Refine search
Actions for selected content:
48294 results in Computer Science
16 - One Numerical Sample
- from Part III - Elements of Statistical Inference
-
- Book:
- Principles of Statistical Analysis
- Published online:
- 22 July 2022
- Print publication:
- 25 August 2022, pp 230-270
-
- Chapter
- Export citation
10 - Cue Integration in Input Performance
- from Part IV - Bayesian Cognitive Modelling
-
- Book:
- Bayesian Methods for Interaction and Design
- Published online:
- 18 August 2022
- Print publication:
- 25 August 2022, pp 287-307
-
- Chapter
- Export citation
6 - Statistical Keyboard Decoding
- from Part II - Probabilistic Interfaces and Inference of Intent
-
- Book:
- Bayesian Methods for Interaction and Design
- Published online:
- 18 August 2022
- Print publication:
- 25 August 2022, pp 188-211
-
- Chapter
- Export citation
Preface
-
- Book:
- Principles of Statistical Analysis
- Published online:
- 22 July 2022
- Print publication:
- 25 August 2022, pp xiv-xvi
-
- Chapter
- Export citation
Comparing the creamatocrit of human milk before and after long-term freezing
-
- Journal:
- Experimental Results / Volume 3 / 2022
- Published online by Cambridge University Press:
- 24 August 2022, e11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The development, and day-to-day variation, of a Military-Specific Auditory N-Back Task and Shoot-/Don’t -Shoot Task
-
- Journal:
- Experimental Results / Volume 3 / 2022
- Published online by Cambridge University Press:
- 24 August 2022, e15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Crisis as driver of digital transformation? Scottish local governments’ response to COVID-19
-
- Journal:
- Data & Policy / Volume 4 / 2022
- Published online by Cambridge University Press:
- 24 August 2022, e26
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Recognition of visual scene elements from a story text in Persian natural language
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 3 / May 2023
- Published online by Cambridge University Press:
- 24 August 2022, pp. 693-719
-
- Article
- Export citation

Multilayer Network Science
- From Cells to Societies
-
- Published online:
- 23 August 2022
- Print publication:
- 15 September 2022
-
- Element
- Export citation
Positive Dependency Graphs Revisited
-
- Journal:
- Theory and Practice of Logic Programming / Volume 23 / Issue 5 / September 2023
- Published online by Cambridge University Press:
- 23 August 2022, pp. 1128-1137
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Motion design and visual communication in the era of ‘diffuse design’ paradigm: analysis and evaluation of a didactic experiment
-
- Journal:
- Design Science / Volume 8 / 2022
- Published online by Cambridge University Press:
- 23 August 2022, e22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Trajectory design via unsupervised probabilistic learning on optimal manifolds
-
- Journal:
- Data-Centric Engineering / Volume 3 / 2022
- Published online by Cambridge University Press:
- 23 August 2022, e26
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Idea selection in design teams: a computational framework and insights in the presence of influencers
-
- Journal:
- Design Science / Volume 8 / 2022
- Published online by Cambridge University Press:
- 23 August 2022, e23
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Quantifying the impact of context on the quality of manual hate speech annotation
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 6 / November 2023
- Published online by Cambridge University Press:
- 22 August 2022, pp. 1481-1494
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Extracting functional programs from Coq, in Coq
-
- Journal:
- Journal of Functional Programming / Volume 32 / 2022
- Published online by Cambridge University Press:
- 22 August 2022, e11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We implement extraction of Coq programs to functional languages based on MetaCoq’s certified erasure. We extend the MetaCoq erasure output language with typing information and use it as an intermediate representation, which we call
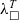 ${\lambda^T_\square}$. We complement the extraction functionality with a full pipeline that includes several standard transformations (e.g. eta-expansion and inlining) implemented in a proof-generating manner along with a verified optimisation pass removing unused arguments. We prove the pass correct wrt. a conventional call-by-value operational semantics of functional languages. From the optimised
${\lambda^T_\square}$. We complement the extraction functionality with a full pipeline that includes several standard transformations (e.g. eta-expansion and inlining) implemented in a proof-generating manner along with a verified optimisation pass removing unused arguments. We prove the pass correct wrt. a conventional call-by-value operational semantics of functional languages. From the optimised 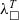 ${\lambda^T_\square}$ representation, we obtain code in two functional smart contract languages, Liquidity and CameLIGO, the functional language Elm, and a subset of the multi-paradigm language for systems programming Rust. Rust is currently gaining popularity as a language for smart contracts, and we demonstrate how our extraction can be used to extract smart contract code for the Concordium network. The development is done in the context of the ConCert framework that enables smart contract verification. We contribute with two verified real-world smart contracts (boardroom voting and escrow), which we use, among other examples, to exemplify the applicability of the pipeline. In addition, we develop a verified web application and extract it to fully functional Elm code. In total, this gives us a way to write dependently typed programs in Coq, verify, and then extract them to several target languages while retaining a small trusted computing base of only MetaCoq and the pretty-printers into these languages.
${\lambda^T_\square}$ representation, we obtain code in two functional smart contract languages, Liquidity and CameLIGO, the functional language Elm, and a subset of the multi-paradigm language for systems programming Rust. Rust is currently gaining popularity as a language for smart contracts, and we demonstrate how our extraction can be used to extract smart contract code for the Concordium network. The development is done in the context of the ConCert framework that enables smart contract verification. We contribute with two verified real-world smart contracts (boardroom voting and escrow), which we use, among other examples, to exemplify the applicability of the pipeline. In addition, we develop a verified web application and extract it to fully functional Elm code. In total, this gives us a way to write dependently typed programs in Coq, verify, and then extract them to several target languages while retaining a small trusted computing base of only MetaCoq and the pretty-printers into these languages.

Computational Thinking for Life Scientists
-
- Published online:
- 19 August 2022
- Print publication:
- 08 September 2022

Bayesian Methods for Interaction and Design
-
- Published online:
- 18 August 2022
- Print publication:
- 25 August 2022
Part III - Generative Models
-
- Book:
- The Science of Deep Learning
- Published online:
- 23 September 2022
- Print publication:
- 18 August 2022, pp 151-152
-
- Chapter
- Export citation
