This work is motivated by the question of whether there are spaces X for which the Farber–Grant symmetric topological complexity TCS(X) differs from the Basabe–González–Rudyak–Tamaki symmetric topological complexity TCΣ(X). For a projective space  ${\open R}\hbox{P}^m$, it is known that
${\open R}\hbox{P}^m$, it is known that 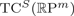 $\hbox{TC}^S ({\open R}\hbox{P}^{m})$ captures, with a few potential exceptional cases, the Euclidean embedding dimension of
$\hbox{TC}^S ({\open R}\hbox{P}^{m})$ captures, with a few potential exceptional cases, the Euclidean embedding dimension of  ${\open R}\hbox{P}^{m}$. We now show that, for all m≥1,
${\open R}\hbox{P}^{m}$. We now show that, for all m≥1, 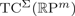 $\hbox{TC}^{\Sigma}({\open R}\hbox{P}^{m})$ is characterized as the smallest positive integer n for which there is a symmetric
$\hbox{TC}^{\Sigma}({\open R}\hbox{P}^{m})$ is characterized as the smallest positive integer n for which there is a symmetric 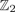 ${\open Z}_{2}$-biequivariant map Sm×Sm→Sn with a ‘monoidal’ behaviour on the diagonal. This result thus lies at the core of the efforts in the 1970s to characterize the embedding dimension of real projective spaces in terms of the existence of symmetric axial maps. Together with Nakaoka's description of the cohomology ring of symmetric squares, this allows us to compute both TC numbers in the case of
${\open Z}_{2}$-biequivariant map Sm×Sm→Sn with a ‘monoidal’ behaviour on the diagonal. This result thus lies at the core of the efforts in the 1970s to characterize the embedding dimension of real projective spaces in terms of the existence of symmetric axial maps. Together with Nakaoka's description of the cohomology ring of symmetric squares, this allows us to compute both TC numbers in the case of 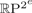 ${\open R}\hbox{P}^{2^{e}}$ for e≥1. In particular, this leaves the torus S1×S1 as the only closed surface whose symmetric (symmetrized) TCS (TCΣ) invariant is currently unknown.
${\open R}\hbox{P}^{2^{e}}$ for e≥1. In particular, this leaves the torus S1×S1 as the only closed surface whose symmetric (symmetrized) TCS (TCΣ) invariant is currently unknown.
In this paper, we present a heuristic algorithm for solving exact, as well as approximate, shortest vector and closest vector problems on lattices. The algorithm can be seen as a modified sieving algorithm for which the vectors of the intermediate sets lie in overlattices or translated cosets of overlattices. The key idea is hence no longer to work with a single lattice but to move the problems around in a tower of related lattices. We initiate the algorithm by sampling very short vectors in an overlattice of the original lattice that admits a quasi-orthonormal basis and hence an efficient enumeration of vectors of bounded norm. Taking sums of vectors in the sample, we construct short vectors in the next lattice. Finally, we obtain solution vector(s) in the initial lattice as a sum of vectors of an overlattice. The complexity analysis relies on the Gaussian heuristic. This heuristic is backed by experiments in low and high dimensions that closely reflect these estimates when solving hard lattice problems in the average case.
This new approach allows us to solve not only shortest vector problems, but also closest vector problems, in lattices of dimension  $\def \xmlpi #1{}\def \mathsfbi #1{\boldsymbol {\mathsf {#1}}}\let \le =\leqslant \let \leq =\leqslant \let \ge =\geqslant \let \geq =\geqslant \def \Pr {\mathit {Pr}}\def \Fr {\mathit {Fr}}\def \Rey {\mathit {Re}}n$ in time
$\def \xmlpi #1{}\def \mathsfbi #1{\boldsymbol {\mathsf {#1}}}\let \le =\leqslant \let \leq =\leqslant \let \ge =\geqslant \let \geq =\geqslant \def \Pr {\mathit {Pr}}\def \Fr {\mathit {Fr}}\def \Rey {\mathit {Re}}n$ in time 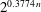 $2^{0.3774\, n}$ using memory
$2^{0.3774\, n}$ using memory 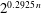 $2^{0.2925\, n}$. Moreover, the algorithm is straightforward to parallelize on most computer architectures.
$2^{0.2925\, n}$. Moreover, the algorithm is straightforward to parallelize on most computer architectures.

