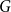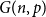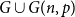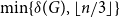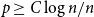Refine search
Actions for selected content:
53197 results in Statistics and Probability
COVID-19 vaccination rollout in the World Health Organization African region: status at end June 2022 and way forward
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 12 July 2022, e143
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Skew brownian motion and complexity of the alps algorithm
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 12 July 2022, pp. 777-796
- Print publication:
- September 2022
-
- Article
- Export citation
-
Simulated tempering is a popular method of allowing Markov chain Monte Carlo algorithms to move between modes of a multimodal target density
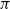 $\pi$. Tawn, Moores and Roberts (2021) introduces the Annealed Leap-Point Sampler (ALPS) to allow for rapid movement between modes. In this paper we prove that, under appropriate assumptions, a suitably scaled version of the ALPS algorithm converges weakly to skew Brownian motion. Our results show that, under appropriate assumptions, the ALPS algorithm mixes in time
$\pi$. Tawn, Moores and Roberts (2021) introduces the Annealed Leap-Point Sampler (ALPS) to allow for rapid movement between modes. In this paper we prove that, under appropriate assumptions, a suitably scaled version of the ALPS algorithm converges weakly to skew Brownian motion. Our results show that, under appropriate assumptions, the ALPS algorithm mixes in time 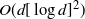 $O(d [\log d]^2)$ or O(d), depending on which version is used.
$O(d [\log d]^2)$ or O(d), depending on which version is used.
Application of recommender systems and time series models to monitor quality at HIV/AIDS health facilities
-
- Journal:
- Data & Policy / Volume 4 / 2022
- Published online by Cambridge University Press:
- 11 July 2022, e23
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Author response to: Letter to Editor in Response to the association between contact with children and the clinical course of COVID-19
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 11 July 2022, e139
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A novel approach to estimate the local population denominator to calculate disease incidence for hospital-based health events in England
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 11 July 2022, e150
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Mutually interacting superprocesses with migration
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 11 July 2022, pp. 904-929
- Print publication:
- September 2022
-
- Article
- Export citation
Generalized limit theorems for U-max statistics
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 11 July 2022, pp. 825-848
- Print publication:
- September 2022
-
- Article
- Export citation
-
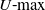 $U{\hbox{-}}\textrm{max}$ statistics were introduced by Lao and Mayer in 2008. Such statistics are natural in stochastic geometry. Examples are the maximal perimeters and areas of polygons and polyhedra formed by random points on a circle, ellipse, etc. The main method to study limit theorems for
$U{\hbox{-}}\textrm{max}$ statistics were introduced by Lao and Mayer in 2008. Such statistics are natural in stochastic geometry. Examples are the maximal perimeters and areas of polygons and polyhedra formed by random points on a circle, ellipse, etc. The main method to study limit theorems for 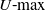 $U{\hbox{-}}\textrm{max}$ statistics is via a Poisson approximation. In this paper we consider a general class of kernels defined on a circle, and we prove a universal limit theorem with the Weibull distribution as a limit. Its parameters depend on the degree of the kernel, the structure of its points of maximum, and the Hessians of the kernel at these points. Almost all limit theorems known so far may be obtained as simple special cases of our general theorem. We also consider several new examples. Moreover, we consider not only the uniform distribution of points but also almost arbitrary distribution on a circle satisfying mild additional conditions.
$U{\hbox{-}}\textrm{max}$ statistics is via a Poisson approximation. In this paper we consider a general class of kernels defined on a circle, and we prove a universal limit theorem with the Weibull distribution as a limit. Its parameters depend on the degree of the kernel, the structure of its points of maximum, and the Hessians of the kernel at these points. Almost all limit theorems known so far may be obtained as simple special cases of our general theorem. We also consider several new examples. Moreover, we consider not only the uniform distribution of points but also almost arbitrary distribution on a circle satisfying mild additional conditions.
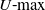
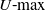
An extended class of univariate and multivariate generalized Pólya processes
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 54 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 11 July 2022, pp. 974-997
- Print publication:
- September 2022
-
- Article
- Export citation
A DECOMPOSITION ANALYSIS OF DIFFUSION OVER A LARGE NETWORK
-
- Journal:
- Econometric Theory / Volume 38 / Issue 6 / December 2022
- Published online by Cambridge University Press:
- 11 July 2022, pp. 1221-1252
-
- Article
-
- You have access
- Open access
- Export citation
Asymptotics of the overflow in urn models
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 11 July 2022, pp. 797-824
- Print publication:
- September 2022
-
- Article
- Export citation
-
Consider a finite or infinite collection of urns, each with capacity r, and balls randomly distributed among them. An overflow is the number of balls that are assigned to urns that already contain r balls. When
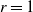 $r=1$, this is the number of balls landing in non-empty urns, which has been studied in the past. Our aim here is to use martingale methods to study the asymptotics of the overflow in the general situation, i.e. for arbitrary r. In particular, we provide sufficient conditions for both Poissonian and normal asymptotics.
$r=1$, this is the number of balls landing in non-empty urns, which has been studied in the past. Our aim here is to use martingale methods to study the asymptotics of the overflow in the general situation, i.e. for arbitrary r. In particular, we provide sufficient conditions for both Poissonian and normal asymptotics.
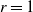
Varentropy of doubly truncated random variable
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 3 / July 2023
- Published online by Cambridge University Press:
- 08 July 2022, pp. 852-871
-
- Article
- Export citation
Transmission of SARS-CoV-2 among children and staff in German daycare centres
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 08 July 2022, e141
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Persisting gastrointestinal symptoms and post-infectious irritable bowel syndrome following SARS-CoV-2 infection: results from the Arizona CoVHORT
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 08 July 2022, e136
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On supercritical branching processes with emigration
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 08 July 2022, pp. 734-754
- Print publication:
- September 2022
-
- Article
- Export citation
Large-time behaviour and the second eigenvalue problem for finite-state mean-field interacting particle systems
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 08 July 2022, pp. 85-125
- Print publication:
- March 2023
-
- Article
- Export citation
-
This article examines large-time behaviour of finite-state mean-field interacting particle systems. Our first main result is a sharp estimate (in the exponential scale) of the time required for convergence of the empirical measure process of the N-particle system to its invariant measure; we show that when time is of the order
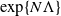 $\exp\{N\Lambda\}$ for a suitable constant
$\exp\{N\Lambda\}$ for a suitable constant 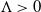 $\Lambda > 0$, the process has mixed well and it is close to its invariant measure. We then obtain large-N asymptotics of the second-largest eigenvalue of the generator associated with the empirical measure process when it is reversible with respect to its invariant measure. We show that its absolute value scales as
$\Lambda > 0$, the process has mixed well and it is close to its invariant measure. We then obtain large-N asymptotics of the second-largest eigenvalue of the generator associated with the empirical measure process when it is reversible with respect to its invariant measure. We show that its absolute value scales as 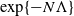 $\exp\{{-}N\Lambda\}$. The main tools used in establishing our results are the large deviation properties of the empirical measure process from its large-N limit. As an application of the study of large-time behaviour, we also show convergence of the empirical measure of the system of particles to a global minimum of a certain ‘entropy’ function when particles are added over time in a controlled fashion. The controlled addition of particles is analogous to the cooling schedule associated with the search for a global minimum of a function using the simulated annealing algorithm.
$\exp\{{-}N\Lambda\}$. The main tools used in establishing our results are the large deviation properties of the empirical measure process from its large-N limit. As an application of the study of large-time behaviour, we also show convergence of the empirical measure of the system of particles to a global minimum of a certain ‘entropy’ function when particles are added over time in a controlled fashion. The controlled addition of particles is analogous to the cooling schedule associated with the search for a global minimum of a function using the simulated annealing algorithm.
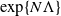
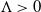
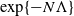
The digitization of the Brazilian national identity system: A descriptive and qualitative analysis of its information architecture
-
- Journal:
- Data & Policy / Volume 4 / 2022
- Published online by Cambridge University Press:
- 07 July 2022, e22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Response to the association between contact with children and the clinical course of COVID-19
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 07 July 2022, e140
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Limit laws for large
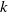 $k$th-nearest neighbor balls
$k$th-nearest neighbor balls
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 06 July 2022, pp. 880-894
- Print publication:
- September 2022
-
- Article
-
- You have access
- HTML
- Export citation
-
Let
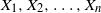 $X_1,X_2, \ldots, X_n$ be a sequence of independent random points in
$X_1,X_2, \ldots, X_n$ be a sequence of independent random points in 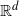 $\mathbb{R}^d$ with common Lebesgue density f. Under some conditions on f, we obtain a Poisson limit theorem, as
$\mathbb{R}^d$ with common Lebesgue density f. Under some conditions on f, we obtain a Poisson limit theorem, as 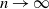 $n \to \infty$, for the number of large probability kth-nearest neighbor balls of
$n \to \infty$, for the number of large probability kth-nearest neighbor balls of 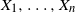 $X_1,\ldots, X_n$. Our result generalizes Theorem 2.2 of [11], which refers to the special case
$X_1,\ldots, X_n$. Our result generalizes Theorem 2.2 of [11], which refers to the special case 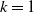 $k=1$. Our proof is completely different since it employs the Chen–Stein method instead of the method of moments. Moreover, we obtain a rate of convergence for the Poisson approximation.
$k=1$. Our proof is completely different since it employs the Chen–Stein method instead of the method of moments. Moreover, we obtain a rate of convergence for the Poisson approximation.
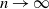
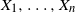
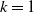
Clustered colouring of graph classes with bounded treedepth or pathwidth
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 1 / January 2023
- Published online by Cambridge University Press:
- 05 July 2022, pp. 122-133
-
- Article
- Export citation
-
The clustered chromatic number of a class of graphs is the minimum integer
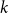 $k$ such that for some integer
$k$ such that for some integer  $c$ every graph in the class is
$c$ every graph in the class is 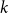 $k$-colourable with monochromatic components of size at most
$k$-colourable with monochromatic components of size at most  $c$. We determine the clustered chromatic number of any minor-closed class with bounded treedepth, and prove a best possible upper bound on the clustered chromatic number of any minor-closed class with bounded pathwidth. As a consequence, we determine the fractional clustered chromatic number of every minor-closed class.
$c$. We determine the clustered chromatic number of any minor-closed class with bounded treedepth, and prove a best possible upper bound on the clustered chromatic number of any minor-closed class with bounded pathwidth. As a consequence, we determine the fractional clustered chromatic number of every minor-closed class.
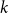

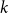

Triangles in randomly perturbed graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 1 / January 2023
- Published online by Cambridge University Press:
- 05 July 2022, pp. 91-121
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study the problem of finding pairwise vertex-disjoint triangles in the randomly perturbed graph model, which is the union of any
 $n$-vertex graph
$n$-vertex graph 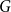 $G$ satisfying a given minimum degree condition and the binomial random graph
$G$ satisfying a given minimum degree condition and the binomial random graph 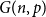 $G(n,p)$. We prove that asymptotically almost surely
$G(n,p)$. We prove that asymptotically almost surely 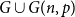 $G \cup G(n,p)$ contains at least
$G \cup G(n,p)$ contains at least 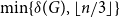 $\min \{\delta (G), \lfloor n/3 \rfloor \}$ pairwise vertex-disjoint triangles, provided
$\min \{\delta (G), \lfloor n/3 \rfloor \}$ pairwise vertex-disjoint triangles, provided 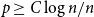 $p \ge C \log n/n$, where
$p \ge C \log n/n$, where 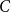 $C$ is a large enough constant. This is a perturbed version of an old result of Dirac.
$C$ is a large enough constant. This is a perturbed version of an old result of Dirac.Our result is asymptotically optimal and answers a question of Han, Morris, and Treglown [RSA, 2021, no. 3, 480–516] in a strong form. We also prove a stability version of our result, which in the case of pairwise vertex-disjoint triangles extends a result of Han, Morris, and Treglown [RSA, 2021, no. 3, 480–516]. Together with a result of Balogh, Treglown, and Wagner [CPC, 2019, no. 2, 159–176], this fully resolves the existence of triangle factors in randomly perturbed graphs.
We believe that the methods introduced in this paper are useful for a variety of related problems: we discuss possible generalisations to clique factors, cycle factors, and
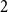 $2$-universality.
$2$-universality.