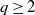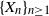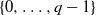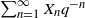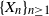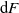Refine search
Actions for selected content:
53196 results in Statistics and Probability
Trajectory design via unsupervised probabilistic learning on optimal manifolds
-
- Journal:
- Data-Centric Engineering / Volume 3 / 2022
- Published online by Cambridge University Press:
- 23 August 2022, e26
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Assessing government policies' impact on the COVID-19 pandemic and elderly deaths in East Asia
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 22 August 2022, e161
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Molecular epidemiology of paediatric invasive pneumococcal disease in Andalusia, Spain
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 22 August 2022, e163
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On a mixed singular/switching control problem with multiple regimes
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 54 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 22 August 2022, pp. 743-782
- Print publication:
- September 2022
-
- Article
- Export citation
-
This paper studies a mixed singular/switching stochastic control problem for a multidimensional diffusion with multiple regimes on a bounded domain. Using probabilistic partial differential equation and penalization techniques, we show that the value function associated with this problem agrees with the solution to a Hamilton–Jacobi–Bellman equation. In this way, we see that the regularity of the value function is
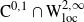 $ \textrm{C}^{0,1}\cap \textrm{W}^{2,\infty}_{\textrm{loc}}$.
$ \textrm{C}^{0,1}\cap \textrm{W}^{2,\infty}_{\textrm{loc}}$.
Mental health working party: data and modelling considerations for mental health in life insurance
-
- Journal:
- British Actuarial Journal / Volume 27 / 2022
- Published online by Cambridge University Press:
- 22 August 2022, e18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
RECURSIVE DIFFERENCING FOR ESTIMATING SEMIPARAMETRIC MODELS
-
- Journal:
- Econometric Theory / Volume 40 / Issue 1 / February 2024
- Published online by Cambridge University Press:
- 18 August 2022, pp. 37-59
-
- Article
-
- You have access
- Open access
- Export citation
Gromov–Wasserstein distances between Gaussian distributions
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 18 August 2022, pp. 1178-1198
- Print publication:
- December 2022
-
- Article
- Export citation
INFERENCE ON A DISTRIBUTION FROM NOISY DRAWS
-
- Journal:
- Econometric Theory / Volume 40 / Issue 1 / February 2024
- Published online by Cambridge University Press:
- 18 August 2022, pp. 60-97
-
- Article
- Export citation
Simple analytical solutions for the
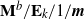 $\mathbf{M}^{b}/\mathbf{E}_{k}/1/\textbf{m}$,
$\mathbf{M}^{b}/\mathbf{E}_{k}/1/\textbf{m}$, 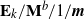 $\mathbf{E}_{k}/\mathbf{M}^{b}/1/\textbf{m}$, and related queues
$\mathbf{E}_{k}/\mathbf{M}^{b}/1/\textbf{m}$, and related queues
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 18 August 2022, pp. 1129-1143
- Print publication:
- December 2022
-
- Article
- Export citation
-
In this paper we revisit some classical queueing systems such as the M
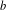 $^b$/E
$^b$/E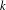 $_k$/1/m and E
$_k$/1/m and E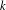 $_k$/M
$_k$/M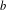 $^b$/1/m queues, for which fast numerical and recursive methods exist to study their main performance measures. We present simple explicit results for the loss probability and queue length distribution of these queueing systems as well as for some related queues such as the M
$^b$/1/m queues, for which fast numerical and recursive methods exist to study their main performance measures. We present simple explicit results for the loss probability and queue length distribution of these queueing systems as well as for some related queues such as the M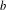 $^b$/D/1/m queue, the D/M
$^b$/D/1/m queue, the D/M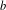 $^b$/1/m queue, and fluid versions thereof. In order to establish these results we first present a simple analytical solution for the invariant measure of the M/E
$^b$/1/m queue, and fluid versions thereof. In order to establish these results we first present a simple analytical solution for the invariant measure of the M/E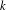 $_k$/1 queue that appears to be new.
$_k$/1 queue that appears to be new.
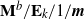
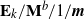
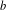
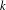
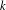
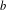
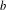
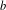
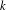
TWO-STEP ESTIMATION OF QUANTILE PANEL DATA MODELS WITH INTERACTIVE FIXED EFFECTS
-
- Journal:
- Econometric Theory / Volume 40 / Issue 2 / April 2024
- Published online by Cambridge University Press:
- 18 August 2022, pp. 419-446
-
- Article
- Export citation
-
This paper considers the estimation of panel data models with interactive fixed effects where the idiosyncratic errors are subject to conditional quantile restrictions. An easy-to-implement two-step estimator is proposed for the coefficients of the observed regressors. In the first step, the principal component analysis is applied to the cross-sectional averages of the regressors to estimate the latent factors. In the second step, the smoothed quantile regression is used to estimate the coefficients of the observed regressors and the factor loadings jointly. The consistency and asymptotic normality of the estimator are established under large
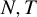 $N,T$ asymptotics. It is found that the asymptotic distribution of the estimator suffers from asymptotic biases, and this paper shows how to correct the biases using both analytical and split-panel jackknife bias corrections. Simulation studies confirm that the proposed estimator performs well with moderate sample sizes.
$N,T$ asymptotics. It is found that the asymptotic distribution of the estimator suffers from asymptotic biases, and this paper shows how to correct the biases using both analytical and split-panel jackknife bias corrections. Simulation studies confirm that the proposed estimator performs well with moderate sample sizes.
A deep look into the dagum family of isotropic covariance functions
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 18 August 2022, pp. 1026-1041
- Print publication:
- December 2022
-
- Article
- Export citation
-
The Dagum family of isotropic covariance functions has two parameters that allow for decoupling of the fractal dimension and the Hurst effect for Gaussian random fields that are stationary and isotropic over Euclidean spaces. Sufficient conditions that allow for positive definiteness in
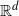 $\mathbb{R}^d$ of the Dagum family have been proposed on the basis of the fact that the Dagum family allows for complete monotonicity under some parameter restrictions. The spectral properties of the Dagum family have been inspected to a very limited extent only, and this paper gives insight into this direction. Specifically, we study finite and asymptotic properties of the isotropic spectral density (intended as the Hankel transform) of the Dagum model. Also, we establish some closed-form expressions for the Dagum spectral density in terms of the Fox–Wright functions. Finally, we provide asymptotic properties for such a class of spectral densities.
$\mathbb{R}^d$ of the Dagum family have been proposed on the basis of the fact that the Dagum family allows for complete monotonicity under some parameter restrictions. The spectral properties of the Dagum family have been inspected to a very limited extent only, and this paper gives insight into this direction. Specifically, we study finite and asymptotic properties of the isotropic spectral density (intended as the Hankel transform) of the Dagum model. Also, we establish some closed-form expressions for the Dagum spectral density in terms of the Fox–Wright functions. Finally, we provide asymptotic properties for such a class of spectral densities.
Comparative symptomatology of infection with SARS-CoV-2 variants Omicron (B.1.1.529) and Delta (B.1.617.2) from routine contact tracing data in England
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 17 August 2022, e162
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Association of patient characteristics with clinical outcomes in a cohort of hospitalised patients with SARS-CoV-2 infection in a Greek referral centre for COVID-19
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 16 August 2022, e160
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Economic burden attributable to healthcare-associated infections in tertiary public hospitals of Central China: a multi-centre case-control study
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 15 August 2022, e155
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On strongly rigid hyperfluctuating random measures
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 15 August 2022, pp. 948-961
- Print publication:
- December 2022
-
- Article
- Export citation
Degree sequences of sufficiently dense random uniform hypergraphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 2 / March 2023
- Published online by Cambridge University Press:
- 15 August 2022, pp. 183-224
-
- Article
- Export citation
-
We find an asymptotic enumeration formula for the number of simple
 $r$-uniform hypergraphs with a given degree sequence, when the number of edges is sufficiently large. The formula is given in terms of the solution of a system of equations. We give sufficient conditions on the degree sequence which guarantee existence of a solution to this system. Furthermore, we solve the system and give an explicit asymptotic formula when the degree sequence is close to regular. This allows us to establish several properties of the degree sequence of a random
$r$-uniform hypergraphs with a given degree sequence, when the number of edges is sufficiently large. The formula is given in terms of the solution of a system of equations. We give sufficient conditions on the degree sequence which guarantee existence of a solution to this system. Furthermore, we solve the system and give an explicit asymptotic formula when the degree sequence is close to regular. This allows us to establish several properties of the degree sequence of a random  $r$-uniform hypergraph with a given number of edges. More specifically, we compare the degree sequence of a random
$r$-uniform hypergraph with a given number of edges. More specifically, we compare the degree sequence of a random  $r$-uniform hypergraph with a given number edges to certain models involving sequences of binomial or hypergeometric random variables conditioned on their sum.
$r$-uniform hypergraph with a given number edges to certain models involving sequences of binomial or hypergeometric random variables conditioned on their sum.



The related factors of new HIV infection among older men in Sichuan, China: a case–control study
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 15 August 2022, e156
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Random population dynamics under catastrophic events
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 15 August 2022, pp. 962-982
- Print publication:
- December 2022
-
- Article
- Export citation
Modelling the burden of long-term care for institutionalised elderly based on care duration and intensity
-
- Journal:
- Annals of Actuarial Science / Volume 17 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 15 August 2022, pp. 83-117
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Characterization of random variables with stationary digits
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 15 August 2022, pp. 931-947
- Print publication:
- December 2022
-
- Article
- Export citation
-
Let
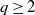 $q\ge2$ be an integer,
$q\ge2$ be an integer, 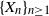 $\{X_n\}_{n\geq 1}$ a stochastic process with state space
$\{X_n\}_{n\geq 1}$ a stochastic process with state space 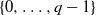 $\{0,\ldots,q-1\}$, and F the cumulative distribution function (CDF) of
$\{0,\ldots,q-1\}$, and F the cumulative distribution function (CDF) of 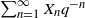 $\sum_{n=1}^\infty X_n q^{-n}$. We show that stationarity of
$\sum_{n=1}^\infty X_n q^{-n}$. We show that stationarity of 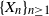 $\{X_n\}_{n\geq 1}$ is equivalent to a functional equation obeyed by F, and use this to characterize the characteristic function of X and the structure of F in terms of its Lebesgue decomposition. More precisely, while the absolutely continuous component of F can only be the uniform distribution on the unit interval, its discrete component can only be a countable convex combination of certain explicitly computable CDFs for probability distributions with finite support. We also show that
$\{X_n\}_{n\geq 1}$ is equivalent to a functional equation obeyed by F, and use this to characterize the characteristic function of X and the structure of F in terms of its Lebesgue decomposition. More precisely, while the absolutely continuous component of F can only be the uniform distribution on the unit interval, its discrete component can only be a countable convex combination of certain explicitly computable CDFs for probability distributions with finite support. We also show that 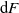 $\mathrm{d} F$ is a Rajchman measure if and only if F is the uniform CDF on [0, 1].
$\mathrm{d} F$ is a Rajchman measure if and only if F is the uniform CDF on [0, 1].