Refine search
Actions for selected content:
53179 results in Statistics and Probability
A GENERAL LIMIT THEORY FOR NONLINEAR FUNCTIONALS OF NONSTATIONARY TIME SERIES
-
- Journal:
- Econometric Theory / Volume 42 / Issue 1 / February 2026
- Published online by Cambridge University Press:
- 25 November 2024, pp. 5-62
-
- Article
-
- You have access
- Open access
- Export citation
Understanding the correlation risk premium
-
- Journal:
- Annals of Actuarial Science / Volume 19 / Issue 2 / July 2025
- Published online by Cambridge University Press:
- 25 November 2024, pp. 233-256
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Identifying stakeholder motivations in normative AI governance: a systematic literature review for research guidance
- Part of
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 25 November 2024, e58
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Experimental Sociology
- Outline of a Scientific Field
-
- Published online:
- 23 November 2024
- Print publication:
- 21 November 2024
A self-driven ESN-DSS approach for effective COVID-19 time series prediction and modelling
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 22 November 2024, e146
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Asymptotics of the allele frequency spectrum and the number of alleles
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 2 / June 2025
- Published online by Cambridge University Press:
- 22 November 2024, pp. 516-540
- Print publication:
- June 2025
-
- Article
- Export citation
-
We derive large-sample and other limiting distributions of components of the allele frequency spectrum vector,
 $\mathbf{M}_n$, joint with the number of alleles,
$\mathbf{M}_n$, joint with the number of alleles,  $K_n$, from a sample of n genes. Models analysed include those constructed from gamma and
$K_n$, from a sample of n genes. Models analysed include those constructed from gamma and  $\alpha$-stable subordinators by Kingman (thus including the Ewens model), the two-parameter extension by Pitman and Yor, and a two-parameter version constructed by omitting large jumps from an
$\alpha$-stable subordinators by Kingman (thus including the Ewens model), the two-parameter extension by Pitman and Yor, and a two-parameter version constructed by omitting large jumps from an  $\alpha$-stable subordinator. In each case the limiting distribution of a finite number of components of
$\alpha$-stable subordinator. In each case the limiting distribution of a finite number of components of  $\mathbf{M}_n$ is derived, joint with
$\mathbf{M}_n$ is derived, joint with  $K_n$. New results include that in the Poisson–Dirichlet case,
$K_n$. New results include that in the Poisson–Dirichlet case,  $\mathbf{M}_n$ and
$\mathbf{M}_n$ and  $K_n$ are asymptotically independent after centering and norming for
$K_n$ are asymptotically independent after centering and norming for  $K_n$, and it is notable, especially for statistical applications, that in other cases the limiting distribution of a finite number of components of
$K_n$, and it is notable, especially for statistical applications, that in other cases the limiting distribution of a finite number of components of  $\mathbf{M}_n$, after centering and an unusual
$\mathbf{M}_n$, after centering and an unusual  $n^{\alpha/2}$ norming, conditional on that of
$n^{\alpha/2}$ norming, conditional on that of  $K_n$, is normal.
$K_n$, is normal.












Should we communicate with the dead to assuage our grief? An Ubuntu perspective on using griefbots
- Part of
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 22 November 2024, e55
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
5 - Experimental Designs and Typologies
- from Part I - The Philosophy and Methodology of Experimentation in Sociology
-
- Book:
- Experimental Sociology
- Published online:
- 23 November 2024
- Print publication:
- 21 November 2024, pp 52-66
-
- Chapter
- Export citation
6 - Some Extensions and Applications of Martingale Theory
-
- Book:
- Probability Theory, An Analytic View
- Published online:
- 07 November 2024
- Print publication:
- 21 November 2024, pp 200-234
-
- Chapter
- Export citation
Appendix B - Advanced Topics in Classification Metrics
- from Appendices
-
- Book:
- Machine Learning Evaluation
- Published online:
- 07 November 2024
- Print publication:
- 21 November 2024, pp 373-386
-
- Chapter
- Export citation
Boxes
-
- Book:
- Introduction to Catastrophe Risk Modelling
- Published online:
- 08 November 2024
- Print publication:
- 21 November 2024, pp xvi-xvi
-
- Chapter
- Export citation
Contents
-
- Book:
- Machine Learning Evaluation
- Published online:
- 07 November 2024
- Print publication:
- 21 November 2024, pp vii-x
-
- Chapter
- Export citation
Tables
-
- Book:
- Introduction to Catastrophe Risk Modelling
- Published online:
- 08 November 2024
- Print publication:
- 21 November 2024, pp xv-xv
-
- Chapter
- Export citation
Contents
-
- Book:
- Probability Theory, An Analytic View
- Published online:
- 07 November 2024
- Print publication:
- 21 November 2024, pp vii-xii
-
- Chapter
- Export citation
Contents
-
- Book:
- Introduction to Catastrophe Risk Modelling
- Published online:
- 08 November 2024
- Print publication:
- 21 November 2024, pp vii-x
-
- Chapter
- Export citation
References
-
- Book:
- Introduction to Catastrophe Risk Modelling
- Published online:
- 08 November 2024
- Print publication:
- 21 November 2024, pp 276-330
-
- Chapter
- Export citation
Regeneration of branching processes with immigration in varying environments
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 21 November 2024, pp. 422-444
- Print publication:
- March 2025
-
- Article
- Export citation
-
We consider linear-fractional branching processes (one-type and two-type) with immigration in varying environments. For
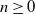 $n\ge0$, let
$n\ge0$, let 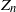 $Z_n$ count the number of individuals of the nth generation, which excludes the immigrant who enters the system at time n. We call n a regeneration time if
$Z_n$ count the number of individuals of the nth generation, which excludes the immigrant who enters the system at time n. We call n a regeneration time if 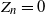 $Z_n=0$. For both the one-type and two-type cases, we give criteria for the finiteness or infiniteness of the number of regeneration times. We then construct some concrete examples to exhibit the strange phenomena caused by the so-called varying environments. For example, it may happen that the process is extinct, but there are only finitely many regeneration times. We also study the asymptotics of the number of regeneration times of the model in the example.
$Z_n=0$. For both the one-type and two-type cases, we give criteria for the finiteness or infiniteness of the number of regeneration times. We then construct some concrete examples to exhibit the strange phenomena caused by the so-called varying environments. For example, it may happen that the process is extinct, but there are only finitely many regeneration times. We also study the asymptotics of the number of regeneration times of the model in the example.
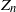
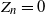
On the smallest gap in a sequence with Poisson pair correlations
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 2 / March 2025
- Published online by Cambridge University Press:
- 21 November 2024, pp. 283-297
-
- Article
- Export citation
-
We prove that any increasing sequence of real numbers with average gap
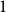 $1$ and Poisson pair correlations has some gap that is at least
$1$ and Poisson pair correlations has some gap that is at least 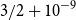 $3/2+10^{-9}$. This improves upon a result of Aistleitner, Blomer, and Radziwiłł.
$3/2+10^{-9}$. This improves upon a result of Aistleitner, Blomer, and Radziwiłł.
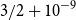
7 - Continuous Parameter Martingales
-
- Book:
- Probability Theory, An Analytic View
- Published online:
- 07 November 2024
- Print publication:
- 21 November 2024, pp 235-263
-
- Chapter
- Export citation
12 - Conclusion
- from Part IV - Evaluation from a Practical Perspective
-
- Book:
- Machine Learning Evaluation
- Published online:
- 07 November 2024
- Print publication:
- 21 November 2024, pp 342-358
-
- Chapter
- Export citation
