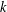Refine listing
Actions for selected content:
89 results in 94Axx
Encoding subshifts through sliding block codes
- Part of
-
- Journal:
- Ergodic Theory and Dynamical Systems / Volume 44 / Issue 6 / June 2024
- Published online by Cambridge University Press:
- 03 August 2023, pp. 1609-1628
- Print publication:
- June 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We prove a generalization of Krieger’s embedding theorem, in the spirit of zero-error information theory. Specifically, given a mixing shift of finite type X, a mixing sofic shift Y, and a surjective sliding block code
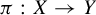 $\pi : X \to Y$, we give necessary and sufficient conditions for a subshift Z of topological entropy strictly lower than that of Y to admit an embedding
$\pi : X \to Y$, we give necessary and sufficient conditions for a subshift Z of topological entropy strictly lower than that of Y to admit an embedding 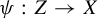 $\psi : Z \to X$ such that
$\psi : Z \to X$ such that 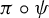 $\pi \circ \psi $ is injective.
$\pi \circ \psi $ is injective.
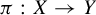
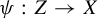
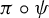
Information-theoretic convergence of extreme values to the Gumbel distribution
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 21 June 2023, pp. 244-254
- Print publication:
- March 2024
-
- Article
- Export citation
On asymptotic fairness in voting with greedy sampling
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 10 May 2023, pp. 999-1032
- Print publication:
- September 2023
-
- Article
- Export citation
Costa’s concavity inequality for dependent variables based on the multivariate Gaussian copula
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 12 April 2023, pp. 1136-1156
- Print publication:
- December 2023
-
- Article
- Export citation
A new lifetime distribution by maximizing entropy: properties and applications
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 28 February 2023, pp. 189-206
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Random feedback shift registers and the limit distribution for largest cycle lengths
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 4 / July 2023
- Published online by Cambridge University Press:
- 14 February 2023, pp. 559-593
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
For a random binary noncoalescing feedback shift register of width
 $n$, with all
$n$, with all 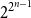 $2^{2^{n-1}}$ possible feedback functions
$2^{2^{n-1}}$ possible feedback functions 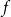 $f$ equally likely, the process of long cycle lengths, scaled by dividing by
$f$ equally likely, the process of long cycle lengths, scaled by dividing by 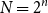 $N=2^n$, converges in distribution to the same Poisson–Dirichlet limit as holds for random permutations in
$N=2^n$, converges in distribution to the same Poisson–Dirichlet limit as holds for random permutations in 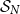 $\mathcal{S}_N$, with all
$\mathcal{S}_N$, with all 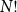 $N!$ possible permutations equally likely. Such behaviour was conjectured by Golomb, Welch and Goldstein in 1959.
$N!$ possible permutations equally likely. Such behaviour was conjectured by Golomb, Welch and Goldstein in 1959.

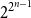
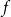
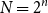
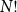
Constant rank factorisations of smooth maps, with applications to sonar
- Part of
-
- Journal:
- European Journal of Applied Mathematics / Volume 35 / Issue 1 / February 2024
- Published online by Cambridge University Press:
- 01 December 2022, pp. 1-39
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A negative binomial approximation in group testing
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 4 / October 2023
- Published online by Cambridge University Press:
- 28 October 2022, pp. 973-996
-
- Article
- Export citation
Fast mixing of a randomized shift-register Markov chain
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 02 September 2022, pp. 253-266
- Print publication:
- March 2023
-
- Article
- Export citation
-
We present a Markov chain on the n-dimensional hypercube
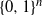 $\{0,1\}^n$ which satisfies
$\{0,1\}^n$ which satisfies 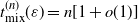 $t_{{\rm mix}}^{(n)}(\varepsilon) = n[1 + o(1)]$. This Markov chain alternates between random and deterministic moves, and we prove that the chain has a cutoff with a window of size at most
$t_{{\rm mix}}^{(n)}(\varepsilon) = n[1 + o(1)]$. This Markov chain alternates between random and deterministic moves, and we prove that the chain has a cutoff with a window of size at most 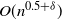 $O(n^{0.5+\delta})$, where
$O(n^{0.5+\delta})$, where 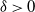 $\delta>0$. The deterministic moves correspond to a linear shift register.
$\delta>0$. The deterministic moves correspond to a linear shift register.
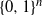
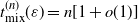
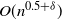
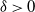
Varentropy of doubly truncated random variable
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 3 / July 2023
- Published online by Cambridge University Press:
- 08 July 2022, pp. 852-871
-
- Article
- Export citation
UNIVERSAL CODING AND PREDICTION ON ERGODIC RANDOM POINTS
- Part of
-
- Journal:
- Bulletin of Symbolic Logic / Volume 28 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 02 May 2022, pp. 387-412
- Print publication:
- September 2022
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Variational model with nonstandard growth conditions for restoration of satellite optical images using synthetic aperture radar
- Part of
-
- Journal:
- European Journal of Applied Mathematics / Volume 34 / Issue 1 / February 2023
- Published online by Cambridge University Press:
- 11 March 2022, pp. 77-105
-
- Article
-
- You have access
- HTML
- Export citation
On reconsidering entropies and divergences and their cumulative counterparts: Csiszár's, DPD's and Fisher's type cumulative and survival measures
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 1 / January 2023
- Published online by Cambridge University Press:
- 21 February 2022, pp. 294-321
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Concentration functions and entropy bounds for discrete log-concave distributions
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 31 / Issue 1 / January 2022
- Published online by Cambridge University Press:
- 27 May 2021, pp. 54-72
-
- Article
- Export citation
PROBABILISTIC STABILITY, AGM REVISION OPERATORS AND MAXIMUM ENTROPY
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 15 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 21 October 2020, pp. 553-590
- Print publication:
- September 2022
-
- Article
- Export citation
A note on the phase retrieval of holomorphic functions
- Part of
-
- Journal:
- Canadian Mathematical Bulletin / Volume 64 / Issue 4 / December 2021
- Published online by Cambridge University Press:
- 08 October 2020, pp. 779-786
- Print publication:
- December 2021
-
- Article
- Export citation
-
We prove that if f and g are holomorphic functions on an open connected domain, with the same moduli on two intersecting segments, then
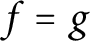 $f=g$ up to the multiplication of a unimodular constant, provided the segments make an angle that is an irrational multiple of
$f=g$ up to the multiplication of a unimodular constant, provided the segments make an angle that is an irrational multiple of 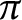 $\pi $. We also prove that if f and g are functions in the Nevanlinna class, and if
$\pi $. We also prove that if f and g are functions in the Nevanlinna class, and if 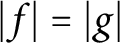 $|f|=|g|$ on the unit circle and on a circle inside the unit disc, then
$|f|=|g|$ on the unit circle and on a circle inside the unit disc, then 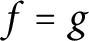 $f=g$ up to the multiplication of a unimodular constant.
$f=g$ up to the multiplication of a unimodular constant.
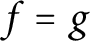
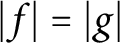
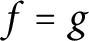
Symbolic dynamics in mean dimension theory
- Part of
-
- Journal:
- Ergodic Theory and Dynamical Systems / Volume 41 / Issue 8 / August 2021
- Published online by Cambridge University Press:
- 15 June 2020, pp. 2542-2560
- Print publication:
- August 2021
-
- Article
- Export citation
-
Furstenberg [Disjointness in ergodic theory, minimal sets, and a problem in Diophantine approximation. Math. Syst. Theory 1 (1967), 1–49] calculated the Hausdorff and Minkowski dimensions of one-sided subshifts in terms of topological entropy. We generalize this to
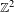 $\mathbb{Z}^{2}$-subshifts. Our generalization involves mean dimension theory. We calculate the metric mean dimension and the mean Hausdorff dimension of
$\mathbb{Z}^{2}$-subshifts. Our generalization involves mean dimension theory. We calculate the metric mean dimension and the mean Hausdorff dimension of 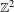 $\mathbb{Z}^{2}$-subshifts with respect to a subaction of
$\mathbb{Z}^{2}$-subshifts with respect to a subaction of  $\mathbb{Z}$. The resulting formula is quite analogous to Furstenberg’s theorem. We also calculate the rate distortion dimension of
$\mathbb{Z}$. The resulting formula is quite analogous to Furstenberg’s theorem. We also calculate the rate distortion dimension of 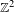 $\mathbb{Z}^{2}$-subshifts in terms of Kolmogorov–Sinai entropy.
$\mathbb{Z}^{2}$-subshifts in terms of Kolmogorov–Sinai entropy.
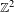
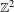

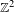
Pointer chasing via triangular discrimination
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 4 / July 2020
- Published online by Cambridge University Press:
- 15 May 2020, pp. 485-494
-
- Article
-
- You have access
- Open access
- Export citation
-
We prove an essentially sharp
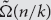 $\tilde \Omega (n/k)$ lower bound on the k-round distributional complexity of the k-step pointer chasing problem under the uniform distribution, when Bob speaks first. This is an improvement over Nisan and Wigderson’s
$\tilde \Omega (n/k)$ lower bound on the k-round distributional complexity of the k-step pointer chasing problem under the uniform distribution, when Bob speaks first. This is an improvement over Nisan and Wigderson’s 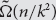 $\tilde \Omega (n/{k^2})$ lower bound, and essentially matches the randomized lower bound proved by Klauck. The proof is information-theoretic, and a key part of it is using asymmetric triangular discrimination instead of total variation distance; this idea may be useful elsewhere.
$\tilde \Omega (n/{k^2})$ lower bound, and essentially matches the randomized lower bound proved by Klauck. The proof is information-theoretic, and a key part of it is using asymmetric triangular discrimination instead of total variation distance; this idea may be useful elsewhere.
ISOGENIES OF ABELIAN VARIETIES IN CRYPTOGRAPHY
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 101 / Issue 3 / June 2020
- Published online by Cambridge University Press:
- 16 March 2020, pp. 508-509
- Print publication:
- June 2020
-
- Article
-
- You have access
- Export citation
ON THE
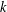 $k$-ERROR LINEAR COMPLEXITY OF SEQUENCES FROM FUNCTION FIELDS
$k$-ERROR LINEAR COMPLEXITY OF SEQUENCES FROM FUNCTION FIELDS
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 102 / Issue 2 / October 2020
- Published online by Cambridge University Press:
- 08 January 2020, pp. 342-352
- Print publication:
- October 2020
-
- Article
-
- You have access
- Export citation