Refine search
Actions for selected content:
48533 results in Computer Science
Trusts, co-ops, and crowd workers: Could we include crowd data workers as stakeholders in data trust design?
-
- Journal:
- Data & Policy / Volume 2 / 2020
- Published online by Cambridge University Press:
- 22 December 2020, e20
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
WHAT IS A RULE OF INFERENCE?
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 14 / Issue 2 / June 2021
- Published online by Cambridge University Press:
- 21 December 2020, pp. 307-346
- Print publication:
- June 2021
-
- Article
- Export citation
-
We explore the problems that confront any attempt to explain or explicate exactly what a primitive logical rule of inference is, or consists in. We arrive at a proposed solution that places a surprisingly heavy load on the prospect of being able to understand and deal with specifications of rules that are essentially self-referring. That is, any rule
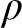 $\rho $ is to be understood via a specification that involves, embedded within it, reference to rule
$\rho $ is to be understood via a specification that involves, embedded within it, reference to rule 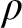 $\rho $ itself. Just how we arrive at this position is explained by reference to familiar rules as well as less familiar ones with unusual features. An inquiry of this kind is surprisingly absent from the foundations of inferentialism—the view that meanings of expressions (especially logical ones) are to be characterized by the rules of inference that govern them.
$\rho $ itself. Just how we arrive at this position is explained by reference to familiar rules as well as less familiar ones with unusual features. An inquiry of this kind is surprisingly absent from the foundations of inferentialism—the view that meanings of expressions (especially logical ones) are to be characterized by the rules of inference that govern them.
BINARY KRIPKE SEMANTICS FOR A STRONG LOGIC FOR NAIVE TRUTH
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 15 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 21 December 2020, pp. 668-692
- Print publication:
- September 2022
-
- Article
- Export citation
-
I show that the logic
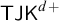 $\textsf {TJK}^{d+}$, one of the strongest logics currently known to support the naive theory of truth, is obtained from the Kripke semantics for constant domain intuitionistic logic by (i) dropping the requirement that the accessibility relation is reflexive and (ii) only allowing reflexive worlds to serve as counterexamples to logical consequence. In addition, I provide a simplified natural deduction system for
$\textsf {TJK}^{d+}$, one of the strongest logics currently known to support the naive theory of truth, is obtained from the Kripke semantics for constant domain intuitionistic logic by (i) dropping the requirement that the accessibility relation is reflexive and (ii) only allowing reflexive worlds to serve as counterexamples to logical consequence. In addition, I provide a simplified natural deduction system for  $\textsf {TJK}^{d+}$, in which a restricted form of conditional proof is used to establish conditionals.
$\textsf {TJK}^{d+}$, in which a restricted form of conditional proof is used to establish conditionals.

CLOUD STORAGE FACILITY AS A FLUID QUEUE CONTROLLED BY MARKOVIAN QUEUE
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 2 / April 2022
- Published online by Cambridge University Press:
- 21 December 2020, pp. 237-253
-
- Article
- Export citation

An Introduction to Symbolic Dynamics and Coding
-
- Published online:
- 19 December 2020
- Print publication:
- 21 January 2021
Motion Adaptation Based on Learning the Manifold of Task and Dynamic Movement Primitive Parameters
-
- Article
-
- You have access
- Open access
- Export citation
AIE volume 34 issue 4 Cover and Front matter
-
- Article
-
- You have access
- Export citation
Cycle partitions of regular graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 4 / July 2021
- Published online by Cambridge University Press:
- 18 December 2020, pp. 526-549
-
- Article
- Export citation
-
Magnant and Martin conjectured that the vertex set of any d-regular graph G on n vertices can be partitioned into
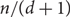 $n / (d+1)$ paths (there exists a simple construction showing that this bound would be best possible). We prove this conjecture when
$n / (d+1)$ paths (there exists a simple construction showing that this bound would be best possible). We prove this conjecture when 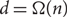 $d = \Omega(n)$, improving a result of Han, who showed that in this range almost all vertices of G can be covered by
$d = \Omega(n)$, improving a result of Han, who showed that in this range almost all vertices of G can be covered by 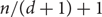 $n / (d+1) + 1$ vertex-disjoint paths. In fact our proof gives a partition of V(G) into cycles. We also show that, if $d = \Omega(n)$ and G is bipartite, then V(G) can be partitioned into n/(2d) paths (this bound is tight for bipartite graphs).
$n / (d+1) + 1$ vertex-disjoint paths. In fact our proof gives a partition of V(G) into cycles. We also show that, if $d = \Omega(n)$ and G is bipartite, then V(G) can be partitioned into n/(2d) paths (this bound is tight for bipartite graphs).
AIE volume 34 issue 4 Cover and Back matter
-
- Article
-
- You have access
- Export citation
Dynamic game semantics
-
- Journal:
- Mathematical Structures in Computer Science / Volume 30 / Issue 8 / September 2020
- Published online by Cambridge University Press:
- 18 December 2020, pp. 892-951
-
- Article
- Export citation

Beyond the Worst-Case Analysis of Algorithms
-
- Published online:
- 17 December 2020
- Print publication:
- 14 January 2021
11 - A Dialogical Account of Proofs in Mathematical Practice
- from Part III - Deduction and Cognition
-
- Book:
- The Dialogical Roots of Deduction
- Published online:
- 10 December 2020
- Print publication:
- 17 December 2020, pp 205-233
-
- Chapter
- Export citation
8 - Shortest Paths
-
- Book:
- Competitive Programming in Python
- Published online:
- 03 December 2020
- Print publication:
- 17 December 2020, pp 124-137
-
- Chapter
- Export citation
15 - Exhaustive Search
-
- Book:
- Competitive Programming in Python
- Published online:
- 03 December 2020
- Print publication:
- 17 December 2020, pp 227-244
-
- Chapter
- Export citation
Conclusions
- from Part III - Deduction and Cognition
-
- Book:
- The Dialogical Roots of Deduction
- Published online:
- 10 December 2020
- Print publication:
- 17 December 2020, pp 234-237
-
- Chapter
- Export citation
10 - Trees
-
- Book:
- Competitive Programming in Python
- Published online:
- 03 December 2020
- Print publication:
- 17 December 2020, pp 171-181
-
- Chapter
- Export citation
Debugging tool
-
- Book:
- Competitive Programming in Python
- Published online:
- 03 December 2020
- Print publication:
- 17 December 2020, pp 247-247
-
- Chapter
- Export citation
The effect of hemicylindrical disruptors on the cell free layer thickness in animal blood flows inside microchannels
-
- Journal:
- Experimental Results / Volume 1 / 2020
- Published online by Cambridge University Press:
- 17 December 2020, e55
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
