Refine search
Actions for selected content:
53196 results in Statistics and Probability
PES volume 36 issue 3 Cover and Back matter
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 3 / July 2022
- Published online by Cambridge University Press:
- 02 August 2022, pp. b1-b2
-
- Article
-
- You have access
- Export citation
Unbiased estimator for the ultimate claim prediction error in the chain-ladder model of Mack
-
- Journal:
- Annals of Actuarial Science / Volume 17 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 01 August 2022, pp. 118-144
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The
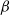 $\beta$-Delaunay tessellation: Description of the model and geometry of typical cells
$\beta$-Delaunay tessellation: Description of the model and geometry of typical cells
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 54 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 01 August 2022, pp. 1252-1290
- Print publication:
- December 2022
-
- Article
- Export citation
-
In this paper we introduce two new classes of stationary random simplicial tessellations, the so-called
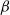 $\beta$- and
$\beta$- and 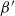 $\beta^{\prime}$-Delaunay tessellations. Their construction is based on a space–time paraboloid hull process and generalizes that of the classical Poisson–Delaunay tessellation. We explicitly identify the distribution of volume-power-weighted typical cells, establishing thereby a remarkable connection to the classes of
$\beta^{\prime}$-Delaunay tessellations. Their construction is based on a space–time paraboloid hull process and generalizes that of the classical Poisson–Delaunay tessellation. We explicitly identify the distribution of volume-power-weighted typical cells, establishing thereby a remarkable connection to the classes of 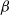 $\beta$- and
$\beta$- and 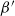 $\beta^{\prime}$-polytopes. These representations are used to determine the principal characteristics of such cells, including volume moments, expected angle sums, and cell intensities.
$\beta^{\prime}$-polytopes. These representations are used to determine the principal characteristics of such cells, including volume moments, expected angle sums, and cell intensities.
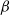
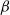
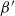
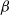
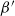
Interacting nonlinear reinforced stochastic processes: Synchronization or non-synchronization
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 01 August 2022, pp. 275-320
- Print publication:
- March 2023
-
- Article
- Export citation
Bonus-Malus Scale models: creating artificial past claims history
-
- Journal:
- Annals of Actuarial Science / Volume 17 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 29 July 2022, pp. 36-62
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Risk of acquiring Ascaris lumbricoides infection in an endemically infected rural community in Venezuela
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 29 July 2022, e151
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A new matrix-infinite-product-form solution for upper block-Hessenberg Markov chains and its quasi-algorithmic constructibility
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 29 July 2022, pp. 1-28
- Print publication:
- March 2023
-
- Article
- Export citation
Editorial The walls came tumbling down
-
- Journal:
- Annals of Actuarial Science / Volume 16 / Issue 2 / July 2022
- Published online by Cambridge University Press:
- 29 July 2022, pp. 211-213
-
- Article
-
- You have access
- HTML
- Export citation
Epidemiological characteristics of extrapulmonary tuberculosis patients with or without pulmonary tuberculosis
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 29 July 2022, e158
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Quantitative Enterprise Risk Management
-
- Published online:
- 28 July 2022
- Print publication:
- 05 May 2022
-
- Textbook
- Export citation
Using network analysis to improve understanding and utility of the 10-item Autism-Spectrum Quotient
-
- Journal:
- Experimental Results / Volume 3 / 2022
- Published online by Cambridge University Press:
- 28 July 2022, e12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
COVID-19 preventive measures coincided with a marked decline in other infectious diseases in Denmark, spring 2020
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 28 July 2022, e138
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Predicting incidence of hepatitis E using machine learning in Jiangsu Province, China
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 28 July 2022, e149
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Rate of convergence for particle approximation of PDEs in Wasserstein space
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 28 July 2022, pp. 992-1008
- Print publication:
- December 2022
-
- Article
- Export citation
-
We prove a rate of convergence for the N-particle approximation of a second-order partial differential equation in the space of probability measures, such as the master equation or Bellman equation of the mean-field control problem under common noise. The rate is of order
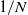 $1/N$ for the pathwise error on the solution v and of order
$1/N$ for the pathwise error on the solution v and of order 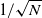 $1/\sqrt{N}$ for the
$1/\sqrt{N}$ for the 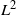 $L^2$-error on its L-derivative
$L^2$-error on its L-derivative 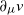 $\partial_\mu v$. The proof relies on backward stochastic differential equation techniques.
$\partial_\mu v$. The proof relies on backward stochastic differential equation techniques.
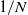
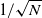
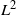
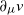
Less-expensive long-term annuities linked to mortality, cash and equity
-
- Journal:
- Annals of Actuarial Science / Volume 17 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 28 July 2022, pp. 170-207
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ESTIMATION AND INFERENCE WITH NEAR UNIT ROOTS
-
- Journal:
- Econometric Theory / Volume 39 / Issue 2 / April 2023
- Published online by Cambridge University Press:
- 27 July 2022, pp. 221-263
-
- Article
-
- You have access
- Open access
- Export citation
NWS volume 10 issue 2 Cover and Front matter
-
- Journal:
- Network Science / Volume 10 / Issue 2 / June 2022
- Published online by Cambridge University Press:
- 27 July 2022, pp. f1-f3
-
- Article
-
- You have access
- Export citation
Ordered multi-state system signature and its dynamic version in evaluating used multi-state systems
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 4 / October 2023
- Published online by Cambridge University Press:
- 27 July 2022, pp. 873-887
-
- Article
- Export citation
HPV vaccination and factors influencing vaccine uptake among people of Indian ancestry living in the United States
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 27 July 2022, e152
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Principles of Statistical Analysis
- Learning from Randomized Experiments
-
- Published online:
- 22 July 2022
- Print publication:
- 25 August 2022
