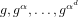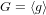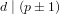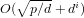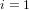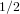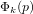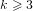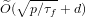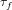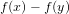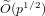Refine search
Actions for selected content:
30 results
The complexity of intersecting subproducts with subgroups in Cartesian powers
- Part of
-
- Journal:
- Glasgow Mathematical Journal , First View
- Published online by Cambridge University Press:
- 07 October 2025, pp. 1-7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Given a finite abelian group
 $G$ and
$G$ and  $t\in \mathbb{N}$, there are two natural types of subsets of the Cartesian power
$t\in \mathbb{N}$, there are two natural types of subsets of the Cartesian power  $G^t$; namely, Cartesian powers
$G^t$; namely, Cartesian powers  $S^t$ where
$S^t$ where  $S$ is a subset of
$S$ is a subset of  $G$ and (cosets of) subgroups
$G$ and (cosets of) subgroups  $H$ of
$H$ of  $G^t$. A basic question is whether two such sets intersect. In this paper, we show that this decision problem is NP-complete. Furthermore, for fixed
$G^t$. A basic question is whether two such sets intersect. In this paper, we show that this decision problem is NP-complete. Furthermore, for fixed  $G$ and
$G$ and  $S$, we give a complete classification: we determine conditions for when the problem is NP-complete and show that in all other cases the problem is solvable in polynomial time. These theorems play a key role in the classification of algebraic decision problems in finitely generated rings developed in later work of the author.
$S$, we give a complete classification: we determine conditions for when the problem is NP-complete and show that in all other cases the problem is solvable in polynomial time. These theorems play a key role in the classification of algebraic decision problems in finitely generated rings developed in later work of the author.










Vanishing of Schubert coefficients via the effective Hilbert nullstellensatz
- Part of
-
- Journal:
- Forum of Mathematics, Sigma / Volume 13 / 2025
- Published online by Cambridge University Press:
- 01 October 2025, e162
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Schubert Vanishing is a problem of deciding whether Schubert coefficients are zero. Until this work it was open whether this problem is in the polynomial hierarchy
 ${{\mathsf {PH}}}$. We prove this problem is in
${{\mathsf {PH}}}$. We prove this problem is in  ${{\mathsf {AM}}} \cap {{\mathsf {coAM}}}$ assuming the Generalized Riemann Hypothesis (
${{\mathsf {AM}}} \cap {{\mathsf {coAM}}}$ assuming the Generalized Riemann Hypothesis ( $\mathrm{GRH}$), that is, relatively low in
$\mathrm{GRH}$), that is, relatively low in  ${{\mathsf {PH}}}$. Our approach uses Purbhoo’s criterion [57] to construct explicit polynomial systems for the problem. The result follows from a reduction to Parametric Hilbert’s Nullstellensatz, recently analyzed in [2]. We extend our results to all classical types.
${{\mathsf {PH}}}$. Our approach uses Purbhoo’s criterion [57] to construct explicit polynomial systems for the problem. The result follows from a reduction to Parametric Hilbert’s Nullstellensatz, recently analyzed in [2]. We extend our results to all classical types.




Exact recovery of community detection in k-community Gaussian mixture models
- Part of
-
- Journal:
- European Journal of Applied Mathematics / Volume 36 / Issue 3 / June 2025
- Published online by Cambridge University Press:
- 18 September 2024, pp. 491-523
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study the community detection problem on a Gaussian mixture model, in which vertices are divided into
 $k\geq 2$ distinct communities. The major difference in our model is that the intensities for Gaussian perturbations are different for different entries in the observation matrix, and we do not assume that every community has the same number of vertices. We explicitly find the necessary and sufficient conditions for the exact recovery of the maximum likelihood estimation, which can give a sharp phase transition for the exact recovery even though the Gaussian perturbations are not identically distributed; see Section 7. Applications include the community detection on hypergraphs.
$k\geq 2$ distinct communities. The major difference in our model is that the intensities for Gaussian perturbations are different for different entries in the observation matrix, and we do not assume that every community has the same number of vertices. We explicitly find the necessary and sufficient conditions for the exact recovery of the maximum likelihood estimation, which can give a sharp phase transition for the exact recovery even though the Gaussian perturbations are not identically distributed; see Section 7. Applications include the community detection on hypergraphs.

Rigid continuation paths II. structured polynomial systems
- Part of
-
- Journal:
- Forum of Mathematics, Pi / Volume 11 / 2023
- Published online by Cambridge University Press:
- 14 April 2023, e12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This work studies the average complexity of solving structured polynomial systems that are characterised by a low evaluation cost, as opposed to the dense random model previously used. Firstly, we design a continuation algorithm that computes, with high probability, an approximate zero of a polynomial system given only as black-box evaluation program. Secondly, we introduce a universal model of random polynomial systems with prescribed evaluation complexity L. Combining both, we show that we can compute an approximate zero of a random structured polynomial system with n equations of degree at most
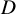 ${D}$ in n variables with only
${D}$ in n variables with only 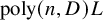 $\operatorname {poly}(n, {D}) L$ operations with high probability. This exceeds the expectations implicit in Smale’s 17th problem.
$\operatorname {poly}(n, {D}) L$ operations with high probability. This exceeds the expectations implicit in Smale’s 17th problem.
Functional norms, condition numbers and numerical algorithms in algebraic geometry
- Part of
-
- Journal:
- Forum of Mathematics, Sigma / Volume 10 / 2022
- Published online by Cambridge University Press:
- 22 November 2022, e103
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In numerical linear algebra, a well-established practice is to choose a norm that exploits the structure of the problem at hand to optimise accuracy or computational complexity. In numerical polynomial algebra, a single norm (attributed to Weyl) dominates the literature. This article initiates the use of
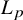 $L_p$ norms for numerical algebraic geometry, with an emphasis on
$L_p$ norms for numerical algebraic geometry, with an emphasis on 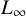 $L_{\infty }$. This classical idea yields strong improvements in the analysis of the number of steps performed by numerous iterative algorithms. In particular, we exhibit three algorithms where, despite the complexity of computing
$L_{\infty }$. This classical idea yields strong improvements in the analysis of the number of steps performed by numerous iterative algorithms. In particular, we exhibit three algorithms where, despite the complexity of computing 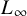 $L_{\infty }$-norm, the use of
$L_{\infty }$-norm, the use of 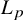 $L_p$-norms substantially reduces computational complexity: a subdivision-based algorithm in real algebraic geometry for computing the homology of semialgebraic sets, a well-known meshing algorithm in computational geometry and the computation of zeros of systems of complex quadratic polynomials (a particular case of Smale’s 17th problem).
$L_p$-norms substantially reduces computational complexity: a subdivision-based algorithm in real algebraic geometry for computing the homology of semialgebraic sets, a well-known meshing algorithm in computational geometry and the computation of zeros of systems of complex quadratic polynomials (a particular case of Smale’s 17th problem).
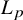
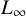
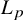
IS CAUSAL REASONING HARDER THAN PROBABILISTIC REASONING?
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 17 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 18 May 2022, pp. 106-131
- Print publication:
- March 2024
-
- Article
- Export citation
-
Many tasks in statistical and causal inference can be construed as problems of entailment in a suitable formal language. We ask whether those problems are more difficult, from a computational perspective, for causal probabilistic languages than for pure probabilistic (or “associational”) languages. Despite several senses in which causal reasoning is indeed more complex—both expressively and inferentially—we show that causal entailment (or satisfiability) problems can be systematically and robustly reduced to purely probabilistic problems. Thus there is no jump in computational complexity. Along the way we answer several open problems concerning the complexity of well-known probability logics, in particular demonstrating the
 ${\exists \mathbb {R}}$-completeness of a polynomial probability calculus, as well as a seemingly much simpler system, the logic of comparative conditional probability.
${\exists \mathbb {R}}$-completeness of a polynomial probability calculus, as well as a seemingly much simpler system, the logic of comparative conditional probability.

Yaglom limit for stochastic fluid models
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 53 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 08 October 2021, pp. 649-686
- Print publication:
- September 2021
-
- Article
- Export citation
-
In this paper we analyse the limiting conditional distribution (Yaglom limit) for stochastic fluid models (SFMs), a key class of models in the theory of matrix-analytic methods. So far, only transient and stationary analyses of SFMs have been considered in the literature. The limiting conditional distribution gives useful insights into what happens when the process has been evolving for a long time, given that its busy period has not ended yet. We derive expressions for the Yaglom limit in terms of the singularity˜
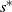 $s^*$ such that the key matrix of the SFM,
$s^*$ such that the key matrix of the SFM, 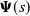 ${\boldsymbol{\Psi}}(s)$, is finite (exists) for all
${\boldsymbol{\Psi}}(s)$, is finite (exists) for all 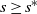 $s\geq s^*$ and infinite for
$s\geq s^*$ and infinite for 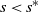 $s<s^*$. We show the uniqueness of the Yaglom limit and illustrate the application of the theory with simple examples.
$s<s^*$. We show the uniqueness of the Yaglom limit and illustrate the application of the theory with simple examples.
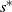
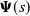
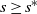
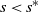
Polynomial-time approximation algorithms for the antiferromagnetic Ising model on line graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 6 / November 2021
- Published online by Cambridge University Press:
- 12 April 2021, pp. 905-921
-
- Article
- Export citation
DECIDING SOME MALTSEV CONDITIONS IN FINITE IDEMPOTENT ALGEBRAS
- Part of
-
- Journal:
- The Journal of Symbolic Logic / Volume 85 / Issue 2 / June 2020
- Published online by Cambridge University Press:
- 16 June 2020, pp. 539-562
- Print publication:
- June 2020
-
- Article
- Export citation
Estimating parameters associated with monotone properties
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 4 / July 2020
- Published online by Cambridge University Press:
- 24 March 2020, pp. 616-632
-
- Article
- Export citation
-
There has been substantial interest in estimating the value of a graph parameter, i.e. of a real-valued function defined on the set of finite graphs, by querying a randomly sampled substructure whose size is independent of the size of the input. Graph parameters that may be successfully estimated in this way are said to be testable or estimable, and the sample complexity qz = qz(ε) of an estimable parameter z is the size of a random sample of a graph G required to ensure that the value of z(G) may be estimated within an error of ε with probability at least 2/3. In this paper, for any fixed monotone graph property
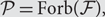 $\mathcal{P}= \text{Forb}\!(\mathcal{F}),$ we study the sample complexity of estimating a bounded graph parameter z that, for an input graph G, counts the number of spanning subgraphs of G that satisfy
$\mathcal{P}= \text{Forb}\!(\mathcal{F}),$ we study the sample complexity of estimating a bounded graph parameter z that, for an input graph G, counts the number of spanning subgraphs of G that satisfy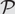 $\mathcal{P}$. To improve upon previous upper bounds on the sample complexity, we show that the vertex set of any graph that satisfies a monotone property $\mathcal{P}$ may be partitioned equitably into a constant number of classes in such a way that the cluster graph induced by the partition is not far from satisfying a natural weighted graph generalization of $\mathcal{P}$. Properties for which this holds are said to be recoverable, and the study of recoverable properties may be of independent interest.
$\mathcal{P}$. To improve upon previous upper bounds on the sample complexity, we show that the vertex set of any graph that satisfies a monotone property $\mathcal{P}$ may be partitioned equitably into a constant number of classes in such a way that the cluster graph induced by the partition is not far from satisfying a natural weighted graph generalization of $\mathcal{P}$. Properties for which this holds are said to be recoverable, and the study of recoverable properties may be of independent interest.
Deciding the Existence of Minority Terms
- Part of
-
- Journal:
- Canadian Mathematical Bulletin / Volume 63 / Issue 3 / September 2020
- Published online by Cambridge University Press:
- 24 October 2019, pp. 577-591
- Print publication:
- September 2020
-
- Article
-
- You have access
- Export citation
-
This paper investigates the computational complexity of deciding if a given finite idempotent algebra has a ternary term operation
 $m$ that satisfies the minority equations
$m$ that satisfies the minority equations 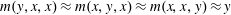 $m(y,x,x)\approx m(x,y,x)\approx m(x,x,y)\approx y$. We show that a common polynomial-time approach to testing for this type of condition will not work in this case and that this decision problem lies in the class
$m(y,x,x)\approx m(x,y,x)\approx m(x,x,y)\approx y$. We show that a common polynomial-time approach to testing for this type of condition will not work in this case and that this decision problem lies in the class NP .

DEGREE BOUNDED GEOMETRIC SPANNING TREES WITH A BOTTLENECK OBJECTIVE FUNCTION
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 101 / Issue 1 / February 2020
- Published online by Cambridge University Press:
- 23 October 2019, pp. 170-171
- Print publication:
- February 2020
-
- Article
-
- You have access
- Export citation
Weighted counting of solutions to sparse systems of equations
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 5 / September 2019
- Published online by Cambridge University Press:
- 15 April 2019, pp. 696-719
-
- Article
- Export citation
-
Given complex numbers w1,…,wn, we define the weight w(X) of a set X of 0–1 vectors as the sum of
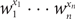 $w_1^{x_1} \cdots w_n^{x_n}$ over all vectors (x1,…,xn) in X. We present an algorithm which, for a set X defined by a system of homogeneous linear equations with at most r variables per equation and at most c equations per variable, computes w(X) within relative error ∊ > 0 in (rc)O(lnn-ln∊) time provided
$w_1^{x_1} \cdots w_n^{x_n}$ over all vectors (x1,…,xn) in X. We present an algorithm which, for a set X defined by a system of homogeneous linear equations with at most r variables per equation and at most c equations per variable, computes w(X) within relative error ∊ > 0 in (rc)O(lnn-ln∊) time provided 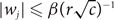 $|w_j| \leq \beta (r \sqrt{c})^{-1}$ for an absolute constant β > 0 and all j = 1,…,n. A similar algorithm is constructed for computing the weight of a linear code over
$|w_j| \leq \beta (r \sqrt{c})^{-1}$ for an absolute constant β > 0 and all j = 1,…,n. A similar algorithm is constructed for computing the weight of a linear code over 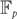 ${\mathbb F}_p$. Applications include counting weighted perfect matchings in hypergraphs, counting weighted graph homomorphisms, computing weight enumerators of linear codes with sparse code generating matrices, and computing the partition functions of the ferromagnetic Potts model at low temperatures and of the hard-core model at high fugacity on biregular bipartite graphs.
${\mathbb F}_p$. Applications include counting weighted perfect matchings in hypergraphs, counting weighted graph homomorphisms, computing weight enumerators of linear codes with sparse code generating matrices, and computing the partition functions of the ferromagnetic Potts model at low temperatures and of the hard-core model at high fugacity on biregular bipartite graphs.
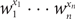
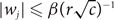
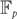
ON FINDING SOLUTIONS TO EXPONENTIAL CONGRUENCES
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 99 / Issue 3 / June 2019
- Published online by Cambridge University Press:
- 27 December 2018, pp. 388-391
- Print publication:
- June 2019
-
- Article
-
- You have access
- Export citation
-
We improve some previously known deterministic algorithms for finding integer solutions
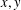 $x,y$ to the exponential equation of the form
$x,y$ to the exponential equation of the form 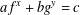 $af^{x}+bg^{y}=c$ over finite fields.
$af^{x}+bg^{y}=c$ over finite fields.
Dual-Pivot Quicksort: Optimality, Analysis and Zeros of Associated Lattice Paths
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 4 / July 2019
- Published online by Cambridge University Press:
- 14 August 2018, pp. 485-518
-
- Article
- Export citation
A GENERAL POSITION PROBLEM IN GRAPH THEORY
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 98 / Issue 2 / October 2018
- Published online by Cambridge University Press:
- 18 July 2018, pp. 177-187
- Print publication:
- October 2018
-
- Article
-
- You have access
- Export citation
-
The paper introduces a graph theory variation of the general position problem: given a graph
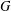 $G$, determine a largest set
$G$, determine a largest set 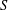 $S$ of vertices of
$S$ of vertices of 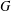 $G$ such that no three vertices of
$G$ such that no three vertices of 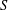 $S$ lie on a common geodesic. Such a set is a max-gp-set of
$S$ lie on a common geodesic. Such a set is a max-gp-set of 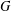 $G$ and its size is the gp-number
$G$ and its size is the gp-number 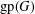 $\text{gp}(G)$ of
$\text{gp}(G)$ of 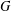 $G$. Upper bounds on
$G$. Upper bounds on 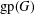 $\text{gp}(G)$ in terms of different isometric covers are given and used to determine the gp-number of several classes of graphs. Connections between general position sets and packings are investigated and used to give lower bounds on the gp-number. It is also proved that the general position problem is NP-complete.
$\text{gp}(G)$ in terms of different isometric covers are given and used to determine the gp-number of several classes of graphs. Connections between general position sets and packings are investigated and used to give lower bounds on the gp-number. It is also proved that the general position problem is NP-complete.
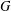
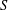
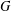
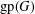
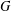
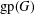
ON SEMIGROUPS WITH PSPACE-COMPLETE SUBPOWER MEMBERSHIP PROBLEM
- Part of
-
- Journal:
- Journal of the Australian Mathematical Society / Volume 106 / Issue 1 / February 2019
- Published online by Cambridge University Press:
- 30 May 2018, pp. 127-142
- Print publication:
- February 2019
-
- Article
-
- You have access
- Export citation
-
Fix a finite semigroup
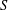 $S$ and let
$S$ and let 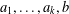 $a_{1},\ldots ,a_{k},b$ be tuples in a direct power
$a_{1},\ldots ,a_{k},b$ be tuples in a direct power 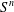 $S^{n}$. The subpower membership problem (SMP) for
$S^{n}$. The subpower membership problem (SMP) for 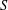 $S$ asks whether
$S$ asks whether 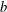 $b$ can be generated by
$b$ can be generated by 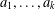 $a_{1},\ldots ,a_{k}$. For combinatorial Rees matrix semigroups we establish a dichotomy result: if the corresponding matrix is of a certain form, then the SMP is in P; otherwise it is NP-complete. For combinatorial Rees matrix semigroups with adjoined identity, we obtain a trichotomy: the SMP is either in P, NP-complete, or PSPACE-complete. This result yields various semigroups with PSPACE-complete SMP including the six-element Brandt monoid, the full transformation semigroup on three or more letters, and semigroups of all
$a_{1},\ldots ,a_{k}$. For combinatorial Rees matrix semigroups we establish a dichotomy result: if the corresponding matrix is of a certain form, then the SMP is in P; otherwise it is NP-complete. For combinatorial Rees matrix semigroups with adjoined identity, we obtain a trichotomy: the SMP is either in P, NP-complete, or PSPACE-complete. This result yields various semigroups with PSPACE-complete SMP including the six-element Brandt monoid, the full transformation semigroup on three or more letters, and semigroups of all  $n$ by
$n$ by  $n$ matrices over a field for
$n$ matrices over a field for 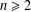 $n\geq 2$.
$n\geq 2$.
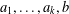
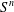
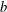
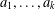


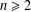
Reduced memory meet-in-the-middle attackagainst the NTRU private key
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 19 / Issue A / 2016
- Published online by Cambridge University Press:
- 26 August 2016, pp. 43-57
-
- Article
-
- You have access
- Export citation
-
NTRU is a public-key cryptosystem introduced at ANTS-III. The two most used techniques in attacking the NTRU private key are meet-in-the-middle attacks and lattice-basis reduction attacks. Howgrave-Graham combined both techniques in 2007 and pointed out that the largest obstacle to attacks is the memory capacity that is required for the meet-in-the-middle phase. In the present paper an algorithm is presented that applies low-memory techniques to find ‘golden’ collisions to Odlyzko’s meet-in-the-middle attack against the NTRU private key. Several aspects of NTRU secret keys and the algorithm are analysed. The running time of the algorithm with a maximum storage capacity of
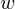 $w$ is estimated and experimentally verified. Experiments indicate that decreasing the storage capacity
$w$ is estimated and experimentally verified. Experiments indicate that decreasing the storage capacity 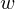 $w$ by a factor
$w$ by a factor 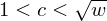 $1<c<\sqrt{w}$ increases the running time by a factor
$1<c<\sqrt{w}$ increases the running time by a factor 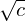 $\sqrt{c}$ .
$\sqrt{c}$ .
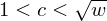
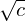
An algorithm for NTRU problems and cryptanalysis of the GGH multilinear map without a low-level encoding of zero
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 19 / Issue A / 2016
- Published online by Cambridge University Press:
- 26 August 2016, pp. 255-266
-
- Article
-
- You have access
- Export citation
-
Let
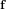 $\mathbf{f}$ and
$\mathbf{f}$ and  $\mathbf{g}$ be polynomials of a bounded Euclidean norm in the ring
$\mathbf{g}$ be polynomials of a bounded Euclidean norm in the ring 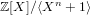 $\mathbb{Z}[X]/\langle X^{n}+1\rangle$ . Given the polynomial
$\mathbb{Z}[X]/\langle X^{n}+1\rangle$ . Given the polynomial 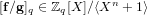 $[\mathbf{f}/\mathbf{g}]_{q}\in \mathbb{Z}_{q}[X]/\langle X^{n}+1\rangle$ , the NTRU problem is to find
$[\mathbf{f}/\mathbf{g}]_{q}\in \mathbb{Z}_{q}[X]/\langle X^{n}+1\rangle$ , the NTRU problem is to find 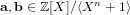 $\mathbf{a},\mathbf{b}\in \mathbb{Z}[X]/\langle X^{n}+1\rangle$ with a small Euclidean norm such that
$\mathbf{a},\mathbf{b}\in \mathbb{Z}[X]/\langle X^{n}+1\rangle$ with a small Euclidean norm such that 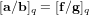 $[\mathbf{a}/\mathbf{b}]_{q}=[\mathbf{f}/\mathbf{g}]_{q}$ . We propose an algorithm to solve the NTRU problem, which runs in
$[\mathbf{a}/\mathbf{b}]_{q}=[\mathbf{f}/\mathbf{g}]_{q}$ . We propose an algorithm to solve the NTRU problem, which runs in 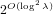 $2^{O(\log ^{2}\unicode[STIX]{x1D706})}$ time when
$2^{O(\log ^{2}\unicode[STIX]{x1D706})}$ time when 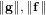 $\Vert \mathbf{g}\Vert ,\Vert \mathbf{f}\Vert$ , and
$\Vert \mathbf{g}\Vert ,\Vert \mathbf{f}\Vert$ , and 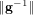 $\Vert \mathbf{g}^{-1}\Vert$ are within some range. The main technique of our algorithm is the reduction of a problem on a field to one on a subfield. The GGH scheme, the first candidate of an (approximate) multilinear map, was recently found to be insecure by the Hu–Jia attack using low-level encodings of zero, but no polynomial-time attack was known without them. In the GGH scheme without low-level encodings of zero, our algorithm can be directly applied to attack this scheme if we have some top-level encodings of zero and a known pair of plaintext and ciphertext. Using our algorithm, we can construct a level-
$\Vert \mathbf{g}^{-1}\Vert$ are within some range. The main technique of our algorithm is the reduction of a problem on a field to one on a subfield. The GGH scheme, the first candidate of an (approximate) multilinear map, was recently found to be insecure by the Hu–Jia attack using low-level encodings of zero, but no polynomial-time attack was known without them. In the GGH scheme without low-level encodings of zero, our algorithm can be directly applied to attack this scheme if we have some top-level encodings of zero and a known pair of plaintext and ciphertext. Using our algorithm, we can construct a level-  $0$ encoding of zero and utilize it to attack a security ground of this scheme in the quasi-polynomial time of its security parameter using the parameters suggested by Garg, Gentry and Halevi [‘Candidate multilinear maps from ideal lattices’, Advances in cryptology — EUROCRYPT 2013 (Springer, 2013) 1–17].
$0$ encoding of zero and utilize it to attack a security ground of this scheme in the quasi-polynomial time of its security parameter using the parameters suggested by Garg, Gentry and Halevi [‘Candidate multilinear maps from ideal lattices’, Advances in cryptology — EUROCRYPT 2013 (Springer, 2013) 1–17].
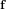

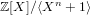
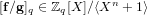
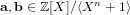
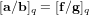
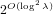
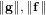
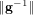

A new approach to the discrete logarithm problem with auxiliary inputs
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 19 / Issue 1 / 2016
- Published online by Cambridge University Press:
- 01 January 2016, pp. 1-15
-
- Article
-
- You have access
- Export citation
-
The aim of the discrete logarithm problem with auxiliary inputs is to solve for
 ${\it\alpha}$ , given the elements
${\it\alpha}$ , given the elements 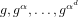 $g,g^{{\it\alpha}},\ldots ,g^{{\it\alpha}^{d}}$ of a cyclic group
$g,g^{{\it\alpha}},\ldots ,g^{{\it\alpha}^{d}}$ of a cyclic group 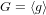 $G=\langle g\rangle$ , of prime order
$G=\langle g\rangle$ , of prime order  $p$ . The best-known algorithm, proposed by Cheon in 2006, solves for
$p$ . The best-known algorithm, proposed by Cheon in 2006, solves for  ${\it\alpha}$ in the case where
${\it\alpha}$ in the case where 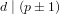 $d\mid (p\pm 1)$ , with a running time of
$d\mid (p\pm 1)$ , with a running time of 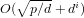 $O(\sqrt{p/d}+d^{i})$ group exponentiations (
$O(\sqrt{p/d}+d^{i})$ group exponentiations ( 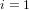 $i=1$ or
$i=1$ or 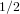 $1/2$ depending on the sign). There have been several attempts to generalize this algorithm to the case of
$1/2$ depending on the sign). There have been several attempts to generalize this algorithm to the case of 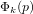 ${\rm\Phi}_{k}(p)$ where
${\rm\Phi}_{k}(p)$ where 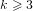 $k\geqslant 3$ . However, it has been shown by Kim, Cheon and Lee that a better complexity cannot be achieved than that of the usual square root algorithms.
$k\geqslant 3$ . However, it has been shown by Kim, Cheon and Lee that a better complexity cannot be achieved than that of the usual square root algorithms.We propose a new algorithm for solving the DLPwAI. We show that this algorithm has a running time of
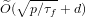 $\widetilde{O}(\sqrt{p/{\it\tau}_{f}}+d)$ group exponentiations, where
$\widetilde{O}(\sqrt{p/{\it\tau}_{f}}+d)$ group exponentiations, where 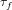 ${\it\tau}_{f}$ is the number of absolutely irreducible factors of
${\it\tau}_{f}$ is the number of absolutely irreducible factors of 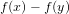 $f(x)-f(y)$ . We note that this number is always smaller than
$f(x)-f(y)$ . We note that this number is always smaller than 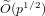 $\widetilde{O}(p^{1/2})$ .
$\widetilde{O}(p^{1/2})$ .In addition, we present an analysis of a non-uniform birthday problem.