Refine listing
Actions for selected content:
89 results in 94Axx
THE RESTRICTED ISOMETRY PROPERTY FOR SIGNAL RECOVERY WITH COHERENT TIGHT FRAMES
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 92 / Issue 3 / December 2015
- Published online by Cambridge University Press:
- 19 August 2015, pp. 496-507
- Print publication:
- December 2015
-
- Article
-
- You have access
- Export citation
-
In this paper, we consider signal recovery via
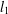 $l_{1}$-analysis optimisation. The signals we consider are not sparse in an orthonormal basis or incoherent dictionary, but sparse or nearly sparse in terms of some tight frame
$l_{1}$-analysis optimisation. The signals we consider are not sparse in an orthonormal basis or incoherent dictionary, but sparse or nearly sparse in terms of some tight frame 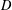 $D$. The analysis in this paper is based on the restricted isometry property adapted to a tight frame
$D$. The analysis in this paper is based on the restricted isometry property adapted to a tight frame 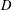 $D$ (abbreviated as
$D$ (abbreviated as 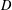 $D$-RIP), which is a natural extension of the standard restricted isometry property. Assuming that the measurement matrix
$D$-RIP), which is a natural extension of the standard restricted isometry property. Assuming that the measurement matrix 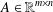 $A\in \mathbb{R}^{m\times n}$ satisfies
$A\in \mathbb{R}^{m\times n}$ satisfies 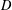 $D$-RIP with constant
$D$-RIP with constant 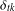 ${\it\delta}_{tk}$ for integer
${\it\delta}_{tk}$ for integer 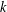 $k$ and
$k$ and 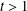 $t>1$, we show that the condition
$t>1$, we show that the condition 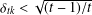 ${\it\delta}_{tk}<\sqrt{(t-1)/t}$ guarantees stable recovery of signals through
${\it\delta}_{tk}<\sqrt{(t-1)/t}$ guarantees stable recovery of signals through 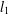 $l_{1}$-analysis. This condition is sharp in the sense explained in the paper. The results improve those of Li and Lin [‘Compressed sensing with coherent tight frames via
$l_{1}$-analysis. This condition is sharp in the sense explained in the paper. The results improve those of Li and Lin [‘Compressed sensing with coherent tight frames via 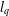 $l_{q}$-minimization for
$l_{q}$-minimization for 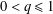 $0<q\leq 1$’, Preprint, 2011, arXiv:1105.3299] and Baker [‘A note on sparsification by frames’, Preprint, 2013, arXiv:1308.5249].
$0<q\leq 1$’, Preprint, 2011, arXiv:1105.3299] and Baker [‘A note on sparsification by frames’, Preprint, 2013, arXiv:1308.5249].
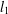
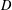
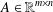
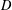
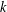
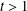
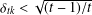
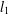
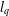
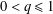
Capacity and Error Exponents of Stationary Point Processes under Random Additive Displacements
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 47 / Issue 1 / March 2015
- Published online by Cambridge University Press:
- 04 January 2016, pp. 1-26
- Print publication:
- March 2015
-
- Article
-
- You have access
- Export citation
Lumpings of Markov Chains, Entropy Rate Preservation, and Higher-Order Lumpability
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 51 / Issue 4 / December 2014
- Published online by Cambridge University Press:
- 30 January 2018, pp. 1114-1132
- Print publication:
- December 2014
-
- Article
-
- You have access
- Export citation
The discrete logarithm problem for exponents of bounded height
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue A / 2014
- Published online by Cambridge University Press:
- 01 August 2014, pp. 148-156
-
- Article
-
- You have access
- Export citation
-
Let
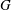 $\def \xmlpi #1{}\def \mathsfbi #1{\boldsymbol {\mathsf {#1}}}\let \le =\leqslant \let \leq =\leqslant \let \ge =\geqslant \let \geq =\geqslant \def \Pr {\mathit {Pr}}\def \Fr {\mathit {Fr}}\def \Rey {\mathit {Re}}G$ be a cyclic group written multiplicatively (and represented in some concrete way). Let
$\def \xmlpi #1{}\def \mathsfbi #1{\boldsymbol {\mathsf {#1}}}\let \le =\leqslant \let \leq =\leqslant \let \ge =\geqslant \let \geq =\geqslant \def \Pr {\mathit {Pr}}\def \Fr {\mathit {Fr}}\def \Rey {\mathit {Re}}G$ be a cyclic group written multiplicatively (and represented in some concrete way). Let  $n$ be a positive integer (much smaller than the order of
$n$ be a positive integer (much smaller than the order of 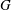 $G$). Let
$G$). Let 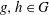 $g,h\in G$. The bounded height discrete logarithm problem is the task of finding positive integers
$g,h\in G$. The bounded height discrete logarithm problem is the task of finding positive integers  $a$ and
$a$ and 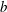 $b$ (if they exist) such that
$b$ (if they exist) such that 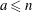 $a\leq n$,
$a\leq n$, 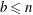 $b\leq n$ and
$b\leq n$ and 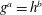 $g^a=h^b$. (Provided that
$g^a=h^b$. (Provided that 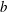 $b$ is coprime to the order of
$b$ is coprime to the order of 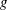 $g$, we have
$g$, we have 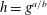 $h=g^{a/b}$ where
$h=g^{a/b}$ where 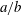 $a/b$ is a rational number of height at most
$a/b$ is a rational number of height at most  $n$. This motivates the terminology.)
$n$. This motivates the terminology.)The paper provides a reduction to the two-dimensional discrete logarithm problem, so the bounded height discrete logarithm problem can be solved using a low-memory heuristic algorithm for the two-dimensional discrete logarithm problem due to Gaudry and Schost. The paper also provides a low-memory heuristic algorithm to solve the bounded height discrete logarithm problem in a generic group directly, without using a reduction to the two-dimensional discrete logarithm problem. This new algorithm is inspired by (but differs from) the Gaudry–Schost algorithm. Both algorithms use
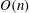 $O(n)$ group operations, but the new algorithm is faster and simpler than the Gaudry–Schost algorithm when used to solve the bounded height discrete logarithm problem. Like the Gaudry–Schost algorithm, the new algorithm can easily be carried out in a distributed fashion.
$O(n)$ group operations, but the new algorithm is faster and simpler than the Gaudry–Schost algorithm when used to solve the bounded height discrete logarithm problem. Like the Gaudry–Schost algorithm, the new algorithm can easily be carried out in a distributed fashion.The bounded height discrete logarithm problem is relevant to a class of attacks on the privacy of a key establishment protocol recently published by EMVCo for comment. This protocol is intended to protect the communications between a chip-based payment card and a terminal using elliptic curve cryptography. The paper comments on the implications of these attacks for the design of any final version of the EMV protocol.

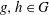

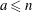
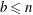
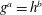
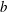
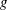
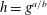
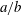

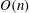
Hyper-and-elliptic-curve cryptography
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue A / 2014
- Published online by Cambridge University Press:
- 01 August 2014, pp. 181-202
-
- Article
-
- You have access
- Export citation
AN EFFICIENT METHOD FOR IMPROVING THE COMPUTATIONAL PERFORMANCE OF THE CUBIC LUCAS CRYPTOSYSTEM
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 90 / Issue 1 / August 2014
- Published online by Cambridge University Press:
- 10 April 2014, pp. 160-171
- Print publication:
- August 2014
-
- Article
-
- You have access
- Export citation
Wieferich pairs and Barker sequences, II
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue 1 / 2014
- Published online by Cambridge University Press:
- 01 April 2014, pp. 24-32
-
- Article
-
- You have access
- Export citation
-
We show that if a Barker sequence of length
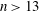 $n>13$ exists, then either n
$n>13$ exists, then either n  $=$ 3 979 201 339 721749 133 016 171 583 224 100, or
$=$ 3 979 201 339 721749 133 016 171 583 224 100, or 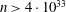 $n > 4\cdot 10^{33}$ . This improves the lower bound on the length of a long Barker sequence by a factor of nearly
$n > 4\cdot 10^{33}$ . This improves the lower bound on the length of a long Barker sequence by a factor of nearly 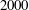 $2000$ . We also obtain eighteen additional integers
$2000$ . We also obtain eighteen additional integers 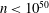 $n<10^{50}$ that cannot be ruled out as the length of a Barker sequence, and find more than 237 000 additional candidates
$n<10^{50}$ that cannot be ruled out as the length of a Barker sequence, and find more than 237 000 additional candidates 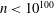 $n<10^{100}$ . These results are obtained by completing extensive searches for Wieferich prime pairs and using them, together with a number of arithmetic restrictions on
$n<10^{100}$ . These results are obtained by completing extensive searches for Wieferich prime pairs and using them, together with a number of arithmetic restrictions on  $n$ , to construct qualifying integers below a given bound. We also report on some updated computations regarding open cases of the circulant Hadamard matrix problem.
$n$ , to construct qualifying integers below a given bound. We also report on some updated computations regarding open cases of the circulant Hadamard matrix problem.
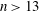

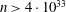
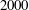
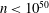
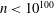

Local Digital Estimators of Intrinsic Volumes for Boolean Models and in the Design-Based Setting
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 46 / Issue 1 / March 2014
- Published online by Cambridge University Press:
- 22 February 2016, pp. 35-58
- Print publication:
- March 2014
-
- Article
-
- You have access
- Export citation
On the use of expansion series for stream ciphers
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 15 / May 2012
- Published online by Cambridge University Press:
- 01 September 2012, pp. 326-340
-
- Article
-
- You have access
- Export citation
COUNTING FIXED POINTS, TWO-CYCLES, AND COLLISIONS OF THE DISCRETE EXPONENTIAL FUNCTION USING p-ADIC METHODS
- Part of
-
- Journal:
- Journal of the Australian Mathematical Society / Volume 92 / Issue 2 / April 2012
- Published online by Cambridge University Press:
- 22 November 2012, pp. 163-178
- Print publication:
- April 2012
-
- Article
-
- You have access
- Export citation
BOUNDS IN TERMS OF GÂTEAUX DERIVATIVES FOR THE WEIGHTED f-GINI MEAN DIFFERENCE IN LINEAR SPACES
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 83 / Issue 3 / June 2011
- Published online by Cambridge University Press:
- 01 April 2011, pp. 420-434
- Print publication:
- June 2011
-
- Article
-
- You have access
- Export citation
ENDPOINT ESTIMATES FOR COMMUTATORS OF RIESZ TRANSFORMS ASSOCIATED WITH SCHRÖDINGER OPERATORS
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 82 / Issue 3 / December 2010
- Published online by Cambridge University Press:
- 16 August 2010, pp. 367-389
- Print publication:
- December 2010
-
- Article
-
- You have access
- Export citation
SAMPLING AND BIRKHOFF REGULAR PROBLEMS
- Part of
-
- Journal:
- Journal of the Australian Mathematical Society / Volume 87 / Issue 3 / December 2009
- Published online by Cambridge University Press:
- 15 December 2009, pp. 289-310
- Print publication:
- December 2009
-
- Article
-
- You have access
- Export citation
SECURE AND PRIVATE FINGERPRINT-BASED AUTHENTICATION
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 80 / Issue 2 / October 2009
- Published online by Cambridge University Press:
- 04 September 2009, pp. 347-349
- Print publication:
- October 2009
-
- Article
-
- You have access
- Export citation
CODES ASSOCIATED WITH Sp(4,q) AND EVEN-POWER MOMENTS OF KLOOSTERMAN SUMS
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 79 / Issue 3 / June 2009
- Published online by Cambridge University Press:
- 17 April 2009, pp. 427-435
- Print publication:
- June 2009
-
- Article
-
- You have access
- Export citation
Large deviations for eigenvalues of sample covariance matrices, with applications to mobile communication systems
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 40 / Issue 4 / December 2008
- Published online by Cambridge University Press:
- 01 July 2016, pp. 1048-1071
- Print publication:
- December 2008
-
- Article
-
- You have access
- Export citation
A Central Limit Theorem for Non-Overlapping Return Times
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 43 / Issue 1 / March 2006
- Published online by Cambridge University Press:
- 14 July 2016, pp. 32-47
- Print publication:
- March 2006
-
- Article
-
- You have access
- Export citation
Power spectra of random spike fields and related processes
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 37 / Issue 4 / December 2005
- Published online by Cambridge University Press:
- 01 July 2016, pp. 1116-1146
- Print publication:
- December 2005
-
- Article
-
- You have access
- Export citation
Minimum dynamic discrimination information models
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 42 / Issue 3 / September 2005
- Published online by Cambridge University Press:
- 14 July 2016, pp. 643-660
- Print publication:
- September 2005
-
- Article
-
- You have access
- Export citation
Improving the performance of third-generation wireless communication systems
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 36 / Issue 4 / December 2004
- Published online by Cambridge University Press:
- 01 July 2016, pp. 1046-1084
- Print publication:
- December 2004
-
- Article
- Export citation
