Refine search
Actions for selected content:
156 results
20 - The English of the Falkland Islands
- from Part III - The South Atlantic
-
-
- Book:
- The New Cambridge History of the English Language
- Published online:
- 22 April 2026
- Print publication:
- 07 May 2026, pp 604-635
-
- Chapter
- Export citation
34 - Revisiting Rhythm in Romance Languages
- from Section 5 - Rhythm across Languages
-
-
- Book:
- Rhythms of Speech and Language
- Published online:
- 23 April 2026
- Print publication:
- 07 May 2026, pp 610-626
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
Resumption in clitic left dislocation: An experimental study of Peninsular and Rioplatense Spanish
-
- Journal:
- Journal of Linguistics , First View
- Published online by Cambridge University Press:
- 22 April 2026, pp. 1-22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
12 - Why Linguistics Matters to Second Language Teaching in K-12
-
-
- Book:
- Linguistic Foundations for Second Language Teaching and Learning
- Published online:
- 07 February 2026
- Print publication:
- 05 March 2026, pp 229-247
-
- Chapter
- Export citation
13 - Why Teach Linguistics to L2 Learners? Evidence from the Western Washington University Spanish Language Program
-
-
- Book:
- Linguistic Foundations for Second Language Teaching and Learning
- Published online:
- 07 February 2026
- Print publication:
- 05 March 2026, pp 248-266
-
- Chapter
- Export citation
6 - Why Morphosyntax Matters to Second Language Teaching and Learning
-
-
- Book:
- Linguistic Foundations for Second Language Teaching and Learning
- Published online:
- 07 February 2026
- Print publication:
- 05 March 2026, pp 119-138
-
- Chapter
- Export citation
Evaluating GPT-generated feedback for beginning-level Spanish writing: An exploratory study
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
15 - Arthur in Latin America
- from Part I - Post-Medieval Arthurs in Literature and Culture
-
-
- Book:
- The Cambridge History of Arthurian Literature and Culture
- Published online:
- 12 January 2026
- Print publication:
- 19 February 2026, pp 327-345
-
- Chapter
- Export citation
Metathesis, syllable weight and stress in Sevillian Spanish
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This study investigates how stress and metathesis interact in Sevillian Spanish, focusing on how their interaction sheds light on representation. Metathesis affects /s/–voiceless stop sequences, moving a debuccalised coda /s/ to the release of the following stop (
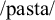 → [patha]). This process plausibly changes syllable structure: the syllable where /s/ originated is closed at one representational level, but open on the surface ([pah.ta] → [pa.tha]). The change in syllable structure could affect weight-sensitive stress, depending on the level speakers refer to in assigning stress. In a stress judgement task, Sevillian listeners treated syllables from which an /s/ had metathesised out similarly to heavy penults and differently from light penults. I outline a range of analyses to account for their behaviour, and suggest that a comprehensive analysis could include gestural representations and separate stress from metathesis, so that phonetic variability in the realisation of metathesis is permitted but does not affect stress.
→ [patha]). This process plausibly changes syllable structure: the syllable where /s/ originated is closed at one representational level, but open on the surface ([pah.ta] → [pa.tha]). The change in syllable structure could affect weight-sensitive stress, depending on the level speakers refer to in assigning stress. In a stress judgement task, Sevillian listeners treated syllables from which an /s/ had metathesised out similarly to heavy penults and differently from light penults. I outline a range of analyses to account for their behaviour, and suggest that a comprehensive analysis could include gestural representations and separate stress from metathesis, so that phonetic variability in the realisation of metathesis is permitted but does not affect stress.
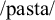 → [patha]). This process plausibly changes syllable structure: the syllable where /s/ originated is closed at one representational level, but open on the surface ([
→ [patha]). This process plausibly changes syllable structure: the syllable where /s/ originated is closed at one representational level, but open on the surface ([Lexical distributions of Spanish dialects and their processing implications for Chilean Spanish
-
- Journal:
- Bilingualism: Language and Cognition , First View
- Published online by Cambridge University Press:
- 15 January 2026, pp. 1-21
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Referential choice in L2 English: Comparing L1 Spanish and L1 Dutch speakers
-
- Journal:
- Applied Psycholinguistics / Volume 46 / 2025
- Published online by Cambridge University Press:
- 15 December 2025, e46
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
3 - The Use of Humour as an Affiliative Strategy in Times of Covid
- from I - Emotion and Evaluation
-
-
- Book:
- The Sociopragmatics of Emotion
- Published online:
- 02 March 2026
- Print publication:
- 25 September 2025, pp 66-94
-
- Chapter
- Export citation
6 - Language Ideologies of Belonging
- from Part II - Constructing Languages through Discourses on Belonging, Prestige, and Materiality
-
- Book:
- Liquid Languages
- Published online:
- 28 July 2025
- Print publication:
- 14 August 2025, pp 93-125
-
- Chapter
- Export citation
Predictive processing can override perceptual information: evidence from Spanish object relative clauses
-
- Journal:
- Language and Cognition / Volume 17 / 2025
- Published online by Cambridge University Press:
- 25 July 2025, e59
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Cross-language interactions of phonetic and phonological processes: Intervocalic plosive lenition in Afrikaans-Spanish bilinguals
-
- Journal:
- Studies in Second Language Acquisition / Volume 47 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 30 January 2025, pp. 257-281
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
