-
- Article
- Export citation
Asset allocation for a DC pension plan with minimum guarantee constraint and hidden Markov regime-switching
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 4 / October 2023
- Published online by Cambridge University Press:
- 21 November 2022, pp. 1035-1062
-
- Article
- Export citation
Factors affecting incidental L2 vocabulary acquisition and retention in a game-enhanced learning environment
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Modeling stratospheric polar vortex variation and identifying vortex extremes using explainable machine learning
- Part of
-
- Journal:
- Environmental Data Science / Volume 1 / 2022
- Published online by Cambridge University Press:
- 21 November 2022, e17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Teachers’ perceived corpus literacy and their intention to integrate corpora into classroom teaching: A survey study
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
19 - From Corporate Governance to Algorithm Governance
- from Part VI - Responsible Corporate Governance of AI Systems
-
-
- Book:
- The Cambridge Handbook of Responsible Artificial Intelligence
- Published online:
- 28 October 2022
- Print publication:
- 17 November 2022, pp 331-346
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
6 - Statistical Mechanics
- from II - Mathematical Tools of Complexity Science
-
- Book:
- Complexity Science
- Published online:
- 13 December 2022
- Print publication:
- 17 November 2022, pp 110-162
-
- Chapter
- Export citation
15 - Discriminatory AI and the Law
- from Part IV - Fairness and Nondiscrimination in AI Systems
-
-
- Book:
- The Cambridge Handbook of Responsible Artificial Intelligence
- Published online:
- 28 October 2022
- Print publication:
- 17 November 2022, pp 252-278
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
13 - Tipping Points, Transitions and Forecasting
- from II - Mathematical Tools of Complexity Science
-
- Book:
- Complexity Science
- Published online:
- 13 December 2022
- Print publication:
- 17 November 2022, pp 387-396
-
- Chapter
- Export citation
9 - Information Theory and Entropy
- from II - Mathematical Tools of Complexity Science
-
- Book:
- Complexity Science
- Published online:
- 13 December 2022
- Print publication:
- 17 November 2022, pp 230-278
-
- Chapter
- Export citation
11 - Intellectual Debt
- from Part II - Current and Future Approaches to AI Governance
-
-
- Book:
- The Cambridge Handbook of Responsible Artificial Intelligence
- Published online:
- 28 October 2022
- Print publication:
- 17 November 2022, pp 176-184
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
22 - Medical AI
- from Part VII - Responsible AI Healthcare and Neurotechnology Governance
-
-
- Book:
- The Cambridge Handbook of Responsible Artificial Intelligence
- Published online:
- 28 October 2022
- Print publication:
- 17 November 2022, pp 379-396
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
II - Mathematical Tools of Complexity Science
-
- Book:
- Complexity Science
- Published online:
- 13 December 2022
- Print publication:
- 17 November 2022, pp 87-400
-
- Chapter
- Export citation
