Refine search
Actions for selected content:
26076 results in Abstract analysis
Shape sensitivity of the Hardy constant involving the distance from a boundary submanifold
- Part of
-
- Journal:
- Proceedings of the Royal Society of Edinburgh. Section A: Mathematics / Volume 154 / Issue 2 / April 2024
- Published online by Cambridge University Press:
- 22 February 2023, pp. 408-423
- Print publication:
- April 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Extending linear growth functionals to functions of bounded fractional variation
- Part of
-
- Journal:
- Proceedings of the Royal Society of Edinburgh. Section A: Mathematics / Volume 154 / Issue 1 / February 2024
- Published online by Cambridge University Press:
- 21 February 2023, pp. 304-327
- Print publication:
- February 2024
-
- Article
- Export citation
Poset Ramsey numbers: large Boolean lattice versus a fixed poset
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 4 / July 2023
- Published online by Cambridge University Press:
- 17 February 2023, pp. 638-653
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Given partially ordered sets (posets)
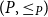 $(P, \leq _P\!)$ and
$(P, \leq _P\!)$ and 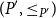 $(P^{\prime}, \leq _{P^{\prime}}\!)$, we say that
$(P^{\prime}, \leq _{P^{\prime}}\!)$, we say that 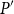 $P^{\prime}$ contains a copy of
$P^{\prime}$ contains a copy of 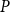 $P$ if for some injective function
$P$ if for some injective function 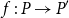 $f\,:\, P\rightarrow P^{\prime}$ and for any
$f\,:\, P\rightarrow P^{\prime}$ and for any 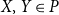 $X, Y\in P$,
$X, Y\in P$, 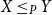 $X\leq _P Y$ if and only if
$X\leq _P Y$ if and only if 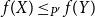 $f(X)\leq _{P^{\prime}} f(Y)$. For any posets
$f(X)\leq _{P^{\prime}} f(Y)$. For any posets 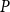 $P$ and
$P$ and 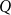 $Q$, the poset Ramsey number
$Q$, the poset Ramsey number 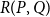 $R(P,Q)$ is the least positive integer
$R(P,Q)$ is the least positive integer 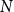 $N$ such that no matter how the elements of an
$N$ such that no matter how the elements of an 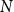 $N$-dimensional Boolean lattice are coloured in blue and red, there is either a copy of
$N$-dimensional Boolean lattice are coloured in blue and red, there is either a copy of 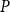 $P$ with all blue elements or a copy of
$P$ with all blue elements or a copy of 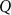 $Q$ with all red elements. We focus on a poset Ramsey number
$Q$ with all red elements. We focus on a poset Ramsey number 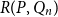 $R(P, Q_n)$ for a fixed poset
$R(P, Q_n)$ for a fixed poset 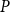 $P$ and an
$P$ and an  $n$-dimensional Boolean lattice
$n$-dimensional Boolean lattice 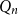 $Q_n$, as
$Q_n$, as  $n$ grows large. We show a sharp jump in behaviour of this number as a function of
$n$ grows large. We show a sharp jump in behaviour of this number as a function of  $n$ depending on whether or not
$n$ depending on whether or not 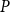 $P$ contains a copy of either a poset
$P$ contains a copy of either a poset 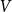 $V$, that is a poset on elements
$V$, that is a poset on elements 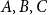 $A, B, C$ such that
$A, B, C$ such that 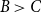 $B\gt C$,
$B\gt C$, 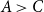 $A\gt C$, and
$A\gt C$, and 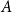 $A$ and
$A$ and 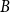 $B$ incomparable, or a poset
$B$ incomparable, or a poset 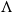 $\Lambda$, its symmetric counterpart. Specifically, we prove that if
$\Lambda$, its symmetric counterpart. Specifically, we prove that if 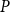 $P$ contains a copy of
$P$ contains a copy of 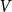 $V$ or
$V$ or 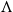 $\Lambda$ then
$\Lambda$ then 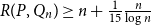 $R(P, Q_n) \geq n +\frac{1}{15} \frac{n}{\log n}$. Otherwise
$R(P, Q_n) \geq n +\frac{1}{15} \frac{n}{\log n}$. Otherwise 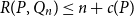 $R(P, Q_n) \leq n + c(P)$ for a constant
$R(P, Q_n) \leq n + c(P)$ for a constant 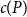 $c(P)$. This gives the first non-marginal improvement of a lower bound on poset Ramsey numbers and as a consequence gives
$c(P)$. This gives the first non-marginal improvement of a lower bound on poset Ramsey numbers and as a consequence gives 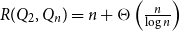 $R(Q_2, Q_n) = n + \Theta \left(\frac{n}{\log n}\right)$.
$R(Q_2, Q_n) = n + \Theta \left(\frac{n}{\log n}\right)$.
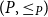
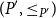
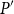
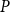
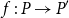
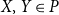
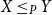
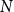
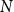
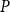
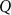
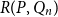
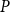

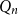


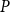
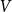
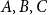
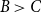
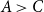
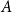
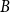
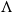
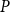
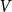
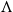
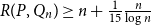
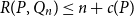
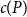
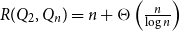
Asymptotic profiles for positive solutions of diffusive logistic equations
- Part of
-
- Journal:
- Proceedings of the Royal Society of Edinburgh. Section A: Mathematics / Volume 154 / Issue 1 / February 2024
- Published online by Cambridge University Press:
- 15 February 2023, pp. 273-284
- Print publication:
- February 2024
-
- Article
- Export citation
On stability for generalized linear differential equations and applications to impulsive systems
- Part of
-
- Journal:
- Proceedings of the Royal Society of Edinburgh. Section A: Mathematics / Volume 154 / Issue 2 / April 2024
- Published online by Cambridge University Press:
- 15 February 2023, pp. 381-407
- Print publication:
- April 2024
-
- Article
- Export citation
Multiple random walks on graphs: mixing few to cover many
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 4 / July 2023
- Published online by Cambridge University Press:
- 15 February 2023, pp. 594-637
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Random walks on graphs are an essential primitive for many randomised algorithms and stochastic processes. It is natural to ask how much can be gained by running
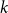 $k$ multiple random walks independently and in parallel. Although the cover time of multiple walks has been investigated for many natural networks, the problem of finding a general characterisation of multiple cover times for worst-case start vertices (posed by Alon, Avin, Koucký, Kozma, Lotker and Tuttle in 2008) remains an open problem. First, we improve and tighten various bounds on the stationary cover time when
$k$ multiple random walks independently and in parallel. Although the cover time of multiple walks has been investigated for many natural networks, the problem of finding a general characterisation of multiple cover times for worst-case start vertices (posed by Alon, Avin, Koucký, Kozma, Lotker and Tuttle in 2008) remains an open problem. First, we improve and tighten various bounds on the stationary cover time when 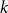 $k$ random walks start from vertices sampled from the stationary distribution. For example, we prove an unconditional lower bound of
$k$ random walks start from vertices sampled from the stationary distribution. For example, we prove an unconditional lower bound of 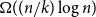 $\Omega ((n/k) \log n)$ on the stationary cover time, holding for any
$\Omega ((n/k) \log n)$ on the stationary cover time, holding for any  $n$-vertex graph
$n$-vertex graph 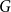 $G$ and any
$G$ and any 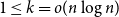 $1 \leq k =o(n\log n )$. Secondly, we establish the stationary cover times of multiple walks on several fundamental networks up to constant factors. Thirdly, we present a framework characterising worst-case cover times in terms of stationary cover times and a novel, relaxed notion of mixing time for multiple walks called the partial mixing time. Roughly speaking, the partial mixing time only requires a specific portion of all random walks to be mixed. Using these new concepts, we can establish (or recover) the worst-case cover times for many networks including expanders, preferential attachment graphs, grids, binary trees and hypercubes.
$1 \leq k =o(n\log n )$. Secondly, we establish the stationary cover times of multiple walks on several fundamental networks up to constant factors. Thirdly, we present a framework characterising worst-case cover times in terms of stationary cover times and a novel, relaxed notion of mixing time for multiple walks called the partial mixing time. Roughly speaking, the partial mixing time only requires a specific portion of all random walks to be mixed. Using these new concepts, we can establish (or recover) the worst-case cover times for many networks including expanders, preferential attachment graphs, grids, binary trees and hypercubes.
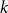
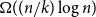

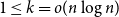
The existence of unbounded solutions of asymmetric oscillations in the degenerate resonant case
-
- Journal:
- Proceedings of the Royal Society of Edinburgh. Section A: Mathematics / Volume 154 / Issue 1 / February 2024
- Published online by Cambridge University Press:
- 15 February 2023, pp. 285-303
- Print publication:
- February 2024
-
- Article
- Export citation
Random feedback shift registers and the limit distribution for largest cycle lengths
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 4 / July 2023
- Published online by Cambridge University Press:
- 14 February 2023, pp. 559-593
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
For a random binary noncoalescing feedback shift register of width
 $n$, with all
$n$, with all 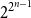 $2^{2^{n-1}}$ possible feedback functions
$2^{2^{n-1}}$ possible feedback functions 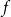 $f$ equally likely, the process of long cycle lengths, scaled by dividing by
$f$ equally likely, the process of long cycle lengths, scaled by dividing by 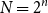 $N=2^n$, converges in distribution to the same Poisson–Dirichlet limit as holds for random permutations in
$N=2^n$, converges in distribution to the same Poisson–Dirichlet limit as holds for random permutations in 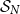 $\mathcal{S}_N$, with all
$\mathcal{S}_N$, with all 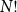 $N!$ possible permutations equally likely. Such behaviour was conjectured by Golomb, Welch and Goldstein in 1959.
$N!$ possible permutations equally likely. Such behaviour was conjectured by Golomb, Welch and Goldstein in 1959.

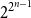
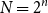
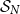
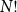
Subsymmetric exchanged braids and the Burau matrix
- Part of
-
- Journal:
- Proceedings of the Royal Society of Edinburgh. Section A: Mathematics / Volume 154 / Issue 1 / February 2024
- Published online by Cambridge University Press:
- 10 February 2023, pp. 154-187
- Print publication:
- February 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A new inner approach for differential subordinations
- Part of
-
- Journal:
- Proceedings of the Royal Society of Edinburgh. Section A: Mathematics / Volume 154 / Issue 1 / February 2024
- Published online by Cambridge University Press:
- 10 February 2023, pp. 259-272
- Print publication:
- February 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In this paper we introduce and examine the differential subordination of the form
\[ p(z)+zp'(z)\varphi(p(z),zp'(z))\prec h(z),\quad z\in\mathbb{D}:=\{z\in\mathbb{C}:|z|<1\}, \]where $h$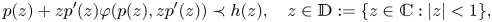
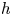 is a convex univalent function with $0\in h(\mathbb {D}).$
is a convex univalent function with $0\in h(\mathbb {D}).$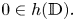 The proof of the main result is based on the original lemma for convex univalent functions and offers a new approach in the theory. In particular, the above differential subordination leads to generalizations of the well-known Briot-Bouquet differential subordination. Appropriate applications among others related to the differential subordination of harmonic mean are demonstrated. Related problems concerning differential equations are indicated.
The proof of the main result is based on the original lemma for convex univalent functions and offers a new approach in the theory. In particular, the above differential subordination leads to generalizations of the well-known Briot-Bouquet differential subordination. Appropriate applications among others related to the differential subordination of harmonic mean are demonstrated. Related problems concerning differential equations are indicated.
Liouville property and quasi-isometries on negatively curved Riemannian surfaces
- Part of
-
- Journal:
- Proceedings of the Royal Society of Edinburgh. Section A: Mathematics / Volume 154 / Issue 1 / February 2024
- Published online by Cambridge University Press:
- 10 February 2023, pp. 131-153
- Print publication:
- February 2024
-
- Article
- Export citation
-
Kanai proved powerful results on the stability under quasi-isometries of numerous global properties (including Liouville property) between Riemannian manifolds of bounded geometry. Since his work focuses more on the generality of the spaces considered than on the two-dimensional geometry, Kanai's hypotheses in many cases are not satisfied in the context of Riemann surfaces endowed with the Poincaré metric. In this work we fill that gap for the Liouville property, by proving its stability by quasi-isometries for every Riemann surface (and even Riemannian surfaces with pinched negative curvature). Also, a key result characterizes Riemannian surfaces which are quasi-isometric to $\mathbb {R}$
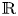 .
.
Girth, magnitude homology and phase transition of diagonality
- Part of
-
- Journal:
- Proceedings of the Royal Society of Edinburgh. Section A: Mathematics / Volume 154 / Issue 1 / February 2024
- Published online by Cambridge University Press:
- 09 February 2023, pp. 221-247
- Print publication:
- February 2024
-
- Article
- Export citation
Morse theory of Bestvina–Brady type for posets and matchings
- Part of
-
- Journal:
- Proceedings of the Royal Society of Edinburgh. Section A: Mathematics / Volume 154 / Issue 1 / February 2024
- Published online by Cambridge University Press:
- 09 February 2023, pp. 209-220
- Print publication:
- February 2024
-
- Article
- Export citation
-
We introduce a Morse theory for posets of Bestvina–Brady type combining matchings and height functions. This theory generalizes Forman's discrete Morse theory for regular CW-complexes and extends previous results on Morse theory for $h$
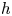 -regular posets to all finite posets. We also develop a relative version of Morse theory which allows us to compare the topology of a poset with that of a given subposet.
-regular posets to all finite posets. We also develop a relative version of Morse theory which allows us to compare the topology of a poset with that of a given subposet.
Cyclicity of rigid centres on centre manifolds of three-dimensional systems
- Part of
-
- Journal:
- Proceedings of the Royal Society of Edinburgh. Section A: Mathematics / Volume 154 / Issue 1 / February 2024
- Published online by Cambridge University Press:
- 09 February 2023, pp. 188-200
- Print publication:
- February 2024
-
- Article
- Export citation
A note on energy equality for the fractional Navier-Stokes equations
- Part of
-
- Journal:
- Proceedings of the Royal Society of Edinburgh. Section A: Mathematics / Volume 154 / Issue 1 / February 2024
- Published online by Cambridge University Press:
- 03 February 2023, pp. 201-208
- Print publication:
- February 2024
-
- Article
- Export citation
Bipartite-ness under smooth conditions
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 4 / July 2023
- Published online by Cambridge University Press:
- 03 February 2023, pp. 546-558
-
- Article
- Export citation
-
Given a family
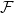 $\mathcal{F}$ of bipartite graphs, the Zarankiewicz number
$\mathcal{F}$ of bipartite graphs, the Zarankiewicz number 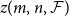 $z(m,n,\mathcal{F})$ is the maximum number of edges in an
$z(m,n,\mathcal{F})$ is the maximum number of edges in an 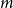 $m$ by
$m$ by  $n$ bipartite graph
$n$ bipartite graph 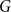 $G$ that does not contain any member of
$G$ that does not contain any member of 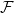 $\mathcal{F}$ as a subgraph (such
$\mathcal{F}$ as a subgraph (such 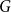 $G$ is called
$G$ is called 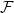 $\mathcal{F}$-free). For
$\mathcal{F}$-free). For 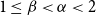 $1\leq \beta \lt \alpha \lt 2$, a family
$1\leq \beta \lt \alpha \lt 2$, a family 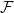 $\mathcal{F}$ of bipartite graphs is
$\mathcal{F}$ of bipartite graphs is 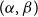 $(\alpha,\beta )$-smooth if for some
$(\alpha,\beta )$-smooth if for some 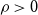 $\rho \gt 0$ and every
$\rho \gt 0$ and every 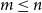 $m\leq n$,
$m\leq n$, 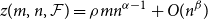 $z(m,n,\mathcal{F})=\rho m n^{\alpha -1}+O(n^\beta )$. Motivated by their work on a conjecture of Erdős and Simonovits on compactness and a classic result of Andrásfai, Erdős and Sós, Allen, Keevash, Sudakov and Verstraëte proved that for any
$z(m,n,\mathcal{F})=\rho m n^{\alpha -1}+O(n^\beta )$. Motivated by their work on a conjecture of Erdős and Simonovits on compactness and a classic result of Andrásfai, Erdős and Sós, Allen, Keevash, Sudakov and Verstraëte proved that for any 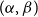 $(\alpha,\beta )$-smooth family
$(\alpha,\beta )$-smooth family 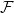 $\mathcal{F}$, there exists
$\mathcal{F}$, there exists 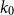 $k_0$ such that for all odd
$k_0$ such that for all odd 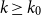 $k\geq k_0$ and sufficiently large
$k\geq k_0$ and sufficiently large  $n$, any
$n$, any  $n$-vertex
$n$-vertex 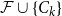 $\mathcal{F}\cup \{C_k\}$-free graph with minimum degree at least
$\mathcal{F}\cup \{C_k\}$-free graph with minimum degree at least 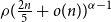 $\rho (\frac{2n}{5}+o(n))^{\alpha -1}$ is bipartite. In this paper, we strengthen their result by showing that for every real
$\rho (\frac{2n}{5}+o(n))^{\alpha -1}$ is bipartite. In this paper, we strengthen their result by showing that for every real 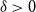 $\delta \gt 0$, there exists
$\delta \gt 0$, there exists 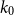 $k_0$ such that for all odd
$k_0$ such that for all odd 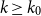 $k\geq k_0$ and sufficiently large
$k\geq k_0$ and sufficiently large  $n$, any
$n$, any  $n$-vertex
$n$-vertex 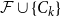 $\mathcal{F}\cup \{C_k\}$-free graph with minimum degree at least
$\mathcal{F}\cup \{C_k\}$-free graph with minimum degree at least 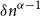 $\delta n^{\alpha -1}$ is bipartite. Furthermore, our result holds under a more relaxed notion of smoothness, which include the families
$\delta n^{\alpha -1}$ is bipartite. Furthermore, our result holds under a more relaxed notion of smoothness, which include the families 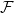 $\mathcal{F}$ consisting of the single graph
$\mathcal{F}$ consisting of the single graph 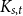 $K_{s,t}$ when
$K_{s,t}$ when 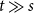 $t\gg s$. We also prove an analogous result for
$t\gg s$. We also prove an analogous result for 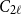 $C_{2\ell }$-free graphs for every
$C_{2\ell }$-free graphs for every 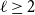 $\ell \geq 2$, which complements a result of Keevash, Sudakov and Verstraëte.
$\ell \geq 2$, which complements a result of Keevash, Sudakov and Verstraëte.
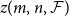
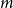

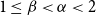
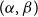
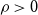
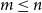
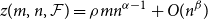
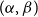
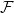
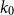
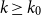


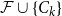
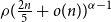
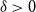
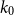
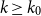


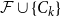
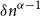
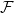
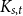
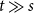
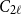
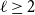
On the Hilbert scheme of the moduli space of torsion-free sheaves on surfaces
- Part of
-
- Journal:
- Glasgow Mathematical Journal / Volume 65 / Issue 2 / May 2023
- Published online by Cambridge University Press:
- 02 February 2023, pp. 414-429
-
- Article
- Export citation
-
The aim of this paper is to determine a bound of the dimension of an irreducible component of the Hilbert scheme of the moduli space of torsion-free sheaves on surfaces. Let X be a nonsingular irreducible complex surface, and let E be a vector bundle of rank n on X. We use the m-elementary transformation of E at a point
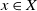 $x \in X$ to show that there exists an embedding from the Grassmannian variety
$x \in X$ to show that there exists an embedding from the Grassmannian variety 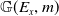 $\mathbb{G}(E_x,m)$ into the moduli space of torsion-free sheaves
$\mathbb{G}(E_x,m)$ into the moduli space of torsion-free sheaves 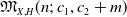 $\mathfrak{M}_{X,H}(n;\,c_1,c_2+m)$ which induces an injective morphism from
$\mathfrak{M}_{X,H}(n;\,c_1,c_2+m)$ which induces an injective morphism from 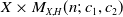 $X \times M_{X,H}(n;\,c_1,c_2)$ to
$X \times M_{X,H}(n;\,c_1,c_2)$ to 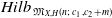 $Hilb_{\, \mathfrak{M}_{X,H}(n;\,c_1,c_2+m)}$.
$Hilb_{\, \mathfrak{M}_{X,H}(n;\,c_1,c_2+m)}$.
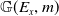
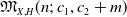
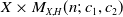
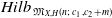
Constrained exact boundary controllability of a semilinear model for pipeline gas flow
- Part of
-
- Journal:
- European Journal of Applied Mathematics / Volume 34 / Issue 3 / June 2023
- Published online by Cambridge University Press:
- 01 February 2023, pp. 532-553
-
- Article
- Export citation
PEM series 2 volume 65 issue 4 Cover and Back matter
-
- Journal:
- Proceedings of the Edinburgh Mathematical Society / Volume 65 / Issue 4 / November 2022
- Published online by Cambridge University Press:
- 01 February 2023, pp. b1-b2
-
- Article
-
- You have access
- Export citation
PRM volume 153 issue 1 Cover and Front matter
-
- Journal:
- Proceedings of the Royal Society of Edinburgh. Section A: Mathematics / Volume 153 / Issue 1 / February 2023
- Published online by Cambridge University Press:
- 10 February 2023, pp. f1-f2
- Print publication:
- February 2023
-
- Article
-
- You have access
- Export citation
