Refine search
Actions for selected content:
52666 results in Statistics and Probability
25 - Lecture 25: Sampling Random Tilings
-
- Book:
- Lectures on Random Lozenge Tilings
- Published online:
- 31 August 2021
- Print publication:
- 09 September 2021, pp 224-236
-
- Chapter
- Export citation
24 - Lecture 24: Discrete Gaussian Component in Fluctuations
-
- Book:
- Lectures on Random Lozenge Tilings
- Published online:
- 31 August 2021
- Print publication:
- 09 September 2021, pp 207-223
-
- Chapter
- Export citation
NWS volume 9 issue S1 Cover and Front matter
-
- Journal:
- Network Science / Volume 9 / Issue S1 / October 2021
- Published online by Cambridge University Press:
- 08 September 2021, pp. f1-f3
-
- Article
-
- You have access
- Export citation
Soccer in the time of COVID-19: 1 year report from an Italian top league club, March 2020–February 2021
- Part of
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 08 September 2021, e207
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The first 8 months of COVID-19 pandemic in three West African countries: leveraging lessons learned from responses to the 2014–2016 Ebola virus disease outbreak
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 08 September 2021, e258
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
NWS volume 9 issue S1 Cover and Back matter
-
- Journal:
- Network Science / Volume 9 / Issue S1 / October 2021
- Published online by Cambridge University Press:
- 08 September 2021, pp. b1-b2
-
- Article
-
- You have access
- Export citation
Model order reduction based on Runge–Kutta neural networks
-
- Journal:
- Data-Centric Engineering / Volume 2 / 2021
- Published online by Cambridge University Press:
- 08 September 2021, e13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Universal Digital Twin - A Dynamic Knowledge Graph
-
- Journal:
- Data-Centric Engineering / Volume 2 / 2021
- Published online by Cambridge University Press:
- 06 September 2021, e14
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Emulating computer experiments of transport infrastructure slope stability using Gaussian processes and Bayesian inference
-
- Journal:
- Data-Centric Engineering / Volume 2 / 2021
- Published online by Cambridge University Press:
- 06 September 2021, e12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Sub-district level correlation between tuberculosis notifications and socio-demographic factors in Dhaka City corporation, Bangladesh
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 02 September 2021, e209
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Clinical, health systems and neighbourhood determinants of tuberculosis case fatality in urban Blantyre, Malawi: a multilevel epidemiological analysis of enhanced surveillance data
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 02 September 2021, e198
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On the edit distance function of the random graph
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 31 / Issue 2 / March 2022
- Published online by Cambridge University Press:
- 02 September 2021, pp. 345-367
-
- Article
- Export citation
-
Given a hereditary property of graphs
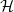 $\mathcal{H}$ and a
$\mathcal{H}$ and a 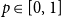 $p\in [0,1]$, the edit distance function
$p\in [0,1]$, the edit distance function 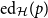 $\textrm{ed}_{\mathcal{H}}(p)$ is asymptotically the maximum proportion of edge additions plus edge deletions applied to a graph of edge density p sufficient to ensure that the resulting graph satisfies
$\textrm{ed}_{\mathcal{H}}(p)$ is asymptotically the maximum proportion of edge additions plus edge deletions applied to a graph of edge density p sufficient to ensure that the resulting graph satisfies 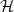 $\mathcal{H}$. The edit distance function is directly related to other well-studied quantities such as the speed function for
$\mathcal{H}$. The edit distance function is directly related to other well-studied quantities such as the speed function for 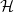 $\mathcal{H}$ and the
$\mathcal{H}$ and the 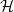 $\mathcal{H}$-chromatic number of a random graph.
$\mathcal{H}$-chromatic number of a random graph.Let
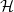 $\mathcal{H}$ be the property of forbidding an Erdős–Rényi random graph
$\mathcal{H}$ be the property of forbidding an Erdős–Rényi random graph 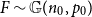 $F\sim \mathbb{G}(n_0,p_0)$, and let
$F\sim \mathbb{G}(n_0,p_0)$, and let 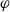 $\varphi$ represent the golden ratio. In this paper, we show that if
$\varphi$ represent the golden ratio. In this paper, we show that if 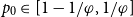 $p_0\in [1-1/\varphi,1/\varphi]$, then a.a.s. as
$p_0\in [1-1/\varphi,1/\varphi]$, then a.a.s. as 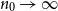 $n_0\to\infty$, Moreover, this holds for
$n_0\to\infty$, Moreover, this holds for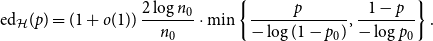 \begin{align*}{\textrm{ed}}_{\mathcal{H}}(p) = (1+o(1))\,\frac{2\log n_0}{n_0}\cdot\min\left\{\frac{p}{-\log(1-p_0)},\frac{1-p}{-\log p_0}\right\}.\end{align*}
\begin{align*}{\textrm{ed}}_{\mathcal{H}}(p) = (1+o(1))\,\frac{2\log n_0}{n_0}\cdot\min\left\{\frac{p}{-\log(1-p_0)},\frac{1-p}{-\log p_0}\right\}.\end{align*}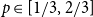 $p\in [1/3,2/3]$ for any
$p\in [1/3,2/3]$ for any 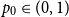 $p_0\in (0,1)$.
$p_0\in (0,1)$.A primary tool in the proof is the categorization of p-core coloured regularity graphs in the range
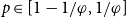 $p\in[1-1/\varphi,1/\varphi]$. Such coloured regularity graphs must have the property that the non-grey edges form vertex-disjoint cliques.
$p\in[1-1/\varphi,1/\varphi]$. Such coloured regularity graphs must have the property that the non-grey edges form vertex-disjoint cliques.
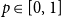
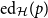
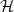
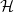
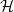
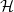
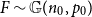
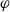
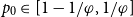
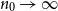
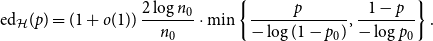
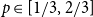
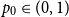
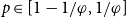
Abattoir-based study of Salmonella prevalence in pigs at slaughter in Great Britain
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 02 September 2021, e218
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Non-Gaussian fluctuations of randomly trapped random walks
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 53 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 08 October 2021, pp. 801-838
- Print publication:
- September 2021
-
- Article
- Export citation
Pathwise large deviations for the rough Bergomi model: Corrigendum
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 16 September 2021, pp. 849-850
- Print publication:
- September 2021
-
- Article
-
- You have access
- HTML
- Export citation
On the comparison of Shapley values for variance and standard deviation games
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 16 September 2021, pp. 609-620
- Print publication:
- September 2021
-
- Article
- Export citation
APR volume 53 issue 3 Cover and Back matter
-
- Journal:
- Advances in Applied Probability / Volume 53 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 08 October 2021, pp. b1-b2
- Print publication:
- September 2021
-
- Article
-
- You have access
- Export citation
Estimating tails of independently stopped random walks using concave approximations of hazard functions
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 16 September 2021, pp. 773-793
- Print publication:
- September 2021
-
- Article
- Export citation
Subgeometric ergodicity and β-mixing
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 16 September 2021, pp. 594-608
- Print publication:
- September 2021
-
- Article
- Export citation
-
It is well known that stationary geometrically ergodic Markov chains are
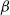 $\beta$-mixing (absolutely regular) with geometrically decaying mixing coefficients. Furthermore, for initial distributions other than the stationary one, geometric ergodicity implies
$\beta$-mixing (absolutely regular) with geometrically decaying mixing coefficients. Furthermore, for initial distributions other than the stationary one, geometric ergodicity implies 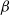 $\beta$-mixing under suitable moment assumptions. In this note we show that similar results hold also for subgeometrically ergodic Markov chains. In particular, for both stationary and other initial distributions, subgeometric ergodicity implies
$\beta$-mixing under suitable moment assumptions. In this note we show that similar results hold also for subgeometrically ergodic Markov chains. In particular, for both stationary and other initial distributions, subgeometric ergodicity implies 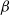 $\beta$-mixing with subgeometrically decaying mixing coefficients. Although this result is simple, it should prove very useful in obtaining rates of mixing in situations where geometric ergodicity cannot be established. To illustrate our results we derive new subgeometric ergodicity and
$\beta$-mixing with subgeometrically decaying mixing coefficients. Although this result is simple, it should prove very useful in obtaining rates of mixing in situations where geometric ergodicity cannot be established. To illustrate our results we derive new subgeometric ergodicity and 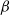 $\beta$-mixing results for the self-exciting threshold autoregressive model.
$\beta$-mixing results for the self-exciting threshold autoregressive model.
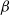
APR volume 53 issue 3 Cover and Front matter
-
- Journal:
- Advances in Applied Probability / Volume 53 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 08 October 2021, pp. f1-f2
- Print publication:
- September 2021
-
- Article
-
- You have access
- Export citation
