Refine listing
Actions for selected content:
142032 results in Open Access
Comparing traditional and automated conservation assessments for Himalayan species of Buddleja
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
National Mourning and the Poetics of Public Grief: Jaroslav Seifert's Elegies for T. G. Masaryk
-
- Journal:
- Slavic Review / Volume 83 / Issue 3 / Fall 2024
- Published online by Cambridge University Press:
- 13 February 2025, pp. 559-575
- Print publication:
- Fall 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The
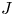 $J$-invariant over splitting fields of Tits algebras
$J$-invariant over splitting fields of Tits algebras
- Part of
-
- Journal:
- Compositio Mathematica / Volume 160 / Issue 9 / September 2024
- Published online by Cambridge University Press:
- 11 September 2024, pp. 2100-2114
- Print publication:
- September 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We describe the
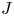 $J$-invariant of a semisimple algebraic group
$J$-invariant of a semisimple algebraic group 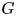 $G$ over a generic splitting field of a Tits algebra of
$G$ over a generic splitting field of a Tits algebra of 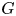 $G$ in terms of the
$G$ in terms of the 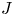 $J$-invariant over the base field. As a consequence we prove a 10-year-old conjecture of Quéguiner-Mathieu, Semenov, and Zainoulline on the
$J$-invariant over the base field. As a consequence we prove a 10-year-old conjecture of Quéguiner-Mathieu, Semenov, and Zainoulline on the 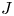 $J$-invariant of groups of type
$J$-invariant of groups of type 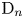 $\mathrm {D}_n$. In the case of type
$\mathrm {D}_n$. In the case of type 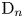 $\mathrm {D}_n$ we also provide explicit formulas for the first component and in some cases for the second component of the
$\mathrm {D}_n$ we also provide explicit formulas for the first component and in some cases for the second component of the 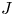 $J$-invariant.
$J$-invariant.
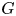
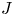
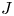
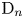
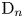
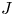

Foreign in Two Homelands
- Racism, Return Migration, and Turkish-German History
-
- Published online:
- 31 August 2024
- Print publication:
- 31 October 2024
-
- Book
-
- You have access
- Open access
- Export citation

Beyond Social Democracy
- The Transformation of the Left in Emerging Knowledge Societies
-
- Published online:
- 31 August 2024
- Print publication:
- 27 June 2024
-
- Book
-
- You have access
- Open access
- Export citation
A governance and legal framework for getting to “yes” with enterprise-level data integration
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 30 August 2024, e31
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Simulation and scaling analysis of periodic surfaces with small-scale roughness in turbulent Ekman flow
-
- Journal:
- Journal of Fluid Mechanics / Volume 992 / 10 August 2024
- Published online by Cambridge University Press:
- 30 August 2024, A8
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Roughness of the surface underlying the atmospheric boundary layer causes departures of the near-surface scalar and momentum transport in comparison with aerodynamically smooth surfaces. Here, we investigate the effect of
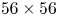 $56\times 56$ homogeneously distributed roughness elements on bulk properties of a turbulent Ekman flow. Direct numerical simulation in combination with an immersed boundary method is performed for fully resolved, three-dimensional roughness elements. The packing density is approximately
$56\times 56$ homogeneously distributed roughness elements on bulk properties of a turbulent Ekman flow. Direct numerical simulation in combination with an immersed boundary method is performed for fully resolved, three-dimensional roughness elements. The packing density is approximately 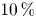 $10\,\%$ and the roughness elements have a mean height in wall units of
$10\,\%$ and the roughness elements have a mean height in wall units of 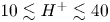 $10 \lesssim H^+ \lesssim 40$. According to their roughness Reynolds numbers, the cases are transitionally rough, although the roughest case is on the verge of being fully rough. We derive the friction of velocity and of the passive scalar through vertical integration of the respective balances. Thereby, we quantify the enhancement of turbulent activity with increasing roughness height and find a scaling for the friction Reynolds number that is verified up to
$10 \lesssim H^+ \lesssim 40$. According to their roughness Reynolds numbers, the cases are transitionally rough, although the roughest case is on the verge of being fully rough. We derive the friction of velocity and of the passive scalar through vertical integration of the respective balances. Thereby, we quantify the enhancement of turbulent activity with increasing roughness height and find a scaling for the friction Reynolds number that is verified up to 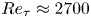 $Re_\tau \approx 2700$. The higher level of turbulent activity results in a deeper logarithmic layer for the rough cases and an increase of the near-surface wind veer in spite of higher
$Re_\tau \approx 2700$. The higher level of turbulent activity results in a deeper logarithmic layer for the rough cases and an increase of the near-surface wind veer in spite of higher 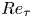 $Re_\tau$. We estimate the von Kármán constant for the horizontal velocity
$Re_\tau$. We estimate the von Kármán constant for the horizontal velocity 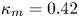 $\kappa _{m}=0.42$ (offset
$\kappa _{m}=0.42$ (offset 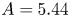 $A=5.44$) and for the passive scalar
$A=5.44$) and for the passive scalar 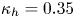 $\kappa _{h}=0.35$ (offset
$\kappa _{h}=0.35$ (offset  $\mathbb {A}=4.2$). We find an accurate collapse of the data under the rough-wall scaling in the logarithmic layer, which also yields a scaling for the roughness parameters
$\mathbb {A}=4.2$). We find an accurate collapse of the data under the rough-wall scaling in the logarithmic layer, which also yields a scaling for the roughness parameters 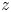 $z$-nought for momentum (
$z$-nought for momentum (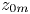 $z_{0{m}}$) and the passive scalar (
$z_{0{m}}$) and the passive scalar (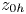 $z_{0{h}}$).
$z_{0{h}}$).
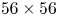
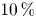
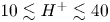
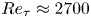
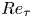
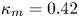
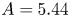
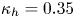

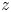
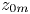
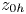
Exploring African skills 4.0 required for 4IR industry: a systematic literature review
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 30 August 2024, e36
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Private sector trust in data sharing: enablers in the European Union
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 30 August 2024, e30
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Designing data collaboratives’ governance dimensions for long-term stability: an empirical analysis
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 30 August 2024, e37
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
What does a record have to do with it? Re-situating records management within Indian public data governance and policy
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 30 August 2024, e38
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
People of Clay and Stone: Indexing Other-than-Human Animacy and Collective Identity in Coastal Oaxaca, Mexico
-
- Journal:
- Latin American Antiquity / Volume 35 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 30 August 2024, pp. 752-770
- Print publication:
- September 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Affective Polarization in Europe – ERRATUM
-
- Journal:
- European Political Science Review / Volume 17 / Issue 1 / February 2025
- Published online by Cambridge University Press:
- 30 August 2024, p. 167
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Toward a trustworthy and inclusive data governance policy for the use of artificial intelligence in Africa
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 30 August 2024, e34
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The promise of machine learning in violent conflict forecasting
- Part of
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 30 August 2024, e35
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Enhancing student performance in African smart cities: a web-based approach through advanced ensemble modeling and genetic feature optimization
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 30 August 2024, e33
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Decision time: illuminating performance in India’s district courts
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 30 August 2024, e32
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
14 - Inevitable or Not?
- from Part III - Human–Robot Interactions and Legal Narrative
-
-
- Book:
- Human–Robot Interaction in Law and Its Narratives
- Published online:
- 03 October 2024
- Print publication:
- 29 August 2024, pp 311-334
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
11 - Reconsidering Two US Constitutional Doctrines
- from Part II - Human–Robot Interactions and Procedural Law
-
-
- Book:
- Human–Robot Interaction in Law and Its Narratives
- Published online:
- 03 October 2024
- Print publication:
- 29 August 2024, pp 253-278
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
5 - Introduction to Human–Robot Interaction and Procedural Issues in Criminal Justice
- from Part II - Human–Robot Interactions and Procedural Law
-
-
- Book:
- Human–Robot Interaction in Law and Its Narratives
- Published online:
- 03 October 2024
- Print publication:
- 29 August 2024, pp 89-110
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
