Refine search
Actions for selected content:
1139 results

An Introduction to Computational Physics
- Coming soon
-
- Expected online publication date:
- January 2027
- Print publication:
- 31 December 2026
-
- Textbook
- Export citation
A variational formulation of the anisotropic Darcy–Brinkman–Forchheimer model: theory and neural computation
-
- Journal:
- Journal of Fluid Mechanics / Volume 1039 / 25 July 2026
- Published online by Cambridge University Press:
- 14 July 2026, A10
-
- Article
- Export citation
Explainable machine learning highlights the role of diffuse radiation in ecosystem carbon uptake of boreal forest
-
- Journal:
- Environmental Data Science / Volume 5 / 2026
- Published online by Cambridge University Press:
- 06 July 2026, e15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Boreal forests play a critical role in the global carbon cycle as they are one of the largest terrestrial carbon sinks globally. In this study, we employ explainable machine learning (ML) techniques to investigate the influence of environmental and vegetation variables on net ecosystem exchange (NEE), focusing specifically on the effects of diffuse radiation. We utilize a sub-hourly resolution data set including satellite and in-situ observations from three boreal or hemiboreal forest research stations across the latitudes 58–68° N to capture latitudinal variability in forest carbon uptake. Using SHAP (Shapley Additive Explanations) values, we identify key drivers influencing NEE and quantify their importance across various ML model architectures. Photosynthetically active radiation (PAR), diffuse radiation, normalized difference vegetation index, and soil temperature were identified as the variables having the largest explanatory power for NEE across the ML models. ML models using only these variables result in $ {R}^2\approx 0.8 $
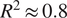 and RMSE$ \approx 2.3 $
and RMSE$ \approx 2.3 $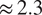 $ \mu \mathrm{mol}\;{\mathrm{m}}^{-2}\hskip0.1em {\mathrm{s}}^{-1} $
$ \mu \mathrm{mol}\;{\mathrm{m}}^{-2}\hskip0.1em {\mathrm{s}}^{-1} $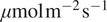 . Further analysis of SHAP values indicates that higher diffuse radiation (DiffPAR) is associated with more negative NEE (stronger carbon sink). SHAP analysis highlights this effect much more clearly than raw DiffPAR measurements, because it accounts for interactions with other environmental factors. This suggests that the diffuse radiation effect emerges from interactions between DiffPAR and co-varying environmental factors (such as cloudiness and total PAR). Cases identified by SHAP ($ \mathrm{DiffPAR}\ \mathrm{SHAP}<-2 $
. Further analysis of SHAP values indicates that higher diffuse radiation (DiffPAR) is associated with more negative NEE (stronger carbon sink). SHAP analysis highlights this effect much more clearly than raw DiffPAR measurements, because it accounts for interactions with other environmental factors. This suggests that the diffuse radiation effect emerges from interactions between DiffPAR and co-varying environmental factors (such as cloudiness and total PAR). Cases identified by SHAP ($ \mathrm{DiffPAR}\ \mathrm{SHAP}<-2 $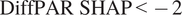 ) have a median NEE $ 1.55\mu \mathrm{mol},{\mathrm{m}}^{-2},{\mathrm{s}}^{-1} $
) have a median NEE $ 1.55\mu \mathrm{mol},{\mathrm{m}}^{-2},{\mathrm{s}}^{-1} $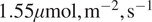 more negative than cases with raw $ \mathrm{DiffPAR}\ge 400 $
more negative than cases with raw $ \mathrm{DiffPAR}\ge 400 $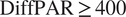 . When applied to ML models, SHAP uncovers nonlinear, context-dependent interactions between diffuse radiation and other drivers of NEE without assuming a priori relationships.
. When applied to ML models, SHAP uncovers nonlinear, context-dependent interactions between diffuse radiation and other drivers of NEE without assuming a priori relationships.
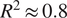
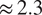
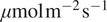
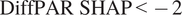
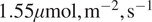
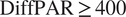
Life cycle cost estimation in product-service systems: a review of machine learning methods
-
- Journal:
- Proceedings of the Design Society / Volume 6 / August 2026
- Published online by Cambridge University Press:
- 02 July 2026, pp. 2511-2520
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Calibrated conformal prediction intervals for microphysical process rates
- Part of
-
- Journal:
- Environmental Data Science / Volume 5 / 2026
- Published online by Cambridge University Press:
- 02 July 2026, e14
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Graph retrieval-augmented generation for enhancing LLM-based ML algorithm recommendation in product development
-
- Journal:
- Proceedings of the Design Society / Volume 6 / August 2026
- Published online by Cambridge University Press:
- 02 July 2026, pp. 2551-2560
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Large-scale bird surveillance technology using operational weather radar
-
- Journal:
- The Aeronautical Journal , First View
- Published online by Cambridge University Press:
- 26 June 2026, pp. 1-26
-
- Article
- Export citation
Predicting Thoroughbred Yearling Auction Prices with Machine Learning: Evidence from the Keeneland September Sale
-
- Journal:
- Journal of Agricultural and Applied Economics , FirstView
- Published online by Cambridge University Press:
- 26 June 2026, pp. 1-19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
26 - Some Further Topics
- from Part IV - Network Inference
-
- Book:
- Networks
- Published online:
- 11 June 2026
- Print publication:
- 25 June 2026, pp 848-865
-
- Chapter
- Export citation
The Intellectual Inheritance of Machine Learning and the Ethics of Algorithmic War
-
- Journal:
- Ethics & International Affairs , First View
- Published online by Cambridge University Press:
- 25 June 2026, pp. 1-26
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Sarcopenia risk assessment among physically inactive middle-aged and older adults: interpretable machine-learning models in UK and US cohorts
-
- Journal:
- Primary Health Care Research & Development / Volume 27 / 2026
- Published online by Cambridge University Press:
- 24 June 2026, e71
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Experimental deep reinforcement learning control of the aerofoil flow separation with a plasma actuator
-
- Journal:
- Journal of Fluid Mechanics / Volume 1037 / 25 June 2026
- Published online by Cambridge University Press:
- 24 June 2026, A64
-
- Article
- Export citation
-
In this study, experimental deep reinforcement learning (DRL) control of aerofoil flow separation is conducted at a chord-based Reynolds number of
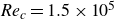 ${\textit{Re}}_c=1.5\times 10^5$. A dielectric barrier discharge plasma actuator mounted at the leading edge and a hotwire placed in the separated shear layer act as the flow disturber and the state monitor, respectively. The closed-loop control law is parameterised by a radial basis function network and executed in real time on a field-programmable gate array at 1 kHz. With the aid of a deep deterministic policy gradient algorithm, a satisfying closed-loop control strategy can be derived in less than one minute, and the resulting lift coefficient increment (21 %) is similar to that achieved by the best open-loop control. For stable and effective DRL control, the sensor should be placed at the position with strongest velocity fluctuation, and both time delay and cashing period should be accounted in the reward design. Incorporating historical sensor measurements are beneficial to DRL control, and the optimal history length is approximately equal to the ratio of the local Taylor microscale to the control period. The final control law sought by DRL dictates that strong plasma actuation should only be applied when the flow separation region contracts to a minimum. Statistically, control benefits can be ascribed to both the increase of average reward at each cluster and the elevation of occurrence probabilities of high-reward clusters. Physically, suppression of the aerofoil flow separation is attributed to the excitation of large-scale shear layer vortices, which promotes the momentum exchange between the free stream and the reverse flow.
${\textit{Re}}_c=1.5\times 10^5$. A dielectric barrier discharge plasma actuator mounted at the leading edge and a hotwire placed in the separated shear layer act as the flow disturber and the state monitor, respectively. The closed-loop control law is parameterised by a radial basis function network and executed in real time on a field-programmable gate array at 1 kHz. With the aid of a deep deterministic policy gradient algorithm, a satisfying closed-loop control strategy can be derived in less than one minute, and the resulting lift coefficient increment (21 %) is similar to that achieved by the best open-loop control. For stable and effective DRL control, the sensor should be placed at the position with strongest velocity fluctuation, and both time delay and cashing period should be accounted in the reward design. Incorporating historical sensor measurements are beneficial to DRL control, and the optimal history length is approximately equal to the ratio of the local Taylor microscale to the control period. The final control law sought by DRL dictates that strong plasma actuation should only be applied when the flow separation region contracts to a minimum. Statistically, control benefits can be ascribed to both the increase of average reward at each cluster and the elevation of occurrence probabilities of high-reward clusters. Physically, suppression of the aerofoil flow separation is attributed to the excitation of large-scale shear layer vortices, which promotes the momentum exchange between the free stream and the reverse flow.
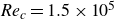
Genetic-algorithm-based control of a turbulent boundary layer
-
- Journal:
- Journal of Fluid Mechanics / Volume 1037 / 25 June 2026
- Published online by Cambridge University Press:
- 22 June 2026, A34
-
- Article
- Export citation
18 - Anthropomorphic Learning
- from Part III - Algorithmic Behaviour
-
-
- Book:
- The Cambridge Handbook of Behavioural Data Science
- Published online:
- 29 May 2026
- Print publication:
- 18 June 2026, pp 321-336
-
- Chapter
- Export citation
13 - Emotion and Big Data
- from Part III - Algorithmic Behaviour
-
-
- Book:
- The Cambridge Handbook of Behavioural Data Science
- Published online:
- 29 May 2026
- Print publication:
- 18 June 2026, pp 223-233
-
- Chapter
- Export citation
41 - On Cryptoasset Traders’ Behaviour
- from Part V - Applications
-
-
- Book:
- The Cambridge Handbook of Behavioural Data Science
- Published online:
- 29 May 2026
- Print publication:
- 18 June 2026, pp 739-755
-
- Chapter
- Export citation
Outlook
-
- Book:
- How Data Need People
- Published online:
- 29 May 2026
- Print publication:
- 18 June 2026, pp 232-236
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
16 - Machine Behaviour
- from Part III - Algorithmic Behaviour
-
-
- Book:
- The Cambridge Handbook of Behavioural Data Science
- Published online:
- 29 May 2026
- Print publication:
- 18 June 2026, pp 287-305
-
- Chapter
- Export citation
Feasibility of diagnosing major depressive disorder with a panel of serum and urine biomarkers
-
- Journal:
- BJPsych Open / Volume 12 / Issue 4 / July 2026
- Published online by Cambridge University Press:
- 15 June 2026, e162
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Mapping of d.i.y. neural networks’ processing data in audiovisual compositions: digital waste, algorithms’ idiosyncrasies, and transfictionality of data-evoking aesthetics
-
- Journal:
- Organised Sound , First View
- Published online by Cambridge University Press:
- 11 June 2026, pp. 1-11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
