Refine search
Actions for selected content:
53197 results in Statistics and Probability
Characterization of random variables with stationary digits
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 15 August 2022, pp. 931-947
- Print publication:
- December 2022
-
- Article
- Export citation
-
Let
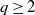 $q\ge2$ be an integer,
$q\ge2$ be an integer, 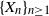 $\{X_n\}_{n\geq 1}$ a stochastic process with state space
$\{X_n\}_{n\geq 1}$ a stochastic process with state space 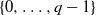 $\{0,\ldots,q-1\}$, and F the cumulative distribution function (CDF) of
$\{0,\ldots,q-1\}$, and F the cumulative distribution function (CDF) of 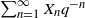 $\sum_{n=1}^\infty X_n q^{-n}$. We show that stationarity of
$\sum_{n=1}^\infty X_n q^{-n}$. We show that stationarity of 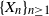 $\{X_n\}_{n\geq 1}$ is equivalent to a functional equation obeyed by F, and use this to characterize the characteristic function of X and the structure of F in terms of its Lebesgue decomposition. More precisely, while the absolutely continuous component of F can only be the uniform distribution on the unit interval, its discrete component can only be a countable convex combination of certain explicitly computable CDFs for probability distributions with finite support. We also show that
$\{X_n\}_{n\geq 1}$ is equivalent to a functional equation obeyed by F, and use this to characterize the characteristic function of X and the structure of F in terms of its Lebesgue decomposition. More precisely, while the absolutely continuous component of F can only be the uniform distribution on the unit interval, its discrete component can only be a countable convex combination of certain explicitly computable CDFs for probability distributions with finite support. We also show that 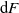 $\mathrm{d} F$ is a Rajchman measure if and only if F is the uniform CDF on [0, 1].
$\mathrm{d} F$ is a Rajchman measure if and only if F is the uniform CDF on [0, 1].
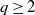
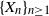
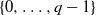
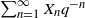
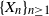
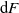
Measuring statistical learning by eye-tracking
-
- Journal:
- Experimental Results / Volume 3 / 2022
- Published online by Cambridge University Press:
- 15 August 2022, e10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Optimal singular dividend control with capital injection and affine penalty payment at ruin
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 2 / April 2023
- Published online by Cambridge University Press:
- 12 August 2022, pp. 462-490
-
- Article
- Export citation
Almost first-order stochastic dominance by distorted expectations
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 4 / October 2023
- Published online by Cambridge University Press:
- 12 August 2022, pp. 888-906
-
- Article
- Export citation
What effect might border screening have on preventing importation of COVID-19 compared with other infections?: considering the additional effect of post-arrival isolation
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 11 August 2022, e159
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Exponential convergence to a quasi-stationary distribution for birth–death processes with an entrance boundary at infinity
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 10 August 2022, pp. 983-991
- Print publication:
- December 2022
-
- Article
- Export citation
-
We study the quasi-stationary behavior of the birth–death process with an entrance boundary at infinity. We give by the h-transform an alternative and simpler proof for the exponential convergence of conditioned distributions to a unique quasi-stationary distribution in the total variation norm. In addition, we also show that starting from any initial distribution the conditional probability converges to the unique quasi-stationary distribution exponentially fast in the
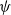 $\psi$-norm.
$\psi$-norm.
Sex and age differences in the proportion of experienced symptoms by SARS-CoV-2 serostatus in a community-based cross-sectional study
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 10 August 2022, e157
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A mapping method for anomaly detection in a localized population of structures
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 3 / 2022
- Published online by Cambridge University Press:
- 09 August 2022, e25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Bounds for the chi-square approximation of the power divergence family of statistics
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 09 August 2022, pp. 1059-1080
- Print publication:
- December 2022
-
- Article
-
- You have access
- HTML
- Export citation
-
It is well known that each statistic in the family of power divergence statistics, across n trials and r classifications with index parameter
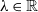 $\lambda\in\mathbb{R}$ (the Pearson, likelihood ratio, and Freeman–Tukey statistics correspond to
$\lambda\in\mathbb{R}$ (the Pearson, likelihood ratio, and Freeman–Tukey statistics correspond to 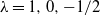 $\lambda=1,0,-1/2$, respectively), is asymptotically chi-square distributed as the sample size tends to infinity. We obtain explicit bounds on this distributional approximation, measured using smooth test functions, that hold for a given finite sample n, and all index parameters (
$\lambda=1,0,-1/2$, respectively), is asymptotically chi-square distributed as the sample size tends to infinity. We obtain explicit bounds on this distributional approximation, measured using smooth test functions, that hold for a given finite sample n, and all index parameters (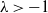 $\lambda>-1$) for which such finite-sample bounds are meaningful. We obtain bounds that are of the optimal order
$\lambda>-1$) for which such finite-sample bounds are meaningful. We obtain bounds that are of the optimal order 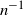 $n^{-1}$. The dependence of our bounds on the index parameter
$n^{-1}$. The dependence of our bounds on the index parameter 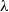 $\lambda$ and the cell classification probabilities is also optimal, and the dependence on the number of cells is also respectable. Our bounds generalise, complement, and improve on recent results from the literature.
$\lambda$ and the cell classification probabilities is also optimal, and the dependence on the number of cells is also respectable. Our bounds generalise, complement, and improve on recent results from the literature.
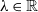
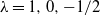
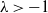
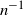
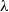
A probabilistic model for interfaces in a martensitic phase transition
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 09 August 2022, pp. 1081-1105
- Print publication:
- December 2022
-
- Article
-
- You have access
- HTML
- Export citation
A unifying approach to non-minimal quasi-stationary distributions for one-dimensional diffusions
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 08 August 2022, pp. 1106-1128
- Print publication:
- December 2022
-
- Article
- Export citation
Building better global data governance
-
- Journal:
- Data & Policy / Volume 4 / 2022
- Published online by Cambridge University Press:
- 08 August 2022, e25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Construction of aggregation paradoxes through load-sharing models
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 08 August 2022, pp. 223-244
- Print publication:
- March 2023
-
- Article
- Export citation
Serial interval in households infected with SARS-CoV-2 variant B.1.1.529 (Omicron) is even shorter compared to Delta
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 05 August 2022, e165
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Burkholderia cepacia complex outbreak linked to a no-rinse cleansing foam product, United States – 2017–2018
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 04 August 2022, e154
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Scaling limits of branching random walks and branching-stable processes
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 04 August 2022, pp. 1009-1025
- Print publication:
- December 2022
-
- Article
- Export citation

Large Deviations for Markov Chains
-
- Published online:
- 03 August 2022
- Print publication:
- 27 October 2022
CONSISTENT LOCAL SPECTRUM INFERENCE FOR PREDICTIVE RETURN REGRESSIONS
-
- Journal:
- Econometric Theory / Volume 38 / Issue 6 / December 2022
- Published online by Cambridge University Press:
- 03 August 2022, pp. 1253-1307
-
- Article
- Export citation
SIMULTANEOUS CONFIDENCE BANDS FOR CONDITIONAL VALUE-AT-RISK AND EXPECTED SHORTFALL
-
- Journal:
- Econometric Theory / Volume 39 / Issue 5 / October 2023
- Published online by Cambridge University Press:
- 03 August 2022, pp. 1009-1043
-
- Article
-
- You have access
- Open access
- Export citation
PES volume 36 issue 3 Cover and Front matter
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 3 / July 2022
- Published online by Cambridge University Press:
- 02 August 2022, pp. f1-f2
-
- Article
-
- You have access
- Export citation
