Refine search
Actions for selected content:
53196 results in Statistics and Probability
IDENTIFICATION AND THE INFLUENCE FUNCTION OF OLLEY AND PAKES’ (1996) PRODUCTION FUNCTION ESTIMATOR
-
- Journal:
- Econometric Theory / Volume 39 / Issue 5 / October 2023
- Published online by Cambridge University Press:
- 22 July 2022, pp. 1044-1066
-
- Article
- Export citation
SIMPLE SEMIPARAMETRIC ESTIMATION OF ORDERED RESPONSE MODELS
-
- Journal:
- Econometric Theory / Volume 40 / Issue 1 / February 2024
- Published online by Cambridge University Press:
- 22 July 2022, pp. 1-36
-
- Article
- Export citation
A BK inequality for random matchings
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 1 / January 2023
- Published online by Cambridge University Press:
- 22 July 2022, pp. 151-157
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Let
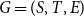 $G=(S,T,E)$ be a bipartite graph. For a matching
$G=(S,T,E)$ be a bipartite graph. For a matching 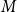 $M$ of
$M$ of 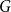 $G$, let
$G$, let 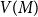 $V(M)$ be the set of vertices covered by
$V(M)$ be the set of vertices covered by 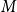 $M$, and let
$M$, and let 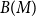 $B(M)$ be the symmetric difference of
$B(M)$ be the symmetric difference of 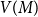 $V(M)$ and
$V(M)$ and 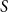 $S$. We prove that if
$S$. We prove that if 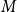 $M$ is a uniform random matching of
$M$ is a uniform random matching of 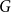 $G$, then
$G$, then 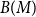 $B(M)$ satisfies the BK inequality for increasing events.
$B(M)$ satisfies the BK inequality for increasing events.
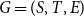
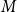
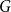
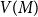
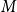
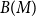
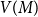
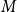
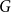
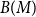
“Allowing for shocks in portfolio mortality models” by Stephen Richards
-
- Journal:
- British Actuarial Journal / Volume 27 / 2022
- Published online by Cambridge University Press:
- 22 July 2022, e17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On local weak limit and subgraph counts for sparse random graphs
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 21 July 2022, pp. 755-776
- Print publication:
- September 2022
-
- Article
- Export citation
Many Turán exponents via subdivisions
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 1 / January 2023
- Published online by Cambridge University Press:
- 21 July 2022, pp. 134-150
-
- Article
- Export citation
-
Given a graph
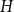 $H$ and a positive integer
$H$ and a positive integer  $n$, the Turán number
$n$, the Turán number 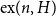 $\mathrm{ex}(n,H)$ is the maximum number of edges in an
$\mathrm{ex}(n,H)$ is the maximum number of edges in an  $n$-vertex graph that does not contain
$n$-vertex graph that does not contain 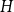 $H$ as a subgraph. A real number
$H$ as a subgraph. A real number 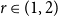 $r\in (1,2)$ is called a Turán exponent if there exists a bipartite graph
$r\in (1,2)$ is called a Turán exponent if there exists a bipartite graph 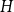 $H$ such that
$H$ such that 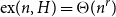 $\mathrm{ex}(n,H)=\Theta (n^r)$. A long-standing conjecture of Erdős and Simonovits states that
$\mathrm{ex}(n,H)=\Theta (n^r)$. A long-standing conjecture of Erdős and Simonovits states that 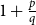 $1+\frac{p}{q}$ is a Turán exponent for all positive integers
$1+\frac{p}{q}$ is a Turán exponent for all positive integers 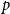 $p$ and
$p$ and 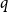 $q$ with
$q$ with 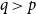 $q\gt p$.
$q\gt p$.In this paper, we show that
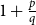 $1+\frac{p}{q}$ is a Turán exponent for all positive integers
$1+\frac{p}{q}$ is a Turán exponent for all positive integers 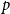 $p$ and
$p$ and 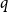 $q$ with
$q$ with 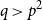 $q \gt p^{2}$. Our result also addresses a conjecture of Janzer [18].
$q \gt p^{2}$. Our result also addresses a conjecture of Janzer [18].
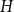

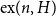

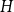
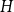
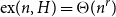
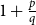
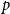
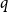
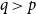
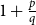
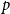
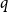
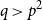
Pension Decumulation Pathways – a proposed approach
-
- Journal:
- British Actuarial Journal / Volume 27 / 2022
- Published online by Cambridge University Press:
- 20 July 2022, e16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Prevalence and surveillance of tuberculosis in Yemen from 2006 to 2018
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 20 July 2022, e146
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Spatial growth rate of emerging SARS-CoV-2 lineages in England, September 2020–December 2021
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 20 July 2022, e145
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Scheduling servers in a two-stage queue with abandonments and costs
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 3 / July 2023
- Published online by Cambridge University Press:
- 20 July 2022, pp. 833-851
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A note on the polynomial ergodicity of the one-dimensional Zig-Zag process
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 18 July 2022, pp. 895-903
- Print publication:
- September 2022
-
- Article
- Export citation
Epidemiology of repeat influenza infection in Queensland, Australia, 2005–2017
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 18 July 2022, e144
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A scoping review of factors potentially linked with antimicrobial-resistant bacteria from turkeys (iAM.AMR Project)
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 18 July 2022, e153
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Innate immunity to SARS-CoV-2 infection: a review
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 18 July 2022, e142
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
EVALUATING THE TAIL RISK OF MULTIVARIATE AGGREGATE LOSSES
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 52 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 15 July 2022, pp. 921-952
- Print publication:
- September 2022
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
LIMIT THEORY FOR LOCALLY FLAT FUNCTIONAL COEFFICIENT REGRESSION
-
- Journal:
- Econometric Theory / Volume 39 / Issue 5 / October 2023
- Published online by Cambridge University Press:
- 14 July 2022, pp. 900-949
-
- Article
-
- You have access
- Open access
- Export citation
Applications of the classical compound Poisson model with claim sizes following a compound distribution
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 2 / April 2023
- Published online by Cambridge University Press:
- 14 July 2022, pp. 357-386
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
COVID-19 accelerated mortality shocks and the impact on life insurance: the Italian situation
-
- Journal:
- Annals of Actuarial Science / Volume 16 / Issue 3 / November 2022
- Published online by Cambridge University Press:
- 13 July 2022, pp. 478-497
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The hit-and-run version of top-to-random
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 12 July 2022, pp. 860-879
- Print publication:
- September 2022
-
- Article
- Export citation
-
We study an example of a hit-and-run random walk on the symmetric group
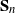 $\mathbf S_n$. Our starting point is the well-understood top-to-random shuffle. In the hit-and-run version, at each single step, after picking the point of insertion j uniformly at random in
$\mathbf S_n$. Our starting point is the well-understood top-to-random shuffle. In the hit-and-run version, at each single step, after picking the point of insertion j uniformly at random in 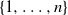 $\{1,\ldots,n\}$, the top card is inserted in the jth position k times in a row, where k is uniform in
$\{1,\ldots,n\}$, the top card is inserted in the jth position k times in a row, where k is uniform in 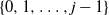 $\{0,1,\ldots,j-1\}$. The question is, does this accelerate mixing significantly or not? We show that, in
$\{0,1,\ldots,j-1\}$. The question is, does this accelerate mixing significantly or not? We show that, in 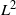 $L^2$ and sup-norm, this accelerates mixing at most by a constant factor (independent of n). Analyzing this problem in total variation is an interesting open question. We show that, in general, hit-and-run random walks on finite groups have non-negative spectrum.
$L^2$ and sup-norm, this accelerates mixing at most by a constant factor (independent of n). Analyzing this problem in total variation is an interesting open question. We show that, in general, hit-and-run random walks on finite groups have non-negative spectrum.
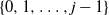
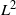
COVID-19 vaccination rollout in the World Health Organization African region: status at end June 2022 and way forward
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 12 July 2022, e143
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
