Refine search
Actions for selected content:
129 results
4 - Interlude: Probability, Likelihood and Bayes
-
- Book:
- Inference in Statistical Modelling and Machine Learning
- Published online:
- 22 May 2026
- Print publication:
- 23 July 2026, pp 36-40
-
- Chapter
- Export citation
Chapter 8 - Encoding Knowledge
-
- Book:
- How Data Need People
- Published online:
- 29 May 2026
- Print publication:
- 18 June 2026, pp 204-231
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
Chapter 7 - Thinking
-
- Book:
- The Waning of Wisdom
- Published online:
- 23 April 2026
- Print publication:
- 07 May 2026, pp 148-189
-
- Chapter
- Export citation
Bayesian combination of correlated subjective probability estimates
-
- Journal:
- Judgment and Decision Making / Volume 21 / 2026
- Published online by Cambridge University Press:
- 05 May 2026, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

The Waning of Wisdom
- The Psychology of Reasoning in the Post-Truth Era
-
- Published online:
- 23 April 2026
- Print publication:
- 07 May 2026
A computational approach to investigating phonological complexity with latent variables and dimensionality reduction
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Embedded model form uncertainty quantification with measurement noise for Bayesian model calibration
-
- Journal:
- Data-Centric Engineering / Volume 7 / 2026
- Published online by Cambridge University Press:
- 23 February 2026, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The effects of fiscal policy shocks: evidence from a Bayesian SVAR model with uncertain identifying assumptions
-
- Journal:
- Macroeconomic Dynamics / Volume 30 / 2026
- Published online by Cambridge University Press:
- 29 January 2026, e4
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We explore the effects of fiscal policy shocks on aggregate output and inflation. We use the Bayesian econometric methodology of Baumeister and Hamilton applied to the fiscal structural vector autoregressive model to evaluate key elasticities and fiscal multipliers using U.S. data. In our baseline specification that ends before Covid pandemic, the government spending multiplier is equal to approximately
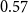 $0.57$ and tax multiplier is approximately
$0.57$ and tax multiplier is approximately 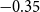 $-0.35$ after one year. The short-term output elasticity of government spending is statistically insignificant and the output elasticity of taxes is approximately equal to
$-0.35$ after one year. The short-term output elasticity of government spending is statistically insignificant and the output elasticity of taxes is approximately equal to 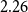 $2.26$.
$2.26$.
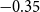
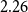
Actively inferring methane sources with drones
- Part of
-
- Journal:
- Environmental Data Science / Volume 5 / 2026
- Published online by Cambridge University Press:
- 28 January 2026, e2
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Shiny-MAGEC: A Bayesian R shiny application for meta-analysis of censored adverse events
-
- Journal:
- Research Synthesis Methods / Volume 17 / Issue 2 / March 2026
- Published online by Cambridge University Press:
- 24 November 2025, pp. 378-388
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
5 - Statistical Inference and Experimental Data Analysis
-
- Book:
- Probability Theory for Quantitative Scientists
- Published online:
- 24 July 2025
- Print publication:
- 14 August 2025, pp 117-160
-
- Chapter
- Export citation

Probability Theory for Quantitative Scientists
-
- Published online:
- 24 July 2025
- Print publication:
- 14 August 2025
A Bayesian framework to investigate radiation reaction in strong fields
-
- Journal:
- High Power Laser Science and Engineering / Volume 13 / 2025
- Published online by Cambridge University Press:
- 08 May 2025, e25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Market-based insurance ratemaking: Application to pet insurance
- Part of
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 55 / Issue 2 / May 2025
- Published online by Cambridge University Press:
- 11 April 2025, pp. 263-286
- Print publication:
- May 2025
-
- Article
- Export citation
Bayesian reasoning for qualitative replication analysis: Examples from climate politics
-
- Journal:
- Political Science Research and Methods / Volume 14 / Issue 2 / April 2026
- Published online by Cambridge University Press:
- 07 April 2025, pp. 414-429
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Chapter 16 - Probabilistic Beliefs about the State of the World
- from Part III - Mathematical Theories
-
- Book:
- Looking Ahead
- Published online:
- 20 March 2025
- Print publication:
- 06 March 2025, pp 174-187
-
- Chapter
- Export citation
Simulation-based inference of surface accumulation and basal melt rates of an Antarctic ice shelf from isochronal layers
-
- Journal:
- Journal of Glaciology / Volume 71 / 2025
- Published online by Cambridge University Press:
- 27 February 2025, e44
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Adding Regularized Horseshoes to the Dynamics of Latent Variable Models
-
- Journal:
- Political Analysis / Volume 33 / Issue 2 / April 2025
- Published online by Cambridge University Press:
- 17 January 2025, pp. 171-177
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Scalable data assimilation with message passing
- Part of
-
- Journal:
- Environmental Data Science / Volume 4 / 2025
- Published online by Cambridge University Press:
- 08 January 2025, e1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
