Refine search
Actions for selected content:
52669 results in Statistics and Probability
On the steady state of continuous-time stochastic opinion dynamics with power-law confidence
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 16 September 2021, pp. 746-772
- Print publication:
- September 2021
-
- Article
- Export citation
A transient Cramér–Lundberg model with applications to credit risk
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 16 September 2021, pp. 721-745
- Print publication:
- September 2021
-
- Article
- Export citation
Asymptotic behavior of the weak approximation to a class of Gaussian processes
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 16 September 2021, pp. 693-707
- Print publication:
- September 2021
-
- Article
- Export citation
Rejection- and importance-sampling-based perfect simulation for Gibbs hard-sphere models
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 53 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 08 October 2021, pp. 839-885
- Print publication:
- September 2021
-
- Article
- Export citation
Variations of the elephant random walk
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 16 September 2021, pp. 805-829
- Print publication:
- September 2021
-
- Article
- Export citation
Controlled branching processes with continuous time
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 16 September 2021, pp. 830-848
- Print publication:
- September 2021
-
- Article
- Export citation

Lectures on Random Lozenge Tilings
-
- Published online:
- 31 August 2021
- Print publication:
- 09 September 2021
Associations of genetic variants of miRNA coding regions with pulmonary tuberculosis risk in China
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 31 August 2021, e208
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On generative models as the basis for digital twins
-
- Journal:
- Data-Centric Engineering / Volume 2 / 2021
- Published online by Cambridge University Press:
- 31 August 2021, e11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
COST-SENSITIVE MULTI-CLASS ADABOOST FOR UNDERSTANDING DRIVING BEHAVIOR BASED ON TELEMATICS
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 51 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 31 August 2021, pp. 719-751
- Print publication:
- September 2021
-
- Article
- Export citation
Effects of air-conditioning systems in the public areas of hospitals: A scoping review
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 27 August 2021, e201
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Learning stable reduced-order models for hybrid twins
-
- Journal:
- Data-Centric Engineering / Volume 2 / 2021
- Published online by Cambridge University Press:
- 27 August 2021, e10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Mumps outbreak among fully vaccinated school-age children and young adults, Portugal 2019/2020
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 27 August 2021, e205
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Concentrated matrix exponential distributions with real eigenvalues
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 4 / October 2022
- Published online by Cambridge University Press:
- 26 August 2021, pp. 1171-1187
-
- Article
- Export citation
-
Concentrated random variables are frequently used in representing deterministic delays in stochastic models. The squared coefficient of variation (
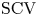 $\mathrm {SCV}$) of the most concentrated phase-type distribution of order
$\mathrm {SCV}$) of the most concentrated phase-type distribution of order 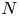 $N$ is
$N$ is 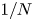 $1/N$. To further reduce the
$1/N$. To further reduce the 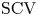 $\mathrm {SCV}$, concentrated matrix exponential (CME) distributions with complex eigenvalues were investigated recently. It was obtained that the
$\mathrm {SCV}$, concentrated matrix exponential (CME) distributions with complex eigenvalues were investigated recently. It was obtained that the 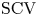 $\mathrm {SCV}$ of an order
$\mathrm {SCV}$ of an order 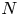 $N$ CME distribution can be less than
$N$ CME distribution can be less than 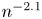 $n^{-2.1}$ for odd
$n^{-2.1}$ for odd 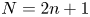 $N=2n+1$ orders, and the matrix exponential distribution, which exhibits such a low
$N=2n+1$ orders, and the matrix exponential distribution, which exhibits such a low 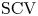 $\mathrm {SCV}$ has complex eigenvalues. In this paper, we consider CME distributions with real eigenvalues (CME-R). We present efficient numerical methods for identifying a CME-R distribution with smallest SCV for a given order
$\mathrm {SCV}$ has complex eigenvalues. In this paper, we consider CME distributions with real eigenvalues (CME-R). We present efficient numerical methods for identifying a CME-R distribution with smallest SCV for a given order 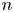 $n$. Our investigations show that the
$n$. Our investigations show that the 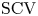 $\mathrm {SCV}$ of the most concentrated CME-R of order
$\mathrm {SCV}$ of the most concentrated CME-R of order 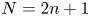 $N=2n+1$ is less than
$N=2n+1$ is less than 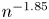 $n^{-1.85}$. We also discuss how CME-R can be used for numerical inverse Laplace transformation, which is beneficial when the Laplace transform function is impossible to evaluate at complex points.
$n^{-1.85}$. We also discuss how CME-R can be used for numerical inverse Laplace transformation, which is beneficial when the Laplace transform function is impossible to evaluate at complex points.
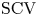
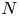
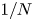
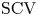
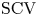
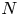
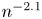
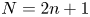
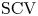
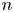
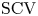
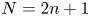
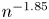
Molecular epidemiology of a familial cluster of SARS-CoV-2 infection during lockdown period in Sant Kabir Nagar, Uttar Pradesh, India
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 25 August 2021, e200
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On the mixing time of coordinate Hit-and-Run
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 31 / Issue 2 / March 2022
- Published online by Cambridge University Press:
- 25 August 2021, pp. 320-332
-
- Article
- Export citation
-
We obtain a polynomial upper bound on the mixing time
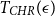 $T_{CHR}(\epsilon)$ of the coordinate Hit-and-Run (CHR) random walk on an
$T_{CHR}(\epsilon)$ of the coordinate Hit-and-Run (CHR) random walk on an 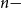 $n-$dimensional convex body, where
$n-$dimensional convex body, where 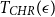 $T_{CHR}(\epsilon)$ is the number of steps needed to reach within
$T_{CHR}(\epsilon)$ is the number of steps needed to reach within  $\epsilon$ of the uniform distribution with respect to the total variation distance, starting from a warm start (i.e., a distribution which has a density with respect to the uniform distribution on the convex body that is bounded above by a constant). Our upper bound is polynomial in n, R and
$\epsilon$ of the uniform distribution with respect to the total variation distance, starting from a warm start (i.e., a distribution which has a density with respect to the uniform distribution on the convex body that is bounded above by a constant). Our upper bound is polynomial in n, R and 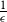 $\frac{1}{\epsilon}$, where we assume that the convex body contains the unit
$\frac{1}{\epsilon}$, where we assume that the convex body contains the unit 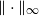 $\Vert\cdot\Vert_\infty$-unit ball
$\Vert\cdot\Vert_\infty$-unit ball 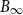 $B_\infty$ and is contained in its R-dilation
$B_\infty$ and is contained in its R-dilation 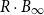 $R\cdot B_\infty$. Whether CHR has a polynomial mixing time has been an open question.
$R\cdot B_\infty$. Whether CHR has a polynomial mixing time has been an open question.
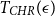
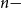
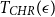

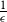
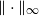
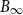
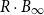
Diagnostic value of interferon-γ release assay in HIV-infected individuals complicated with active tuberculosis: a systematic review and meta-analysis
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 23 August 2021, e204
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Chemical design of onion-like carbon-silicon diimide polymer composites
-
- Journal:
- Experimental Results / Volume 2 / 2021
- Published online by Cambridge University Press:
- 20 August 2021, e27
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Understanding migrants in COVID-19 counting: Rethinking the data-(in)visibility nexus
-
- Journal:
- Data & Policy / Volume 3 / 2021
- Published online by Cambridge University Press:
- 20 August 2021, e18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Epidemiology of tuberculosis in foreign students in Japan, 2015–2019: a comparison with the notification rates in their countries of origin
-
- Journal:
- Epidemiology & Infection / Volume 149 / 2021
- Published online by Cambridge University Press:
- 20 August 2021, e202
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
