Refine search
Actions for selected content:
53179 results in Statistics and Probability
A multi-provincial outbreak of Salmonella Newport infections associated with red onions: A report of the largest Salmonella outbreak in Canada in over 20 years – Corrigendum
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 10 December 2024, e163
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Awareness and acceptance of human papillomavirus vaccine in the Middle East: A systematic review, meta-analysis, and meta-regression of 159 studies
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 10 December 2024, e165
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Insurance analytics: prediction, explainability, and fairness
-
- Journal:
- Annals of Actuarial Science / Volume 18 / Issue 3 / November 2024
- Published online by Cambridge University Press:
- 10 December 2024, pp. 535-539
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A systematic review and meta-analysis of ambient temperature and precipitation with infections from five food-borne bacterial pathogens – CORRIGENDUM
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 10 December 2024, e164
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
AI for peace: mitigating the risks and enhancing opportunities – ERRATUM
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 10 December 2024, e73
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
AI innovation in healthcare and state platforms under a rights-based perspective: the case of Brazillian RNDS
- Part of
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 09 December 2024, e70
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The Markov chain embedding problem in a one-jump setting
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 2 / June 2025
- Published online by Cambridge University Press:
- 09 December 2024, pp. 674-696
- Print publication:
- June 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The embedding problem of Markov chains examines whether a stochastic matrix
 $\mathbf{P} $ can arise as the transition matrix from time 0 to time 1 of a continuous-time Markov chain. When the chain is homogeneous, it checks if
$\mathbf{P} $ can arise as the transition matrix from time 0 to time 1 of a continuous-time Markov chain. When the chain is homogeneous, it checks if  $ \mathbf{P}=\exp{\mathbf{Q}}$ for a rate matrix
$ \mathbf{P}=\exp{\mathbf{Q}}$ for a rate matrix  $ \mathbf{Q}$ with zero row sums and non-negative off-diagonal elements, called a Markov generator. It is known that a Markov generator may not always exist or be unique. This paper addresses finding
$ \mathbf{Q}$ with zero row sums and non-negative off-diagonal elements, called a Markov generator. It is known that a Markov generator may not always exist or be unique. This paper addresses finding  $ \mathbf{Q}$, assuming that the process has at most one jump per unit time interval, and focuses on the problem of aligning the conditional one-jump transition matrix from time 0 to time 1 with
$ \mathbf{Q}$, assuming that the process has at most one jump per unit time interval, and focuses on the problem of aligning the conditional one-jump transition matrix from time 0 to time 1 with  $ \mathbf{P}$. We derive a formula for this matrix in terms of
$ \mathbf{P}$. We derive a formula for this matrix in terms of  $ \mathbf{Q}$ and establish that for any
$ \mathbf{Q}$ and establish that for any  $ \mathbf{P}$ with non-zero diagonal entries, a unique
$ \mathbf{P}$ with non-zero diagonal entries, a unique  $ \mathbf{Q}$, called the
$ \mathbf{Q}$, called the  ${\unicode{x1D7D9}}$-generator, exists. We compare the
${\unicode{x1D7D9}}$-generator, exists. We compare the  ${\unicode{x1D7D9}}$-generator with the one-jump rate matrix from Jarrow, Lando, and Turnbull (1997), showing which is a better approximate Markov generator of
${\unicode{x1D7D9}}$-generator with the one-jump rate matrix from Jarrow, Lando, and Turnbull (1997), showing which is a better approximate Markov generator of  $ \mathbf{P}$ in some practical cases.
$ \mathbf{P}$ in some practical cases.











Decoder decomposition for the analysis of the latent space of nonlinear autoencoders with wind-tunnel experimental data
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 09 December 2024, e38
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Exploring national infrastructures to support impact analyses of publicly accessible research: a need for trust, transparency, and collaboration at scale
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 09 December 2024, e69
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Average distance in a general class of scale-free networks
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 57 / Issue 2 / June 2025
- Published online by Cambridge University Press:
- 09 December 2024, pp. 371-406
- Print publication:
- June 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In Chung–Lu random graphs, a classic model for real-world networks, each vertex is equipped with a weight drawn from a power-law distribution, and two vertices form an edge independently with probability proportional to the product of their weights. Chung–Lu graphs have average distance
 $O(\log\log n)$ and thus reproduce the small-world phenomenon, a key property of real-world networks. Modern, more realistic variants of this model also equip each vertex with a random position in a specific underlying geometry. The edge probability of two vertices then depends, say, inversely polynomially on their distance.
$O(\log\log n)$ and thus reproduce the small-world phenomenon, a key property of real-world networks. Modern, more realistic variants of this model also equip each vertex with a random position in a specific underlying geometry. The edge probability of two vertices then depends, say, inversely polynomially on their distance.In this paper we study a generic augmented version of Chung–Lu random graphs. We analyze a model where the edge probability of two vertices can depend arbitrarily on their positions, as long as the marginal probability of forming an edge (for two vertices with fixed weights, one fixed position, and one random position) is as in a Chung–Lu random graph. The resulting class contains Chung–Lu random graphs, hyperbolic random graphs, and geometric inhomogeneous random graphs as special cases.
Our main result is that every random graph model in this general class has the same average distance as a Chung–Lu random graph, up to a factor of
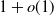 $1+o(1)$. This shows in particular that specific choices, such as taking the underlying geometry to be Euclidean, do not significantly influence the average distance. The proof also shows that every random graph model in our class has a giant component and polylogarithmic diameter with high probability.
$1+o(1)$. This shows in particular that specific choices, such as taking the underlying geometry to be Euclidean, do not significantly influence the average distance. The proof also shows that every random graph model in our class has a giant component and polylogarithmic diameter with high probability.

Sampling from the random cluster model on random regular graphs at all temperatures via Glauber dynamics
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 3 / May 2025
- Published online by Cambridge University Press:
- 09 December 2024, pp. 359-391
-
- Article
- Export citation
-
We consider the performance of Glauber dynamics for the random cluster model with real parameter
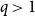 $q\gt 1$ and temperature
$q\gt 1$ and temperature 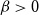 $\beta \gt 0$. Recent work by Helmuth, Jenssen, and Perkins detailed the ordered/disordered transition of the model on random
$\beta \gt 0$. Recent work by Helmuth, Jenssen, and Perkins detailed the ordered/disordered transition of the model on random 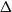 $\Delta$-regular graphs for all sufficiently large
$\Delta$-regular graphs for all sufficiently large 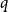 $q$ and obtained an efficient sampling algorithm for all temperatures
$q$ and obtained an efficient sampling algorithm for all temperatures 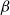 $\beta$ using cluster expansion methods. Despite this major progress, the performance of natural Markov chains, including Glauber dynamics, is not yet well understood on the random regular graph, partly because of the non-local nature of the model (especially at low temperatures) and partly because of severe bottleneck phenomena that emerge in a window around the ordered/disordered transition. Nevertheless, it is widely conjectured that the bottleneck phenomena that impede mixing from worst-case starting configurations can be avoided by initialising the chain more judiciously. Our main result establishes this conjecture for all sufficiently large
$\beta$ using cluster expansion methods. Despite this major progress, the performance of natural Markov chains, including Glauber dynamics, is not yet well understood on the random regular graph, partly because of the non-local nature of the model (especially at low temperatures) and partly because of severe bottleneck phenomena that emerge in a window around the ordered/disordered transition. Nevertheless, it is widely conjectured that the bottleneck phenomena that impede mixing from worst-case starting configurations can be avoided by initialising the chain more judiciously. Our main result establishes this conjecture for all sufficiently large 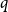 $q$ (with respect to
$q$ (with respect to 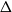 $\Delta$). Specifically, we consider the mixing time of Glauber dynamics initialised from the two extreme configurations, the all-in and all-out, and obtain a pair of fast mixing bounds which cover all temperatures
$\Delta$). Specifically, we consider the mixing time of Glauber dynamics initialised from the two extreme configurations, the all-in and all-out, and obtain a pair of fast mixing bounds which cover all temperatures 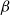 $\beta$, including in particular the bottleneck window. Our result is inspired by the recent approach of Gheissari and Sinclair for the Ising model who obtained a similar flavoured mixing-time bound on the random regular graph for sufficiently low temperatures. To cover all temperatures in the RC model, we refine appropriately the structural results of Helmuth, Jenssen and Perkins about the ordered/disordered transition and show spatial mixing properties ‘within the phase’, which are then related to the evolution of the chain.
$\beta$, including in particular the bottleneck window. Our result is inspired by the recent approach of Gheissari and Sinclair for the Ising model who obtained a similar flavoured mixing-time bound on the random regular graph for sufficiently low temperatures. To cover all temperatures in the RC model, we refine appropriately the structural results of Helmuth, Jenssen and Perkins about the ordered/disordered transition and show spatial mixing properties ‘within the phase’, which are then related to the evolution of the chain.
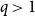
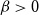
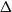
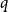
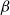
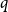
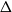
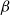
Barlow and Proschan principle for coherent systems with statistically dependent component and redundancy lifetimes
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 39 / Issue 2 / April 2025
- Published online by Cambridge University Press:
- 09 December 2024, pp. 141-155
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Trust norms for generative AI data gathering in the African context
- Part of
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 09 December 2024, e71
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Estimated reduction in human salmonellosis incidence in Canada from a new government requirement to reduce Salmonella in frozen breaded chicken products
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 09 December 2024, e162
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Responsible artificial intelligence in Africa: towards policy learning
- Part of
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 09 December 2024, e72
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Predictive model for genital tract infections among men and women in Ghana: An application of LASSO penalized cross-validation regression model
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 06 December 2024, e160
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Measles and rubella seroprevalence in adults using residual blood samples from health facilities and household serosurveys in Palghar District, Maharashtra, India, 2018 – 2019
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 06 December 2024, e161
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A web-based dynamic nomogram for estimating talaromycosis risk in hospitalized HIV-positive patients
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 05 December 2024, e153
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Global epidemiology of serogroup Y invasive meningococcal disease: a literature review
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 05 December 2024, e157
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The predictive values of C-reactive protein-neutrophil to lymphocyte ratio for the risk of refractory Mycoplasma pneumoniae pneumonia in children: a retrospective cohort study
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 05 December 2024, e158
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
