Refine search
Actions for selected content:
48290 results in Computer Science
How best to improve upon return-to-player information in gambling? A comparison of two approaches in an Australian sample
-
- Journal:
- Experimental Results / Volume 3 / 2022
- Published online by Cambridge University Press:
- 27 September 2022, e20
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A spatiotemporal stochastic climate model for benchmarking causal discovery methods for teleconnections
-
- Journal:
- Environmental Data Science / Volume 1 / 2022
- Published online by Cambridge University Press:
- 27 September 2022, e12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Potential interactions between metal-based phenanthroline drugs and the unfolded protein response endoplasmic reticulum stress pathway
-
- Journal:
- Experimental Results / Volume 3 / 2022
- Published online by Cambridge University Press:
- 26 September 2022, e22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

The Science of Deep Learning
-
- Published online:
- 23 September 2022
- Print publication:
- 18 August 2022
-
- Textbook
- Export citation
NWS volume 10 issue 3 Cover and Front matter
-
- Journal:
- Network Science / Volume 10 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 23 September 2022, pp. f1-f3
-
- Article
-
- You have access
- Export citation
Irregular subgraphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 2 / March 2023
- Published online by Cambridge University Press:
- 23 September 2022, pp. 269-283
-
- Article
- Export citation
-
We suggest two related conjectures dealing with the existence of spanning irregular subgraphs of graphs. The first asserts that any
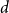 $d$-regular graph on
$d$-regular graph on  $n$ vertices contains a spanning subgraph in which the number of vertices of each degree between
$n$ vertices contains a spanning subgraph in which the number of vertices of each degree between 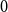 $0$ and
$0$ and 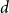 $d$ deviates from
$d$ deviates from 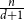 $\frac{n}{d+1}$ by at most
$\frac{n}{d+1}$ by at most 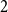 $2$. The second is that every graph on
$2$. The second is that every graph on  $n$ vertices with minimum degree
$n$ vertices with minimum degree 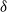 $\delta$ contains a spanning subgraph in which the number of vertices of each degree does not exceed
$\delta$ contains a spanning subgraph in which the number of vertices of each degree does not exceed 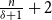 $\frac{n}{\delta +1}+2$. Both conjectures remain open, but we prove several asymptotic relaxations for graphs with a large number of vertices
$\frac{n}{\delta +1}+2$. Both conjectures remain open, but we prove several asymptotic relaxations for graphs with a large number of vertices  $n$. In particular we show that if
$n$. In particular we show that if 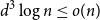 $d^3 \log n \leq o(n)$ then every
$d^3 \log n \leq o(n)$ then every 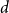 $d$-regular graph with
$d$-regular graph with  $n$ vertices contains a spanning subgraph in which the number of vertices of each degree between
$n$ vertices contains a spanning subgraph in which the number of vertices of each degree between 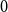 $0$ and
$0$ and 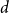 $d$ is
$d$ is 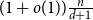 $(1+o(1))\frac{n}{d+1}$. We also prove that any graph with
$(1+o(1))\frac{n}{d+1}$. We also prove that any graph with  $n$ vertices and minimum degree
$n$ vertices and minimum degree 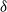 $\delta$ contains a spanning subgraph in which no degree is repeated more than
$\delta$ contains a spanning subgraph in which no degree is repeated more than 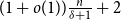 $(1+o(1))\frac{n}{\delta +1}+2$ times.
$(1+o(1))\frac{n}{\delta +1}+2$ times.
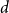

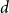
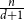
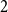

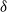
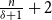

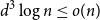
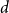

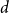
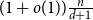

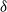
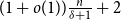
Extreme Behaviors of the Tail Gini-Type Variability Measures
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 4 / October 2023
- Published online by Cambridge University Press:
- 23 September 2022, pp. 928-942
-
- Article
- Export citation
-
For a bivariate random vector
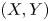 $(X, Y)$, suppose
$(X, Y)$, suppose 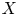 $X$ is some interesting loss variable and
$X$ is some interesting loss variable and 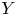 $Y$ is a benchmark variable. This paper proposes a new variability measure called the joint tail-Gini functional, which considers not only the tail event of benchmark variable
$Y$ is a benchmark variable. This paper proposes a new variability measure called the joint tail-Gini functional, which considers not only the tail event of benchmark variable 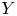 $Y$, but also the tail information of
$Y$, but also the tail information of 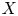 $X$ itself. It can be viewed as a class of tail Gini-type variability measures, which also include the recently proposed tail-Gini functional. It is a challenging and interesting task to measure the tail variability of
$X$ itself. It can be viewed as a class of tail Gini-type variability measures, which also include the recently proposed tail-Gini functional. It is a challenging and interesting task to measure the tail variability of 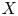 $X$ under some extreme scenarios of the variables by extending the Gini's methodology, and the two tail variability measures can serve such a purpose. We study the asymptotic behaviors of these tail Gini-type variability measures, including tail-Gini and joint tail-Gini functionals. The paper conducts this study under both tail dependent and tail independent cases, which are modeled by copulas with so-called tail order property. Some examples are also shown to illuminate our results. In particular, a generalization of the joint tail-Gini functional is considered to provide a more flexible version.
$X$ under some extreme scenarios of the variables by extending the Gini's methodology, and the two tail variability measures can serve such a purpose. We study the asymptotic behaviors of these tail Gini-type variability measures, including tail-Gini and joint tail-Gini functionals. The paper conducts this study under both tail dependent and tail independent cases, which are modeled by copulas with so-called tail order property. Some examples are also shown to illuminate our results. In particular, a generalization of the joint tail-Gini functional is considered to provide a more flexible version.
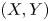
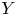
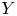
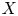
A randomized prospective study of a hybrid rule- and data-driven virtual patient
-
- Journal:
- Natural Language Engineering / Volume 30 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 23 September 2022, pp. 31-72
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Preservation properties of some reliability classes by lifetimes of coherent and mixed systems and their signatures
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 4 / October 2023
- Published online by Cambridge University Press:
- 23 September 2022, pp. 943-960
-
- Article
- Export citation

Real World OCaml: Functional Programming for the Masses
-
- Published online:
- 22 September 2022
- Print publication:
- 13 October 2022
-
- Book
-
- You have access
- Open access
- Export citation
Introduction to the Collection of Papers Celebrating the 20th Anniversary of TPLP
-
- Journal:
- Theory and Practice of Logic Programming / Volume 22 / Issue 6 / November 2022
- Published online by Cambridge University Press:
- 22 September 2022, pp. 770-775
-
- Article
-
- You have access
- HTML
- Export citation
A scalable species-based genetic algorithm for reinforcement learning problems
-
- Journal:
- The Knowledge Engineering Review / Volume 37 / 2022
- Published online by Cambridge University Press:
- 19 September 2022, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Indexed and fibered structures for partial and total correctness assertions
-
- Journal:
- Mathematical Structures in Computer Science / Volume 32 / Issue 9 / October 2022
- Published online by Cambridge University Press:
- 19 September 2022, pp. 1145-1175
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Distribution-based packet forwarding distance dissimilarity learning for topology characterizing in geographic routing
-
- Journal:
- Experimental Results / Volume 3 / 2022
- Published online by Cambridge University Press:
- 19 September 2022, e19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On Establishing Robust Consistency in Answer Set Programs
-
- Journal:
- Theory and Practice of Logic Programming / Volume 23 / Issue 5 / September 2023
- Published online by Cambridge University Press:
- 19 September 2022, pp. 1094-1127
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Answer set programs used in real-world applications often require that the program is usable with different input data. This, however, can often lead to contradictory statements and consequently to an inconsistent program. Causes for potential contradictions in a program are conflicting rules. In this paper, we show how to ensure that a program
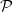 $\mathcal{P}$ remains non-contradictory given any allowed set of such input data. For that, we introduce the notion of conflict-resolving
$\mathcal{P}$ remains non-contradictory given any allowed set of such input data. For that, we introduce the notion of conflict-resolving 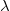 ${\lambda}$-extensions. A conflict-resolving
${\lambda}$-extensions. A conflict-resolving 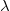 ${\lambda}$-extension for a conflicting rule r is a set
${\lambda}$-extension for a conflicting rule r is a set 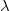 ${\lambda}$ of (default) literals such that extending the body of r by
${\lambda}$ of (default) literals such that extending the body of r by 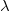 ${\lambda}$ resolves all conflicts of r at once. We investigate the properties that suitable
${\lambda}$ resolves all conflicts of r at once. We investigate the properties that suitable 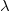 ${\lambda}$-extensions should possess and building on that, we develop a strategy to compute all such conflict-resolving
${\lambda}$-extensions should possess and building on that, we develop a strategy to compute all such conflict-resolving 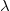 ${\lambda}$-extensions for each conflicting rule in
${\lambda}$-extensions for each conflicting rule in 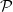 $\mathcal{P}$. We show that by implementing a conflict resolution process that successively resolves conflicts using
$\mathcal{P}$. We show that by implementing a conflict resolution process that successively resolves conflicts using 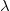 ${\lambda}$-extensions eventually yields a program that remains non-contradictory given any allowed set of input data.
${\lambda}$-extensions eventually yields a program that remains non-contradictory given any allowed set of input data.
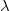
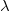
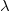
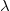
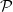
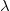
Negative attitudes toward older adults: Subjective time to become older and “stereotype embodiment theory”-based intervention
-
- Journal:
- Experimental Results / Volume 3 / 2022
- Published online by Cambridge University Press:
- 19 September 2022, e21
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
All that glitters is not gold: Relational events models with spurious events
-
- Journal:
- Network Science / Volume 11 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 16 September 2022, pp. 184-204
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
