Refine listing
Actions for selected content:
89 results in 94Axx
Quantization dimensions of negative order
- Part of
-
- Journal:
- Mathematical Proceedings of the Cambridge Philosophical Society , First View
- Published online by Cambridge University Press:
- 11 November 2025, pp. 1-25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We investigate the possibility of defining meaningful upper and lower quantization dimensions for a compactly supported Borel probability measure of order r, including negative values of r. To this end, we employ the concept of partition functions, which generalises the notion of the
 $L^q$-spectrum, thus extending the authors’ earlier work with Sanguo Zhu in a natural way. In particular, we derive inherent fractal-geometric bounds and easily verifiable necessary conditions for the existence of quantization dimensions. We state the exact asymptotics of the quantization error of negative order for absolutely continuous measures, thereby providing an affirmative answer to an open question regarding the geometric mean error posed by Graf and Luschgy in this journal in 2004.
$L^q$-spectrum, thus extending the authors’ earlier work with Sanguo Zhu in a natural way. In particular, we derive inherent fractal-geometric bounds and easily verifiable necessary conditions for the existence of quantization dimensions. We state the exact asymptotics of the quantization error of negative order for absolutely continuous measures, thereby providing an affirmative answer to an open question regarding the geometric mean error posed by Graf and Luschgy in this journal in 2004.

Non-parametric estimation of the generalized past entropy function under α-mixing sample
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences , First View
- Published online by Cambridge University Press:
- 05 November 2025, pp. 1-16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Measure of uncertainty in past lifetime distribution plays an important role in the context of information theory, forensic science and other related fields. In the present work, we propose non-parametric kernel type estimator for generalized past entropy function, which was introduced by Gupta and Nanda [9], under
 $\alpha$-mixing sample. The resulting estimator is shown to be weak and strong consistent and asymptotically normally distributed under certain regularity conditions. The performance of the estimator is validated through simulation study and a real data set.
$\alpha$-mixing sample. The resulting estimator is shown to be weak and strong consistent and asymptotically normally distributed under certain regularity conditions. The performance of the estimator is validated through simulation study and a real data set.

Introducing and applying varinaccuracy: a measure for doubly truncated random variables in reliability analysis
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences , First View
- Published online by Cambridge University Press:
- 05 September 2025, pp. 1-27
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Relative entropy bounds for sampling with and without replacement
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 4 / December 2025
- Published online by Cambridge University Press:
- 28 July 2025, pp. 1578-1593
- Print publication:
- December 2025
-
- Article
- Export citation
-
Sharp, nonasymptotic bounds are obtained for the relative entropy between the distributions of sampling with and without replacement from an urn with balls of
 $c\geq 2$ colors. Our bounds are asymptotically tight in certain regimes and, unlike previous results, they depend on the number of balls of each color in the urn. The connection of these results with finite de Finetti-style theorems is explored, and it is observed that a sampling bound due to Stam (1978) combined with the convexity of relative entropy yield a new finite de Finetti bound in relative entropy, which achieves the optimal asymptotic convergence rate.
$c\geq 2$ colors. Our bounds are asymptotically tight in certain regimes and, unlike previous results, they depend on the number of balls of each color in the urn. The connection of these results with finite de Finetti-style theorems is explored, and it is observed that a sampling bound due to Stam (1978) combined with the convexity of relative entropy yield a new finite de Finetti bound in relative entropy, which achieves the optimal asymptotic convergence rate.

Sharp estimates for Gowers norms on discrete cubes
- Part of
-
- Journal:
- Proceedings of the Royal Society of Edinburgh. Section A: Mathematics , First View
- Published online by Cambridge University Press:
- 16 June 2025, pp. 1-27
-
- Article
- Export citation
-
We study optimal dimensionless inequalities
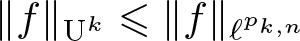 \begin{equation*} \|f\|_{\textrm{U}^k} \leqslant \|f\|_{\ell^{p_{k,n}}} \end{equation*}
\begin{equation*} \|f\|_{\textrm{U}^k} \leqslant \|f\|_{\ell^{p_{k,n}}} \end{equation*}that hold for all functions
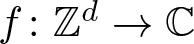 $f\colon\mathbb{Z}^d\to\mathbb{C}$ supported in
$f\colon\mathbb{Z}^d\to\mathbb{C}$ supported in 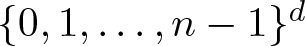 $\{0,1,\ldots,n-1\}^d$ and estimates
$\{0,1,\ldots,n-1\}^d$ and estimates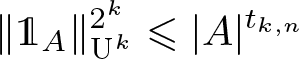 \begin{equation*} \|\mathbb{1}_A\|_{\textrm{U}^k}^{2^k}\leqslant |A|^{t_{k,n}} \end{equation*}
\begin{equation*} \|\mathbb{1}_A\|_{\textrm{U}^k}^{2^k}\leqslant |A|^{t_{k,n}} \end{equation*}that hold for all subsets A of the same discrete cubes. A general theory, analogous to the work of de Dios Pont, Greenfeld, Ivanisvili, and Madrid, is developed to show that the critical exponents are related by
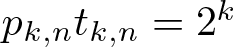 $p_{k,n} t_{k,n} = 2^k$. This is used to prove the three main results of the article:
$p_{k,n} t_{k,n} = 2^k$. This is used to prove the three main results of the article:• an explicit formula for
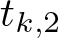 $t_{k,2}$, which generalizes a theorem by Kane and Tao,
$t_{k,2}$, which generalizes a theorem by Kane and Tao,• two-sided asymptotic estimates for
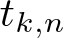 $t_{k,n}$ as
$t_{k,n}$ as 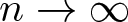 $n\to\infty$ for a fixed
$n\to\infty$ for a fixed 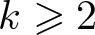 $k\geqslant2$, which generalize a theorem by Shao, and
$k\geqslant2$, which generalize a theorem by Shao, and• a precise asymptotic formula for
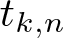 $t_{k,n}$ as
$t_{k,n}$ as 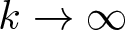 $k\to\infty$ for a fixed
$k\to\infty$ for a fixed 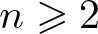 $n\geqslant2$.
$n\geqslant2$.
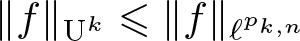
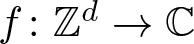
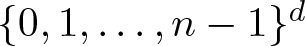
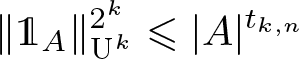
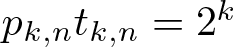
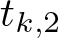
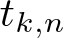
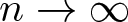
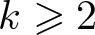
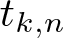
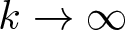
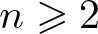
Extropy-based dynamic cumulative residual inaccuracy measure: properties and applications
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 39 / Issue 4 / October 2025
- Published online by Cambridge University Press:
- 26 February 2025, pp. 461-485
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Some generalized information and divergence generating functions: properties, estimation, validation, and applications
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 39 / Issue 3 / July 2025
- Published online by Cambridge University Press:
- 25 February 2025, pp. 397-430
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ON THE BINARY SEQUENCE
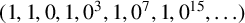 $(1,1,0,1,0^3,1,0^7,1,0^{15},\ldots )$
$(1,1,0,1,0^3,1,0^7,1,0^{15},\ldots )$
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 111 / Issue 2 / April 2025
- Published online by Cambridge University Press:
- 23 October 2024, pp. 260-271
- Print publication:
- April 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Let
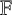 $\mathbb {F}$ be a field and
$\mathbb {F}$ be a field and 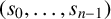 $(s_0,\ldots ,s_{n-1})$ be a finite sequence of elements of
$(s_0,\ldots ,s_{n-1})$ be a finite sequence of elements of  $\mathbb {F}$. In an earlier paper [G. H. Norton, ‘On the annihilator ideal of an inverse form’, J. Appl. Algebra Engrg. Comm. Comput. 28 (2017), 31–78], we used the
$\mathbb {F}$. In an earlier paper [G. H. Norton, ‘On the annihilator ideal of an inverse form’, J. Appl. Algebra Engrg. Comm. Comput. 28 (2017), 31–78], we used the 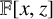 $\mathbb {F}[x,z]$ submodule
$\mathbb {F}[x,z]$ submodule 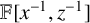 $\mathbb {F}[x^{-1},z^{-1}]$ of Macaulay’s inverse system
$\mathbb {F}[x^{-1},z^{-1}]$ of Macaulay’s inverse system 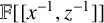 $\mathbb {F}[[x^{-1},z^{-1}]]$ (where z is our homogenising variable) to construct generating forms for the (homogeneous) annihilator ideal of
$\mathbb {F}[[x^{-1},z^{-1}]]$ (where z is our homogenising variable) to construct generating forms for the (homogeneous) annihilator ideal of 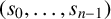 $(s_0,\ldots ,s_{n-1})$. We also gave an
$(s_0,\ldots ,s_{n-1})$. We also gave an 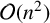 $\mathcal {O}(n^2)$ algorithm to compute a special pair of generating forms of such an annihilator ideal. Here we apply this approach to the sequence r of the title. We obtain special forms generating the annihilator ideal for
$\mathcal {O}(n^2)$ algorithm to compute a special pair of generating forms of such an annihilator ideal. Here we apply this approach to the sequence r of the title. We obtain special forms generating the annihilator ideal for 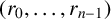 $(r_0,\ldots ,r_{n-1})$ without polynomial multiplication or division, so that the algorithm becomes linear. In particular, we obtain its linear complexities. We also give additional applications of this approach.
$(r_0,\ldots ,r_{n-1})$ without polynomial multiplication or division, so that the algorithm becomes linear. In particular, we obtain its linear complexities. We also give additional applications of this approach.
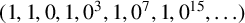
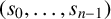
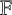
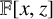
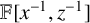
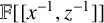
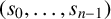
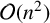
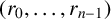
A mathematical theory of super-resolution and two-point resolution
- Part of
-
- Journal:
- Forum of Mathematics, Sigma / Volume 12 / 2024
- Published online by Cambridge University Press:
- 21 October 2024, e83
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This paper focuses on the fundamental aspects of super-resolution, particularly addressing the stability of super-resolution and the estimation of two-point resolution. Our first major contribution is the introduction of two location-amplitude identities that characterize the relationships between locations and amplitudes of true and recovered sources in the one-dimensional super-resolution problem. These identities facilitate direct derivations of the super-resolution capabilities for recovering the number, location, and amplitude of sources, significantly advancing existing estimations to levels of practical relevance. As a natural extension, we establish the stability of a specific
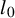 $l_{0}$ minimization algorithm in the super-resolution problem.
$l_{0}$ minimization algorithm in the super-resolution problem.The second crucial contribution of this paper is the theoretical proof of a two-point resolution limit in multi-dimensional spaces. The resolution limit is expressed as
for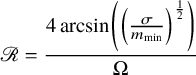 $$\begin{align*}\mathscr R = \frac{4\arcsin \left(\left(\frac{\sigma}{m_{\min}}\right)^{\frac{1}{2}} \right)}{\Omega} \end{align*}$$
$$\begin{align*}\mathscr R = \frac{4\arcsin \left(\left(\frac{\sigma}{m_{\min}}\right)^{\frac{1}{2}} \right)}{\Omega} \end{align*}$$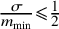 ${\frac {\sigma }{m_{\min }}}{\leqslant }{\frac {1}{2}}$, where
${\frac {\sigma }{m_{\min }}}{\leqslant }{\frac {1}{2}}$, where 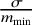 ${\frac {\sigma }{m_{\min }}}$ represents the inverse of the signal-to-noise ratio (
${\frac {\sigma }{m_{\min }}}$ represents the inverse of the signal-to-noise ratio (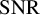 ${\mathrm {SNR}}$) and
${\mathrm {SNR}}$) and  $\Omega $ is the cutoff frequency. It also demonstrates that for resolving two point sources, the resolution can exceed the Rayleigh limit
$\Omega $ is the cutoff frequency. It also demonstrates that for resolving two point sources, the resolution can exceed the Rayleigh limit 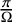 ${\frac {\pi }{\Omega }}$ when the signal-to-noise ratio (SNR) exceeds
${\frac {\pi }{\Omega }}$ when the signal-to-noise ratio (SNR) exceeds 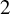 $2$. Moreover, we find a tractable algorithm that achieves the resolution
$2$. Moreover, we find a tractable algorithm that achieves the resolution 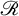 ${\mathscr {R}}$ when distinguishing two sources.
${\mathscr {R}}$ when distinguishing two sources.
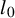
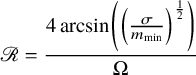
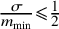
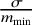
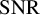

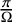
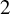
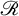
ON A CONJECTURE REGARDING THE SYMMETRIC DIFFERENCE OF CERTAIN SETS
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 111 / Issue 3 / June 2025
- Published online by Cambridge University Press:
- 10 October 2024, pp. 397-404
- Print publication:
- June 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Let n be a positive integer and
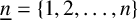 $\underline {n}=\{1,2,\ldots ,n\}$. A conjecture arising from certain polynomial near-ring codes states that if
$\underline {n}=\{1,2,\ldots ,n\}$. A conjecture arising from certain polynomial near-ring codes states that if 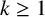 $k\geq 1$ and
$k\geq 1$ and 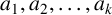 $a_{1},a_{2},\ldots ,a_{k}$ are distinct positive integers, then the symmetric difference
$a_{1},a_{2},\ldots ,a_{k}$ are distinct positive integers, then the symmetric difference 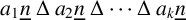 $a_{1}\underline {n}\mathbin {\Delta }a_{2}\underline {n}\mathbin {\Delta }\cdots \mathbin {\Delta }a_{k}\underline {n}$ contains at least n elements. Here,
$a_{1}\underline {n}\mathbin {\Delta }a_{2}\underline {n}\mathbin {\Delta }\cdots \mathbin {\Delta }a_{k}\underline {n}$ contains at least n elements. Here, 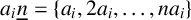 $a_{i}\underline {n}=\{a_{i},2a_{i},\ldots ,na_{i}\}$ for each i. We prove this conjecture for arbitrary n and for
$a_{i}\underline {n}=\{a_{i},2a_{i},\ldots ,na_{i}\}$ for each i. We prove this conjecture for arbitrary n and for 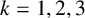 $k=1,2,3$.
$k=1,2,3$.
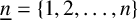
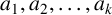
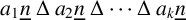
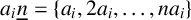
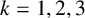
Optimal experimental design: Formulations and computations
- Part of
-
- Journal:
- Acta Numerica / Volume 33 / July 2024
- Published online by Cambridge University Press:
- 04 September 2024, pp. 715-840
-
- Article
-
- You have access
- Open access
- Export citation
Quantile-based information generating functions and their properties and uses
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 4 / October 2024
- Published online by Cambridge University Press:
- 22 May 2024, pp. 733-751
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Phase retrieval on circles and lines
- Part of
-
- Journal:
- Canadian Mathematical Bulletin / Volume 67 / Issue 4 / December 2024
- Published online by Cambridge University Press:
- 10 May 2024, pp. 927-935
- Print publication:
- December 2024
-
- Article
- Export citation
-
Let f and g be analytic functions on the open unit disk
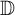 ${\mathbb D}$ such that
${\mathbb D}$ such that  $|f|=|g|$ on a set A. We give an alternative proof of the result of Perez that there exists c in the unit circle
$|f|=|g|$ on a set A. We give an alternative proof of the result of Perez that there exists c in the unit circle  ${\mathbb T}$ such that
${\mathbb T}$ such that  $f=cg$ when A is the union of two lines in
$f=cg$ when A is the union of two lines in 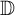 ${\mathbb D}$ intersecting at an angle that is an irrational multiple of
${\mathbb D}$ intersecting at an angle that is an irrational multiple of 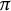 $\pi $, and from this, deduce a sequential generalization of the result. Similarly, the same conclusion is valid when f and g are in the Nevanlinna class and A is the union of the unit circle and an interior circle, tangential or not. We also provide sequential versions of this result and analyze the case
$\pi $, and from this, deduce a sequential generalization of the result. Similarly, the same conclusion is valid when f and g are in the Nevanlinna class and A is the union of the unit circle and an interior circle, tangential or not. We also provide sequential versions of this result and analyze the case  $A=r{\mathbb T}$. Finally, we examine the most general situation when there is equality on two distinct circles in the disk, proving a result or counterexample for each possible configuration.
$A=r{\mathbb T}$. Finally, we examine the most general situation when there is equality on two distinct circles in the disk, proving a result or counterexample for each possible configuration.



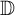
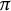

Convergence rate of entropy-regularized multi-marginal optimal transport costs
- Part of
-
- Journal:
- Canadian Journal of Mathematics / Volume 77 / Issue 3 / June 2025
- Published online by Cambridge University Press:
- 15 March 2024, pp. 1072-1092
- Print publication:
- June 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We investigate the convergence rate of multi-marginal optimal transport costs that are regularized with the Boltzmann–Shannon entropy, as the noise parameter
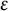 $\varepsilon $ tends to
$\varepsilon $ tends to 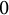 $0$. We establish lower and upper bounds on the difference with the unregularized cost of the form
$0$. We establish lower and upper bounds on the difference with the unregularized cost of the form 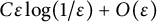 $C\varepsilon \log (1/\varepsilon )+O(\varepsilon )$ for some explicit dimensional constants C depending on the marginals and on the ground cost, but not on the optimal transport plans themselves. Upper bounds are obtained for Lipschitz costs or locally semiconcave costs for a finer estimate, and lower bounds for
$C\varepsilon \log (1/\varepsilon )+O(\varepsilon )$ for some explicit dimensional constants C depending on the marginals and on the ground cost, but not on the optimal transport plans themselves. Upper bounds are obtained for Lipschitz costs or locally semiconcave costs for a finer estimate, and lower bounds for 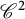 $\mathscr {C}^2$ costs satisfying some signature condition on the mixed second derivatives that may include degenerate costs, thus generalizing results previously in the two marginals case and for nondegenerate costs. We obtain in particular matching bounds in some typical situations where the optimal plan is deterministic.
$\mathscr {C}^2$ costs satisfying some signature condition on the mixed second derivatives that may include degenerate costs, thus generalizing results previously in the two marginals case and for nondegenerate costs. We obtain in particular matching bounds in some typical situations where the optimal plan is deterministic.
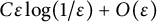
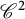
On the Ziv–Merhav theorem beyond Markovianity I
- Part of
-
- Journal:
- Canadian Journal of Mathematics / Volume 77 / Issue 3 / June 2025
- Published online by Cambridge University Press:
- 07 March 2024, pp. 891-915
- Print publication:
- June 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Unified bounds for the independence number of graphs
- Part of
-
- Journal:
- Canadian Journal of Mathematics / Volume 77 / Issue 1 / February 2025
- Published online by Cambridge University Press:
- 11 December 2023, pp. 97-117
- Print publication:
- February 2025
-
- Article
- Export citation
t-Design Curves and Mobile Sampling on the Sphere
- Part of
-
- Journal:
- Forum of Mathematics, Sigma / Volume 11 / 2023
- Published online by Cambridge University Press:
- 23 November 2023, e105
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In analogy to classical spherical t-design points, we introduce the concept of t-design curves on the sphere. This means that the line integral along a t-design curve integrates polynomials of degree t exactly. For low degrees, we construct explicit examples. We also derive lower asymptotic bounds on the lengths of t-design curves. Our main results prove the existence of asymptotically optimal t-design curves in the Euclidean
 $2$-sphere and the existence of t-design curves in the d-sphere.
$2$-sphere and the existence of t-design curves in the d-sphere.
Approximate discrete entropy monotonicity for log-concave sums
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 2 / March 2024
- Published online by Cambridge University Press:
- 13 November 2023, pp. 196-209
-
- Article
- Export citation
-
It is proven that a conjecture of Tao (2010) holds true for log-concave random variables on the integers: For every
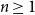 $n \geq 1$, if
$n \geq 1$, if 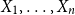 $X_1,\ldots,X_n$ are i.i.d. integer-valued, log-concave random variables, thenas
$X_1,\ldots,X_n$ are i.i.d. integer-valued, log-concave random variables, thenas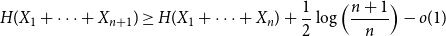 \begin{equation*} H(X_1+\cdots +X_{n+1}) \geq H(X_1+\cdots +X_{n}) + \frac {1}{2}\log {\Bigl (\frac {n+1}{n}\Bigr )} - o(1) \end{equation*}
\begin{equation*} H(X_1+\cdots +X_{n+1}) \geq H(X_1+\cdots +X_{n}) + \frac {1}{2}\log {\Bigl (\frac {n+1}{n}\Bigr )} - o(1) \end{equation*}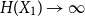 $H(X_1) \to \infty$, where
$H(X_1) \to \infty$, where 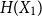 $H(X_1)$ denotes the (discrete) Shannon entropy. The problem is reduced to the continuous setting by showing that if
$H(X_1)$ denotes the (discrete) Shannon entropy. The problem is reduced to the continuous setting by showing that if 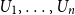 $U_1,\ldots,U_n$ are independent continuous uniforms on
$U_1,\ldots,U_n$ are independent continuous uniforms on 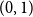 $(0,1)$, thenas
$(0,1)$, thenas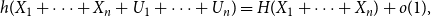 \begin{equation*} h(X_1+\cdots +X_n + U_1+\cdots +U_n) = H(X_1+\cdots +X_n) + o(1), \end{equation*}
\begin{equation*} h(X_1+\cdots +X_n + U_1+\cdots +U_n) = H(X_1+\cdots +X_n) + o(1), \end{equation*}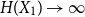 $H(X_1) \to \infty$, where
$H(X_1) \to \infty$, where 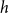 $h$ stands for the differential entropy. Explicit bounds for the
$h$ stands for the differential entropy. Explicit bounds for the 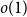 $o(1)$-terms are provided.
$o(1)$-terms are provided.
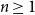
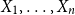
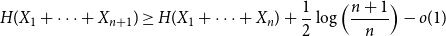
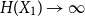
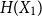
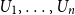
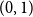
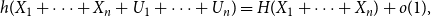
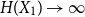
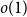
Markov capacity for factor codes with an unambiguous symbol
- Part of
-
- Journal:
- Ergodic Theory and Dynamical Systems / Volume 44 / Issue 8 / August 2024
- Published online by Cambridge University Press:
- 07 November 2023, pp. 2199-2228
- Print publication:
- August 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The unified extropy and its versions in classical and Dempster–Shafer theories
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 23 October 2023, pp. 685-696
- Print publication:
- June 2024
-
- Article
- Export citation
