Refine listing
Actions for selected content:
32 results in ACL/NAACL Journal Article Collection
Morphosyntactic probing of multilingual BERT models
-
- Journal:
- Natural Language Engineering / Volume 30 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 25 May 2023, pp. 753-792
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
smProbLog: Stable Model Semantics in ProbLog for Probabilistic Argumentation
-
- Journal:
- Theory and Practice of Logic Programming / Volume 23 / Issue 6 / November 2023
- Published online by Cambridge University Press:
- 25 May 2023, pp. 1198-1247
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Multimodal-ish: prosodic and kinesic aspects of bounded and free uses of ish
-
- Journal:
- Language and Cognition / Volume 16 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 24 May 2023, pp. 1-31
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Plot extraction and the visualization of narrative flow
-
- Journal:
- Natural Language Engineering / Volume 30 / Issue 3 / May 2024
- Published online by Cambridge University Press:
- 23 May 2023, pp. 480-524
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Beyond the conservative hypothesis: a meta-analysis of lexical-semantic processing in Williams syndrome
-
- Journal:
- Language and Cognition / Volume 15 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 17 May 2023, pp. 526-550
-
- Article
- Export citation
The statistical mechanics of felt uncertainty under active inference
-
- Journal:
- Behavioral and Brain Sciences / Volume 46 / 2023
- Published online by Cambridge University Press:
- 08 May 2023, e108
-
- Article
- Export citation
Making the unconscious conscious: Developing maladaptive scripts into conviction narratives
-
- Journal:
- Behavioral and Brain Sciences / Volume 46 / 2023
- Published online by Cambridge University Press:
- 08 May 2023, e107
-
- Article
- Export citation
Percolation in simple directed random graphs with a given degree distribution
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 2 / April 2024
- Published online by Cambridge University Press:
- 05 May 2023, pp. 268-289
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study site and bond percolation in simple directed random graphs with a given degree distribution. We derive the percolation threshold for the giant strongly connected component and the fraction of vertices in this component as a function of the percolation probability. The results are obtained for degree sequences in which the maximum degree may depend on the total number of nodes n, being asymptotically bounded by
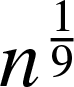 $n^{\frac{1}{9}}$.
$n^{\frac{1}{9}}$.
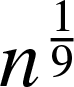
The Development And Applications Of Augmented And Virtual Reality Technology In Spine Surgery Training: A Systematic Review
-
- Journal:
- Canadian Journal of Neurological Sciences / Volume 51 / Issue 2 / March 2024
- Published online by Cambridge University Press:
- 28 April 2023, pp. 255-264
-
- Article
-
- You have access
- HTML
- Export citation
Examining the impact of schizotypal personality traits on event-related potential (ERP) indexes of sensory gating in a healthy population
-
- Journal:
- Personality Neuroscience / Volume 6 / 2023
- Published online by Cambridge University Press:
- 27 April 2023, e4
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Distributed Subweb Specifications for Traversing the Web
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 2 / March 2024
- Published online by Cambridge University Press:
- 25 April 2023, pp. 394-420
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
MODULAR MANY-VALUED SEMANTICS FOR COMBINED LOGICS
- Part of
-
- Journal:
- The Journal of Symbolic Logic / Volume 89 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 20 April 2023, pp. 583-636
- Print publication:
- June 2024
-
- Article
- Export citation
COMPUTABLE PRESENTATIONS OF C*-ALGEBRAS
- Part of
-
- Journal:
- The Journal of Symbolic Logic / Volume 89 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 20 April 2023, pp. 1313-1338
- Print publication:
- September 2024
-
- Article
- Export citation
Segregated mobility patterns amplify neighborhood disparities in the spread of COVID-19
-
- Journal:
- Network Science / Volume 11 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 17 April 2023, pp. 411-430
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The syntactic flexibility of German and English idioms: Evidence from acceptability rating experiments
-
- Journal:
- Journal of Linguistics / Volume 60 / Issue 2 / April 2024
- Published online by Cambridge University Press:
- 14 April 2023, pp. 431-468
- Print publication:
- April 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Attack of the snowclones: A corpus-based analysis of extravagant formulaic patterns
-
- Journal:
- Journal of Linguistics / Volume 60 / Issue 3 / August 2024
- Published online by Cambridge University Press:
- 14 April 2023, pp. 599-634
- Print publication:
- August 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The effectiveness of automatic speech recognition in ESL/EFL pronunciation: A meta-analysis
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Stochastic comparisons of largest claim and aggregate claim amounts
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 2 / April 2024
- Published online by Cambridge University Press:
- 04 April 2023, pp. 245-267
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Direct to Angiosuite in Acute Stroke with Mobile Stroke Unit
- Part of
-
- Journal:
- Canadian Journal of Neurological Sciences / Volume 51 / Issue 2 / March 2024
- Published online by Cambridge University Press:
- 29 March 2023, pp. 226-232
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
