Refine search
Actions for selected content:
26077 results in Abstract analysis
A Cauchy problem for the Tartar equation
-
- Journal:
- Proceedings of the Royal Society of Edinburgh. Section A: Mathematics / Volume 132 / Issue 2 / April 2002
- Published online by Cambridge University Press:
- 12 July 2007, pp. 395-418
- Print publication:
- April 2002
-
- Article
- Export citation
-
In order to study weak limits of quadratic expressions of oscillatory solutions of partial differential equations, there was proposed a construction of H-measures defined on the space of positions and frequencies. The present paper is devoted to the investigation of the Tartar equation
 which describes the evolution of the H-measure μt associated with a sequence of oscillatory solutions of the linear transport equation
which describes the evolution of the H-measure μt associated with a sequence of oscillatory solutions of the linear transport equation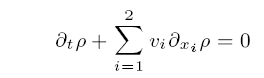 in cases when a given solenoidal velocity field v(x, t) is sufficiently smooth. Here, (t, x, y) ∈ (0, T) × Ω × S1, 0 < T < +∞, Ω is a bounded open subset of R2 and S1 is the unit circle in R2, given coefficients Yij = Yij(y) are infinitely smooth.
in cases when a given solenoidal velocity field v(x, t) is sufficiently smooth. Here, (t, x, y) ∈ (0, T) × Ω × S1, 0 < T < +∞, Ω is a bounded open subset of R2 and S1 is the unit circle in R2, given coefficients Yij = Yij(y) are infinitely smooth.Assuming that v belongs to
, we establish the well posedness of Cauchy problem for the Tartar equation in the same measure class as the H-measures are in. For this purpose, we develop and use an extension of the theory of Lagrange coordinates for a case of non-smooth solenoidal velocity fields.

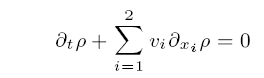
Consequences of the connection formulae for Sturm-Liouville spectral functions
-
- Journal:
- Proceedings of the Royal Society of Edinburgh. Section A: Mathematics / Volume 132 / Issue 2 / April 2002
- Published online by Cambridge University Press:
- 12 July 2007, pp. 387-393
- Print publication:
- April 2002
-
- Article
- Export citation
-
For a special case of the Sturm-Liouville equation, −(py′)′ + qy = λwy on [0, ∞) with the initial condition y(0) cos α + p(0)y′(0) sin α = 0, α ∈ [0, π), it is shown that, given the spectral derivative
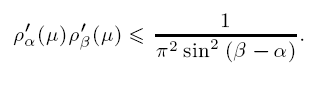
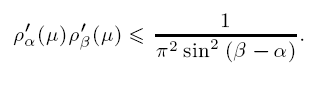
Perturbation of domain: ordinary differential equations
-
- Journal:
- Proceedings of the Royal Society of Edinburgh. Section A: Mathematics / Volume 132 / Issue 2 / April 2002
- Published online by Cambridge University Press:
- 12 July 2007, pp. 379-386
- Print publication:
- April 2002
-
- Article
- Export citation
PROPERLY EMBEDDED MINIMAL ANNULI BOUNDED BY A CONVEX CURVE
-
- Journal:
- Journal of the Institute of Mathematics of Jussieu / Volume 1 / Issue 2 / April 2002
- Published online by Cambridge University Press:
- 24 January 2003, pp. 293-305
- Print publication:
- April 2002
-
- Article
- Export citation
Existence of a weak solution for the semigeostrophic equation with integrable initial data
-
- Journal:
- Proceedings of the Royal Society of Edinburgh. Section A: Mathematics / Volume 132 / Issue 2 / April 2002
- Published online by Cambridge University Press:
- 12 July 2007, pp. 329-339
- Print publication:
- April 2002
-
- Article
- Export citation
-
In this article we present a proof of existence of a weak solution for the semigeostrophic system of equations, formulated as an active scalar transport equation with Monge-Ampère coupling, with initial data in
NORI’S CONNECTIVITY THEOREM AND HIGHER CHOW GROUPS
-
- Journal:
- Journal of the Institute of Mathematics of Jussieu / Volume 1 / Issue 2 / April 2002
- Published online by Cambridge University Press:
- 24 January 2003, pp. 307-329
- Print publication:
- April 2002
-
- Article
- Export citation
A STABLE TRACE FORMULA. I. GENERAL EXPANSIONS
-
- Journal:
- Journal of the Institute of Mathematics of Jussieu / Volume 1 / Issue 2 / April 2002
- Published online by Cambridge University Press:
- 24 January 2003, pp. 175-277
- Print publication:
- April 2002
-
- Article
- Export citation
A derivation theory for generalized Besicovitch spaces and its application for partial differential equations
-
- Journal:
- Proceedings of the Royal Society of Edinburgh. Section A: Mathematics / Volume 132 / Issue 2 / April 2002
- Published online by Cambridge University Press:
- 12 July 2007, pp. 283-315
- Print publication:
- April 2002
-
- Article
- Export citation
HYPOELLIPTICITY OF THE KOHN LAPLACIAN FOR THREE-DIMENSIONAL TUBULAR CAUCHY–RIEMANN STRUCTURES
-
- Journal:
- Journal of the Institute of Mathematics of Jussieu / Volume 1 / Issue 2 / April 2002
- Published online by Cambridge University Press:
- 24 January 2003, pp. 279-291
- Print publication:
- April 2002
-
- Article
- Export citation
Conditional persistence in logistic models via nonlinear diffusion
-
- Journal:
- Proceedings of the Royal Society of Edinburgh. Section A: Mathematics / Volume 132 / Issue 2 / April 2002
- Published online by Cambridge University Press:
- 12 July 2007, pp. 267-281
- Print publication:
- April 2002
-
- Article
- Export citation
Monotonicity of rotationally invariant convex and rank 1 convex functions
-
- Journal:
- Proceedings of the Royal Society of Edinburgh. Section A: Mathematics / Volume 132 / Issue 2 / April 2002
- Published online by Cambridge University Press:
- 12 July 2007, pp. 419-435
- Print publication:
- April 2002
-
- Article
- Export citation
Relaxation of rate-independent evolution problems
-
- Journal:
- Proceedings of the Royal Society of Edinburgh. Section A: Mathematics / Volume 132 / Issue 2 / April 2002
- Published online by Cambridge University Press:
- 12 July 2007, pp. 463-481
- Print publication:
- April 2002
-
- Article
- Export citation
On the Dirichlet problem with several volume constraints on the level sets
-
- Journal:
- Proceedings of the Royal Society of Edinburgh. Section A: Mathematics / Volume 132 / Issue 2 / April 2002
- Published online by Cambridge University Press:
- 12 July 2007, pp. 437-461
- Print publication:
- April 2002
-
- Article
- Export citation
-
We consider minimization problems involving the Dirichlet integral under an arbitrary number of volume constraints on the level sets and a generalized boundary condition. More precisely, given a bounded open domain Ω ⊂ Rn with smooth boundary, we study the problem of minimizing ∫Ω |∇u|2 among all those functions u ∈ H1 that simultaneously satisfy n-dimensional measure constraints on the level sets of the kind |{u = li}| = αi, i = 1,…, k, and a generalized boundary condition u ∈ K. Here, K is a closed convex subset of H1 such that
By a penalization approach, we prove the existence of minimizers and their Hölder continuity, generalizing previous results that are not applicable when a boundary condition is prescribed.
Finally, in the case of just two volume constraints, we investigate the Γ-convergence of the above (rescaled) functionals when the total measure of the two prescribed level sets tends to saturate the whole domain Ω. It turns out that the resulting Γ-limit functional can be split into two distinct parts: the perimeter of the interface due to the Dirichlet energy that concentrates along the jump, and a boundary integral term due to the constraint u ∈ K. In the particular case where K = H1 (i.e. when no boundary condition is prescribed), the boundary term vanishes and we recover a previous result due to Ambrosio et al.
Asymptotic behaviour of solutions of the hydrodynamic model of semiconductors
-
- Journal:
- Proceedings of the Royal Society of Edinburgh. Section A: Mathematics / Volume 132 / Issue 2 / April 2002
- Published online by Cambridge University Press:
- 12 July 2007, pp. 359-378
- Print publication:
- April 2002
-
- Article
- Export citation
Convergence of diffusive BGK approximations for nonlinear strongly parabolic systems
-
- Journal:
- Proceedings of the Royal Society of Edinburgh. Section A: Mathematics / Volume 132 / Issue 2 / April 2002
- Published online by Cambridge University Press:
- 12 July 2007, pp. 341-358
- Print publication:
- April 2002
-
- Article
- Export citation
On subhereditary radicals and reduced rings
-
- Journal:
- Proceedings of the Royal Society of Edinburgh. Section A: Mathematics / Volume 132 / Issue 2 / April 2002
- Published online by Cambridge University Press:
- 12 July 2007, pp. 255-266
- Print publication:
- April 2002
-
- Article
- Export citation
Mappings on Decomposable Combinatorial Structures: Analytic Approach
-
- Journal:
- Combinatorics, Probability and Computing / Volume 11 / Issue 1 / January 2002
- Published online by Cambridge University Press:
- 14 February 2002, pp. 61-78
-
- Article
- Export citation
The Chromatic Number of Graph Powers
-
- Journal:
- Combinatorics, Probability and Computing / Volume 11 / Issue 1 / January 2002
- Published online by Cambridge University Press:
- 14 February 2002, pp. 1-10
-
- Article
- Export citation
Information Loss in Riffle Shuffling
-
- Journal:
- Combinatorics, Probability and Computing / Volume 11 / Issue 1 / January 2002
- Published online by Cambridge University Press:
- 14 February 2002, pp. 79-95
-
- Article
- Export citation
On the Circuit Cover Problemfor Mixed Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 11 / Issue 1 / January 2002
- Published online by Cambridge University Press:
- 14 February 2002, pp. 43-59
-
- Article
- Export citation
