Refine listing
Actions for selected content:
304 results in 60Cxx
New improved bounds for reliability of consecutive-k-out-of-n:F systems
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 37 / Issue 4 / December 2000
- Published online by Cambridge University Press:
- 14 July 2016, pp. 1164-1170
- Print publication:
- December 2000
-
- Article
- Export citation
Oriented graphs generated by random points on a circle
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 37 / Issue 2 / June 2000
- Published online by Cambridge University Press:
- 14 July 2016, pp. 534-539
- Print publication:
- June 2000
-
- Article
- Export citation
Asymptotic properties of the connectivity number of random railways
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 31 / Issue 3 / September 1999
- Published online by Cambridge University Press:
- 01 July 2016, pp. 720-741
- Print publication:
- September 1999
-
- Article
- Export citation
On the size of a random sphere of influence graph
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 31 / Issue 3 / September 1999
- Published online by Cambridge University Press:
- 01 July 2016, pp. 596-609
- Print publication:
- September 1999
-
- Article
- Export citation
The Brownian excursion multi-dimensional local time density
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 36 / Issue 2 / June 1999
- Published online by Cambridge University Press:
- 14 July 2016, pp. 350-373
- Print publication:
- June 1999
-
- Article
- Export citation
Asymptotics of poisson approximation to random discrete distributions: an analytic approach
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 31 / Issue 2 / June 1999
- Published online by Cambridge University Press:
- 01 July 2016, pp. 448-491
- Print publication:
- June 1999
-
- Article
- Export citation
The Frobenius–Harper technique in a general recurrence model
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 36 / Issue 1 / March 1999
- Published online by Cambridge University Press:
- 14 July 2016, pp. 30-47
- Print publication:
- March 1999
-
- Article
- Export citation
Exact distribution of word occurrences in a random sequence of letters
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 36 / Issue 1 / March 1999
- Published online by Cambridge University Press:
- 14 July 2016, pp. 179-193
- Print publication:
- March 1999
-
- Article
- Export citation
Asymptotic probabilities in a sequential urn scheme related to the matchbox problem
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 30 / Issue 3 / September 1998
- Published online by Cambridge University Press:
- 01 July 2016, pp. 831-849
- Print publication:
- September 1998
-
- Article
- Export citation
Inequalities for multinomial allocations with application to DNA fingerprinting
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 35 / Issue 3 / September 1998
- Published online by Cambridge University Press:
- 14 July 2016, pp. 707-717
- Print publication:
- September 1998
-
- Article
- Export citation
The Minimum Vertex Degree of a Graph on Uniform Points in [0, 1]d
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 29 / Issue 3 / September 1997
- Published online by Cambridge University Press:
- 01 July 2016, pp. 582-594
- Print publication:
- September 1997
-
- Article
- Export citation
-
This article continues an investigation begun in [2]. A random graph Gn (x) is constructed on independent random points U 1, · ··, Un distributed uniformly on [0, 1]d , d ≧ 1, in which two distinct such points are joined by an edge if the l ∞-distance between them is at most some prescribed value 0 < x < 1.
Almost-sure asymptotic results are obtained for the convergence/divergence of the minimum vertex degree of the random graph, as the number n of points becomes large and the edge distance x is allowed to vary with n. The largest nearest neighbor link dn, the smallest x such that Gn (x) has no vertices of degree zero, is shown to satisfy
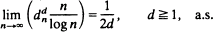 Series and sequence criteria on edge distances {xn} are provided which guarantee the random graph to be complete, a.s. These criteria imply a.s. limiting behavior of the diameter of the vertex set.
Series and sequence criteria on edge distances {xn} are provided which guarantee the random graph to be complete, a.s. These criteria imply a.s. limiting behavior of the diameter of the vertex set.
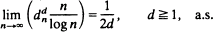
The Maximum Vertex Degree of a Graph on Uniform Points in [0, 1]d
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 29 / Issue 3 / September 1997
- Published online by Cambridge University Press:
- 01 July 2016, pp. 567-581
- Print publication:
- September 1997
-
- Article
- Export citation
Dimensioning a multiple hashing scheme
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 34 / Issue 2 / June 1997
- Published online by Cambridge University Press:
- 14 July 2016, pp. 477-486
- Print publication:
- June 1997
-
- Article
- Export citation
Duration of a secretary problem
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 34 / Issue 2 / June 1997
- Published online by Cambridge University Press:
- 14 July 2016, pp. 556-558
- Print publication:
- June 1997
-
- Article
- Export citation
Convergence properties of simulated annealing for continuous global optimization
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 33 / Issue 4 / December 1996
- Published online by Cambridge University Press:
- 14 July 2016, pp. 1127-1140
- Print publication:
- December 1996
-
- Article
- Export citation
Shortest common superstrings of random strings
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 33 / Issue 4 / December 1996
- Published online by Cambridge University Press:
- 14 July 2016, pp. 1112-1126
- Print publication:
- December 1996
-
- Article
- Export citation
A central limit theorem for the parsimony length of trees
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 28 / Issue 4 / December 1996
- Published online by Cambridge University Press:
- 01 July 2016, pp. 1051-1071
- Print publication:
- December 1996
-
- Article
- Export citation
Stein's method for geometric approximation
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 33 / Issue 3 / September 1996
- Published online by Cambridge University Press:
- 14 July 2016, pp. 707-713
- Print publication:
- September 1996
-
- Article
- Export citation
Une généralisation du modèle de diffusion de Bernoulli–Laplace
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 33 / Issue 3 / September 1996
- Published online by Cambridge University Press:
- 14 July 2016, pp. 688-697
- Print publication:
- September 1996
-
- Article
- Export citation
Comparing sums of exchangeable Bernoulli random variables
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 33 / Issue 2 / September 1996
- Published online by Cambridge University Press:
- 14 July 2016, pp. 285-310
- Print publication:
- September 1996
-
- Article
- Export citation
