Refine search
Actions for selected content:
53179 results in Statistics and Probability
12 - Algorithms
-
- Book:
- Ethics in Econometrics
- Published online:
- 14 November 2024
- Print publication:
- 28 November 2024, pp 269-280
-
- Chapter
- Export citation
Copyright page
-
- Book:
- Ethics in Econometrics
- Published online:
- 14 November 2024
- Print publication:
- 28 November 2024, pp iv-iv
-
- Chapter
- Export citation
Recommended Reading
-
- Book:
- Ethics in Econometrics
- Published online:
- 14 November 2024
- Print publication:
- 28 November 2024, pp xx-xx
-
- Chapter
- Export citation
7 - Spurious Relations
-
- Book:
- Ethics in Econometrics
- Published online:
- 14 November 2024
- Print publication:
- 28 November 2024, pp 161-185
-
- Chapter
- Export citation
6 - Missing Data
-
- Book:
- Ethics in Econometrics
- Published online:
- 14 November 2024
- Print publication:
- 28 November 2024, pp 139-160
-
- Chapter
- Export citation
Index
-
- Book:
- Ethics in Econometrics
- Published online:
- 14 November 2024
- Print publication:
- 28 November 2024, pp 287-288
-
- Chapter
- Export citation
11 - Big Data
-
- Book:
- Ethics in Econometrics
- Published online:
- 14 November 2024
- Print publication:
- 28 November 2024, pp 248-268
-
- Chapter
- Export citation
Understanding to intervene: The codesign of text classifiers with peace practitioners
- Part of
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 27 November 2024, e54
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Community-associated methicillin-resistant Staphylococcus aureus in the Kimberley region of Western Australia, epidemiology and burden on hospitals
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 27 November 2024, e147
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Convolutional kernel-based classification of industrial alarm floods
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 27 November 2024, e30
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Reducing antimicrobial use in livestock alone may be not sufficient to reduce antimicrobial resistance among human Campylobacter infections: an ecological study in the Netherlands
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 27 November 2024, e148
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On the study of the cumulative residual extropy of mixed used systems and their complexity
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 39 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 26 November 2024, pp. 122-140
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Insurance design and arson-type risks
-
- Journal:
- Annals of Actuarial Science / Volume 19 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 26 November 2024, pp. 126-139
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Optimal mixing via tensorization for random independent sets on arbitrary trees
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 2 / March 2025
- Published online by Cambridge University Press:
- 26 November 2024, pp. 259-275
-
- Article
- Export citation
-
We study the mixing time of the single-site update Markov chain, known as the Glauber dynamics, for generating a random independent set of a tree. Our focus is obtaining optimal convergence results for arbitrary trees. We consider the more general problem of sampling from the Gibbs distribution in the hard-core model where independent sets are weighted by a parameter
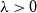 $\lambda \gt 0$; the special case
$\lambda \gt 0$; the special case 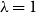 $\lambda =1$ corresponds to the uniform distribution over all independent sets. Previous work of Martinelli, Sinclair and Weitz (2004) obtained optimal mixing time bounds for the complete
$\lambda =1$ corresponds to the uniform distribution over all independent sets. Previous work of Martinelli, Sinclair and Weitz (2004) obtained optimal mixing time bounds for the complete 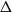 $\Delta$-regular tree for all
$\Delta$-regular tree for all 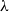 $\lambda$. However, Restrepo, Stefankovic, Vera, Vigoda, and Yang (2014) showed that for sufficiently large
$\lambda$. However, Restrepo, Stefankovic, Vera, Vigoda, and Yang (2014) showed that for sufficiently large 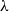 $\lambda$ there are bounded-degree trees where optimal mixing does not hold. Recent work of Eppstein and Frishberg (2022) proved a polynomial mixing time bound for the Glauber dynamics for arbitrary trees, and more generally for graphs of bounded tree-width.
$\lambda$ there are bounded-degree trees where optimal mixing does not hold. Recent work of Eppstein and Frishberg (2022) proved a polynomial mixing time bound for the Glauber dynamics for arbitrary trees, and more generally for graphs of bounded tree-width.We establish an optimal bound on the relaxation time (i.e., inverse spectral gap) of
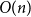 $O(n)$ for the Glauber dynamics for unweighted independent sets on arbitrary trees. We stress that our results hold for arbitrary trees and there is no dependence on the maximum degree
$O(n)$ for the Glauber dynamics for unweighted independent sets on arbitrary trees. We stress that our results hold for arbitrary trees and there is no dependence on the maximum degree 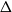 $\Delta$. Interestingly, our results extend (far) beyond the uniqueness threshold which is on the order
$\Delta$. Interestingly, our results extend (far) beyond the uniqueness threshold which is on the order 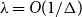 $\lambda =O(1/\Delta )$. Our proof approach is inspired by recent work on spectral independence. In fact, we prove that spectral independence holds with a constant independent of the maximum degree for any tree, but this does not imply mixing for general trees as the optimal mixing results of Chen, Liu, and Vigoda (2021) only apply for bounded-degree graphs. We instead utilize the combinatorial nature of independent sets to directly prove approximate tensorization of variance via a non-trivial inductive proof.
$\lambda =O(1/\Delta )$. Our proof approach is inspired by recent work on spectral independence. In fact, we prove that spectral independence holds with a constant independent of the maximum degree for any tree, but this does not imply mixing for general trees as the optimal mixing results of Chen, Liu, and Vigoda (2021) only apply for bounded-degree graphs. We instead utilize the combinatorial nature of independent sets to directly prove approximate tensorization of variance via a non-trivial inductive proof.
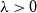
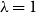
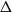
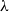
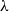
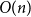
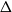
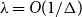
Widths of crossings in Poisson Boolean percolation
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 2 / June 2025
- Published online by Cambridge University Press:
- 26 November 2024, pp. 603-627
- Print publication:
- June 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We answer the following question: if the occupied (or vacant) set of a planar Poisson Boolean percolation model contains a crossing of an
 $n\times n$ square, how wide is this crossing? The answer depends on whether we consider the critical, sub-, or super-critical regime, and is different for the occupied and vacant sets.
$n\times n$ square, how wide is this crossing? The answer depends on whether we consider the critical, sub-, or super-critical regime, and is different for the occupied and vacant sets.

The inconvenient truth of ground truth errors in automotive datasets and DNN-based detection
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 25 November 2024, e34
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A deep operator network for Bayesian parameter identification of self-oscillators
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 25 November 2024, e35
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
AI as a constituted system: accountability lessons from an LLM experiment
- Part of
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 25 November 2024, e57
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Exploring the contributions of open data intermediaries for a sustainable open data ecosystem
- Part of
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 25 November 2024, e56
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Random growth via gradient flow aggregation
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 2 / June 2025
- Published online by Cambridge University Press:
- 25 November 2024, pp. 735-755
- Print publication:
- June 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We introduce gradient flow aggregation, a random growth model. Given existing particles
 $\{x_1,\ldots,x_n\} \subset \mathbb{R}^2$, a new particle arrives from a random direction at
$\{x_1,\ldots,x_n\} \subset \mathbb{R}^2$, a new particle arrives from a random direction at  $\infty$ and flows in direction of the vector field
$\infty$ and flows in direction of the vector field  $\nabla E$ where
$\nabla E$ where  $ E(x) = \sum_{i=1}^{n}{1}/{\|x-x_i\|^{\alpha}}$,
$ E(x) = \sum_{i=1}^{n}{1}/{\|x-x_i\|^{\alpha}}$,  $0 < \alpha < \infty$. The case
$0 < \alpha < \infty$. The case  $\alpha = 0$ refers to the logarithmic energy
$\alpha = 0$ refers to the logarithmic energy  ${-}\sum\log\|x-x_i\|$. Particles stop once they are at distance 1 from one of the existing particles, at which point they are added to the set and remain fixed for all time. We prove, under a non-degeneracy assumption, a Beurling-type estimate which, via Kesten’s method, can be used to deduce sub-ballistic growth for
${-}\sum\log\|x-x_i\|$. Particles stop once they are at distance 1 from one of the existing particles, at which point they are added to the set and remain fixed for all time. We prove, under a non-degeneracy assumption, a Beurling-type estimate which, via Kesten’s method, can be used to deduce sub-ballistic growth for  $0 \leq \alpha < 1$,
$0 \leq \alpha < 1$,  $\text{diam}(\{x_1,\ldots,x_n\}) \leq c_{\alpha} \cdot n^{({3 \alpha +1})/({2\alpha + 2})}$. This is optimal when
$\text{diam}(\{x_1,\ldots,x_n\}) \leq c_{\alpha} \cdot n^{({3 \alpha +1})/({2\alpha + 2})}$. This is optimal when  $\alpha = 0$. The case
$\alpha = 0$. The case  $\alpha = 0$ leads to a ‘round’ full-dimensional tree. The larger the value of
$\alpha = 0$ leads to a ‘round’ full-dimensional tree. The larger the value of  $\alpha$, the sparser the tree. Some instances of the higher-dimensional setting are also discussed.
$\alpha$, the sparser the tree. Some instances of the higher-dimensional setting are also discussed.












