Refine search
Actions for selected content:
115 results
9 - Uniformity and Diversity at the Same Time?
- from Section 2 - Usage Variation amid Social Diversity and Political Change
-
-
- Book:
- Worldwide Perspectives on English Usage
- Published online:
- 25 June 2026
- Print publication:
- 16 July 2026, pp 228-246
-
- Chapter
- Export citation
Logic-Guided Data Extraction with Answer Set Programming and Large Language Models
-
- Journal:
- Theory and Practice of Logic Programming , First View
- Published online by Cambridge University Press:
- 08 July 2026, pp. 1-18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ProDebug: An Automated Debugging System for Prolog
-
- Journal:
- Theory and Practice of Logic Programming , First View
- Published online by Cambridge University Press:
- 06 July 2026, pp. 1-16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Responsible NLP: Why performance is no longer enough
-
- Journal:
- Natural Language Processing ,
- Published online by Cambridge University Press:
- 29 June 2026, pp. 1-7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
3 - Behavioural Data Science
- from Part I - Introduction to Behavioural Data Science
-
-
- Book:
- The Cambridge Handbook of Behavioural Data Science
- Published online:
- 29 May 2026
- Print publication:
- 18 June 2026, pp 44-58
-
- Chapter
- Export citation
Introduction
-
- Book:
- Translate
- Published online:
- 15 May 2026
- Print publication:
- 11 June 2026, pp 1-11
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
A Framework to Assess the Persuasion Risks Large Language Model Chatbots Pose to Democratic Societies
-
- Journal:
- Journal of Experimental Political Science , First View
- Published online by Cambridge University Press:
- 04 June 2026, pp. 1-14
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

The Cambridge Handbook of Behavioural Data Science
-
- Published online:
- 29 May 2026
- Print publication:
- 18 June 2026

Translate
- Multilingual Access to Critical Services in the Age of AI
-
- Published online:
- 15 May 2026
- Print publication:
- 11 June 2026
-
- Book
-
- You have access
- Open access
- Export citation
Messy data, low-resource languages, and LLMs: Narrative analysis of pre-modern Slavic Lives of Saints
-
- Journal:
- Computational Humanities Research / Volume 2 / 2026
- Published online by Cambridge University Press:
- 12 May 2026, e13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Chapter 7 - Some Reflections on Language Games … and ChatGPT
-
-
- Book:
- Interpreting Sellars
- Published online:
- 23 April 2026
- Print publication:
- 07 May 2026, pp 140-153
-
- Chapter
- Export citation
Chapter 15 - Utopia or Dystopia?
- from Part VII - Conclusion and Outlook
-
- Book:
- The Perks of Being a Bookworm
- Published online:
- 23 April 2026
- Print publication:
- 07 May 2026, pp 202-217
-
- Chapter
- Export citation
The attribution crisis in LLM search results: Estimating ecosystem exploitation
-
- Journal:
- Data & Policy / Volume 8 / 2026
- Published online by Cambridge University Press:
- 28 April 2026, e15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
How reliable are retrieval-augmented and standard ChatGPT models to support flood susceptibility mapping?
-
- Journal:
- Environmental Data Science / Volume 5 / 2026
- Published online by Cambridge University Press:
- 21 April 2026, e10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
High-Dimensional Perception with the Double Machine Learning Lens Model
- Part of
-
- Journal:
- Psychometrika / Volume 91 / Issue 3 / June 2026
- Published online by Cambridge University Press:
- 21 April 2026, pp. 889-920
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Traditional perceptual models are ill-equipped for the high-dimensional data, such as text embeddings, central to modern psychology and AI. We introduce the double machine learning lens model, a framework that utilizes machine learning to handle such data. We applied this model to analyze how a modern AI and human perceivers judge social class from 9,513 aspirational essays written by 11-year-olds in 1969. A systematic comparison of 45 analytical approaches revealed that regularized linear models using dimensionality-reduced language embeddings significantly outperformed traditional dictionary-based methods and more complex non-linear models. Our top model accurately predicted human $(R^{2}_{CV} =0.61)$
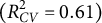 and AI $(R^{2}_{CV} =0.56)$
and AI $(R^{2}_{CV} =0.56)$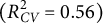 social class perceptions, capturing over 85% of the total accuracy. These results suggest that “unmodeled knowledge” in perception may be an artifact of insufficient measurement tools rather than an unmeasurable intuitive process. We find that both AI and humans use many of the same textual cues (e.g., grammar, occupations, and cultural activities), only a subset of which are valid. Both appear to amplify subtle, real-world patterns into powerful, yet potentially discriminatory heuristics, where a small difference in actual social class creates a large difference in perception.
social class perceptions, capturing over 85% of the total accuracy. These results suggest that “unmodeled knowledge” in perception may be an artifact of insufficient measurement tools rather than an unmeasurable intuitive process. We find that both AI and humans use many of the same textual cues (e.g., grammar, occupations, and cultural activities), only a subset of which are valid. Both appear to amplify subtle, real-world patterns into powerful, yet potentially discriminatory heuristics, where a small difference in actual social class creates a large difference in perception.
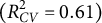
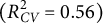
Prompt engineering of large language models for paper screening in medical meta-analyses and systematic reviews: A prospective comparative study
-
- Journal:
- Research Synthesis Methods ,
- Published online by Cambridge University Press:
- 14 April 2026, pp. 1-18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
9 - Broader Implications and Future Directions
-
- Book:
- The Economics of Language
- Published online:
- 27 March 2026
- Print publication:
- 09 April 2026, pp 308-332
-
- Chapter
- Export citation
8 - The Role of Large Language Models
-
- Book:
- The Economics of Language
- Published online:
- 27 March 2026
- Print publication:
- 09 April 2026, pp 275-307
-
- Chapter
- Export citation
Bending the Rules: On Large Language Models and Content Moderation
-
- Journal:
- Israel Law Review / Volume 59 / Issue 1 / March 2026
- Published online by Cambridge University Press:
- 06 April 2026, pp. 96-133
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Evaluating the performance of large language models in taxonomic classification of questions in verbal protocols of design
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
