Refine search
Actions for selected content:
193 results
Random walks in a time-inhomogeneous random environment conditioned to stay positive
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 24 February 2026, pp. 1-13
-
- Article
- Export citation
Graphical sequences and plane trees
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 35 / Issue 3 / May 2026
- Published online by Cambridge University Press:
- 05 February 2026, pp. 316-328
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Balister, the second author, Groenland, Johnston, and Scott recently showed that there are asymptotically
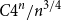 $C4^n/n^{3/4}$ many unordered sequences that occur as degree sequences of graphs with
$C4^n/n^{3/4}$ many unordered sequences that occur as degree sequences of graphs with  $n$ vertices. Combining limit theory for infinitely divisible distributions with a new connection between a class of random walk trajectories and a subset counting formula from additive number theory, we describe
$n$ vertices. Combining limit theory for infinitely divisible distributions with a new connection between a class of random walk trajectories and a subset counting formula from additive number theory, we describe 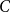 $C$ in terms of Walkup’s number of rooted plane trees. The bijection is related to an instance of the Lévy–Khintchine formula. Our main result complements a result of Stanley, that ordered graphical sequences are related to quasi-forests.
$C$ in terms of Walkup’s number of rooted plane trees. The bijection is related to an instance of the Lévy–Khintchine formula. Our main result complements a result of Stanley, that ordered graphical sequences are related to quasi-forests.

The time until a random walk exceeds a square root and other barriers
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 40 / Issue 1 / January 2026
- Published online by Cambridge University Press:
- 03 September 2025, pp. 146-153
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This paper investigates the time N until a random walk first exceeds some specified barrier. Letting
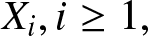 $X_i, i \geq 1,$ be a sequence of independent, identically distributed random variables with a log-concave density or probability mass function, we derive both lower and upper bounds on the probability
$X_i, i \geq 1,$ be a sequence of independent, identically distributed random variables with a log-concave density or probability mass function, we derive both lower and upper bounds on the probability 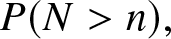 $P(N \gt n),$ as well as bounds on the expected value
$P(N \gt n),$ as well as bounds on the expected value 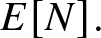 $E[N].$ On barriers of the form
$E[N].$ On barriers of the form 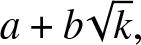 $a + b \sqrt{k},$ where a is nonnegative, b is positive, and k is the number of steps, we provide additional bounds on
$a + b \sqrt{k},$ where a is nonnegative, b is positive, and k is the number of steps, we provide additional bounds on 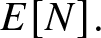 $E[N].$
$E[N].$
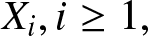
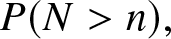
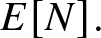
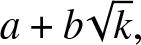
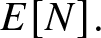
7 - Random Walkers
-
- Book:
- Probability Theory for Quantitative Scientists
- Published online:
- 24 July 2025
- Print publication:
- 14 August 2025, pp 188-216
-
- Chapter
- Export citation
16 - Transport of Radiation from Interior to Surface
- from Part II - Stellar Structure and Evolution
-
- Book:
- Fundamentals of Astrophysics
- Published online:
- 10 November 2025
- Print publication:
- 24 July 2025, pp 107-111
-
- Chapter
- Export citation
Random walks and contracting elements I: deviation inequality and limit laws
- Part of
-
- Journal:
- Compositio Mathematica / Volume 161 / Issue 7 / July 2025
- Published online by Cambridge University Press:
- 17 September 2025, pp. 1512-1575
- Print publication:
- July 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
5 - “Fluctuation” of Intracellular Dynamics
-
- Book:
- Theoretical Biology of the Cell
- Published online:
- 05 June 2025
- Print publication:
- 19 June 2025, pp 135-175
-
- Chapter
- Export citation
Infinite-horizon Fuk–Nagaev inequalities
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 3 / September 2025
- Published online by Cambridge University Press:
- 16 June 2025, pp. 1076-1088
- Print publication:
- September 2025
-
- Article
- Export citation
2 - Reversible MCMC and Its Scaling
-
- Book:
- Scalable Monte Carlo for Bayesian Learning
- Published online:
- 16 May 2025
- Print publication:
- 05 June 2025, pp 39-61
-
- Chapter
- Export citation
Exact solution to the Chow–Robbins game for almost all n, by using a catalan triangle
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 57 / Issue 4 / December 2025
- Published online by Cambridge University Press:
- 16 May 2025, pp. 1206-1241
- Print publication:
- December 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The payoff in the Chow–Robbins coin-tossing game is the proportion of heads when you stop. Stopping to maximize expectation was addressed by Chow and Robbins (1965), who proved there exist integers
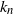 ${k_n}$ such that it is optimal to stop at n tosses when heads minus tails is
${k_n}$ such that it is optimal to stop at n tosses when heads minus tails is  ${k_n}$. Finding
${k_n}$. Finding 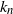 ${k_n}$ was unsolved except for finitely many cases by computer. We prove an
${k_n}$ was unsolved except for finitely many cases by computer. We prove an 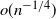 $o(n^{-1/4})$ estimate of the stopping boundary of Dvoretsky (1967), which then proves
$o(n^{-1/4})$ estimate of the stopping boundary of Dvoretsky (1967), which then proves  ${k_n} = \left\lceil {\alpha \sqrt n \,\, - 1/2\,\, + \,\,\frac{{\left( { - 2\zeta (\! -1/2)} \right)\sqrt \alpha }}{{\sqrt \pi }}{n^{ - 1/4}}} \right\rceil $ except for n in a set of density asymptotic to 0, at a power law rate. Here,
${k_n} = \left\lceil {\alpha \sqrt n \,\, - 1/2\,\, + \,\,\frac{{\left( { - 2\zeta (\! -1/2)} \right)\sqrt \alpha }}{{\sqrt \pi }}{n^{ - 1/4}}} \right\rceil $ except for n in a set of density asymptotic to 0, at a power law rate. Here,  $\alpha$ is the Shepp–Walker constant from the Brownian motion analog, and
$\alpha$ is the Shepp–Walker constant from the Brownian motion analog, and  $\zeta$ is Riemann’s zeta function. An
$\zeta$ is Riemann’s zeta function. An  $n^{ - 1/4}$ dependence was conjectured by Christensen and Fischer (2022). Our proof uses moments involving Catalan and Shapiro Catalan triangle numbers which appear in a tree resulting from backward induction, and a generalized backward induction principle. It was motivated by an idea of Häggström and Wästlund (2013) to use backward induction of upper and lower Value bounds from a horizon, which they used numerically to settle a few cases. Christensen and Fischer, with much better bounds, settled many more cases. We use Skorohod’s embedding to get simple upper and lower bounds from the Brownian analog; our upper bound is the one found by Christensen and Fischer in another way. We use them first for yet many more examples and a conjecture, then algebraically in the tree, with feedback to get much sharper Value bounds near the border, and analytic results. Also, we give a formula that gives the exact optimal stop rule for all n up to about a third of a billion; it uses the analytic result plus terms arrived at empirically.
$n^{ - 1/4}$ dependence was conjectured by Christensen and Fischer (2022). Our proof uses moments involving Catalan and Shapiro Catalan triangle numbers which appear in a tree resulting from backward induction, and a generalized backward induction principle. It was motivated by an idea of Häggström and Wästlund (2013) to use backward induction of upper and lower Value bounds from a horizon, which they used numerically to settle a few cases. Christensen and Fischer, with much better bounds, settled many more cases. We use Skorohod’s embedding to get simple upper and lower bounds from the Brownian analog; our upper bound is the one found by Christensen and Fischer in another way. We use them first for yet many more examples and a conjecture, then algebraically in the tree, with feedback to get much sharper Value bounds near the border, and analytic results. Also, we give a formula that gives the exact optimal stop rule for all n up to about a third of a billion; it uses the analytic result plus terms arrived at empirically.
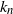
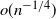




Chapter 10 - The Timescale of Art History
- from Part II - Entangled Timescales of Visual Arts
-
- Book:
- A Complex Systems View on the Visual Arts
- Published online:
- 20 March 2025
- Print publication:
- 03 April 2025, pp 239-302
-
- Chapter
- Export citation
8 - Random Walks
- from Part II - Pricing by Risk-Neutral Expectation
-
- Book:
- Derivatives Pricing
- Published online:
- 08 July 2025
- Print publication:
- 20 March 2025, pp 199-212
-
- Chapter
- Export citation
Continuous-time random walk model for the diffusive motion of helicases
-
- Journal:
- QRB Discovery / Volume 6 / 2025
- Published online by Cambridge University Press:
- 09 October 2025, e26
- Print publication:
- 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
First-passage time for Sinai’s random walk in a random environment
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 2 / June 2025
- Published online by Cambridge University Press:
- 29 November 2024, pp. 756-774
- Print publication:
- June 2025
-
- Article
- Export citation
3 - Influential Observations
-
- Book:
- Ethics in Econometrics
- Published online:
- 14 November 2024
- Print publication:
- 28 November 2024, pp 54-87
-
- Chapter
- Export citation
7 - Spurious Relations
-
- Book:
- Ethics in Econometrics
- Published online:
- 14 November 2024
- Print publication:
- 28 November 2024, pp 161-185
-
- Chapter
- Export citation
Random walks on groups and superlinear-divergent geodesics
- Part of
-
- Journal:
- Ergodic Theory and Dynamical Systems / Volume 45 / Issue 5 / May 2025
- Published online by Cambridge University Press:
- 21 November 2024, pp. 1403-1443
- Print publication:
- May 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
1 - Topics in representation theory of finite groups
-
-
- Book:
- Groups and Graphs, Designs and Dynamics
- Published online:
- 11 May 2024
- Print publication:
- 30 May 2024, pp 1-86
-
- Chapter
- Export citation

Harmonic Functions and Random Walks on Groups
-
- Published online:
- 16 May 2024
- Print publication:
- 23 May 2024
Scaling limit of the local time of random walks conditioned to stay positive
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 13 February 2024, pp. 1060-1074
- Print publication:
- September 2024
-
- Article
- Export citation
