Refine listing
Actions for selected content:
304 results in 60Cxx
Exact distribution of word counts in shuffled sequences
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 38 / Issue 1 / March 2006
- Published online by Cambridge University Press:
- 01 July 2016, pp. 116-133
- Print publication:
- March 2006
-
- Article
-
- You have access
- Export citation
A probabilistic model for the survivability of cells
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 42 / Issue 4 / December 2005
- Published online by Cambridge University Press:
- 14 July 2016, pp. 919-931
- Print publication:
- December 2005
-
- Article
-
- You have access
- Export citation
Queues, stores, and tableaux
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 42 / Issue 4 / December 2005
- Published online by Cambridge University Press:
- 14 July 2016, pp. 1145-1167
- Print publication:
- December 2005
-
- Article
-
- You have access
- Export citation
Width of a scale-free tree
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 42 / Issue 3 / September 2005
- Published online by Cambridge University Press:
- 14 July 2016, pp. 839-850
- Print publication:
- September 2005
-
- Article
-
- You have access
- Export citation
-
Consider the random graph model of Barabási and Albert, where we add a new vertex in every step and connect it to some old vertices with probabilities proportional to their degrees. If we connect it to only one of the old vertices then this will be a tree. These graphs have been shown to have a power-law degree distribution, the same as that observed in some large real-world networks. We are interested in the width of the tree and we show that it is
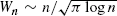 at the nth step; this also holds for a slight generalization of the model with another constant. We then see how this theoretical result can be applied to directory trees.
at the nth step; this also holds for a slight generalization of the model with another constant. We then see how this theoretical result can be applied to directory trees.
 at the
at the Berry-Esseen bounds for combinatorial central limit theorems and pattern occurrences, using zero and size biasing
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 42 / Issue 3 / September 2005
- Published online by Cambridge University Press:
- 14 July 2016, pp. 661-683
- Print publication:
- September 2005
-
- Article
-
- You have access
- Export citation
Gaussian polytopes: variances and limit theorems
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 37 / Issue 2 / June 2005
- Published online by Cambridge University Press:
- 01 July 2016, pp. 297-320
- Print publication:
- June 2005
-
- Article
-
- You have access
- Export citation
Profiles of random trees: correlation and width of random recursive trees and binary search trees
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 37 / Issue 2 / June 2005
- Published online by Cambridge University Press:
- 01 July 2016, pp. 321-341
- Print publication:
- June 2005
-
- Article
-
- You have access
- Export citation
On the number of vertices with a given degree in a Galton-Watson tree
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 37 / Issue 1 / March 2005
- Published online by Cambridge University Press:
- 01 July 2016, pp. 229-264
- Print publication:
- March 2005
-
- Article
-
- You have access
- Export citation
On the fundamental theorem of card counting, with application to the game of trente et quarante
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 37 / Issue 1 / March 2005
- Published online by Cambridge University Press:
- 01 July 2016, pp. 90-107
- Print publication:
- March 2005
-
- Article
-
- You have access
- Export citation
On a deposition process on the circle with disorder
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 36 / Issue 4 / December 2004
- Published online by Cambridge University Press:
- 01 July 2016, pp. 996-1020
- Print publication:
- December 2004
-
- Article
- Export citation
Bose-Einstein-type statistics, order statistics and planar random motions with three directions
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 36 / Issue 3 / September 2004
- Published online by Cambridge University Press:
- 01 July 2016, pp. 937-970
- Print publication:
- September 2004
-
- Article
- Export citation
-
In this paper we study different types of planar random motions (performed with constant velocity) with three directions, defined by the vectors d j = (cos(2πj/3), sin(2πj/3)) for j = 0, 1, 2, changing at Poisson-paced times. We examine the cyclic motion (where the change of direction is deterministic), the completely uniform motion (where at each Poisson event each direction can be taken with probability
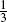 ) and the symmetrically deviating case (where the particle can choose all directions except that taken before the Poisson event). For each of the above random motions we derive the explicit distribution of the position of the particle, by using an approach based on order statistics. We prove that the densities obtained are solutions of the partial differential equations governing the processes. We are also able to give the explicit distributions on the boundary and, for the case of the symmetrically deviating motion, we can write it as the distribution of a telegraph process. For the symmetrically deviating motion we use a generalization of the Bose-Einstein statistics in order to determine the distribution of the triple (N 0, N 1, N 2) (conditional on N(t) = k, with N 0 + N 1 + N 2= N(t) + 1, where N(t) is the number of Poisson events in [0, t]), where N j denotes the number of times the direction d j (j = 0, 1, 2) is taken. Possible extensions to four directions or more are briefly considered.
) and the symmetrically deviating case (where the particle can choose all directions except that taken before the Poisson event). For each of the above random motions we derive the explicit distribution of the position of the particle, by using an approach based on order statistics. We prove that the densities obtained are solutions of the partial differential equations governing the processes. We are also able to give the explicit distributions on the boundary and, for the case of the symmetrically deviating motion, we can write it as the distribution of a telegraph process. For the symmetrically deviating motion we use a generalization of the Bose-Einstein statistics in order to determine the distribution of the triple (N 0, N 1, N 2) (conditional on N(t) = k, with N 0 + N 1 + N 2= N(t) + 1, where N(t) is the number of Poisson events in [0, t]), where N j denotes the number of times the direction d j (j = 0, 1, 2) is taken. Possible extensions to four directions or more are briefly considered.
 ) and the symmetrically deviating case (where the particle can choose all directions except that taken before the Poisson event). For each of the above random motions we derive the explicit distribution of the position of the particle, by using an approach based on order statistics. We prove that the densities obtained are solutions of the partial differential equations governing the processes. We are also able to give the explicit distributions on the boundary and, for the case of the symmetrically deviating motion, we can write it as the distribution of a telegraph process. For the symmetrically deviating motion we use a generalization of the Bose-Einstein statistics in order to determine the distribution of the triple (
) and the symmetrically deviating case (where the particle can choose all directions except that taken before the Poisson event). For each of the above random motions we derive the explicit distribution of the position of the particle, by using an approach based on order statistics. We prove that the densities obtained are solutions of the partial differential equations governing the processes. We are also able to give the explicit distributions on the boundary and, for the case of the symmetrically deviating motion, we can write it as the distribution of a telegraph process. For the symmetrically deviating motion we use a generalization of the Bose-Einstein statistics in order to determine the distribution of the triple (Mixed distributions in Sattolo's algorithm for cyclic permutations via randomization and derandomization
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 40 / Issue 3 / September 2003
- Published online by Cambridge University Press:
- 14 July 2016, pp. 790-796
- Print publication:
- September 2003
-
- Article
- Export citation
The coupon-collector's problem revisited
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 40 / Issue 2 / June 2003
- Published online by Cambridge University Press:
- 14 July 2016, pp. 513-518
- Print publication:
- June 2003
-
- Article
- Export citation
An almost sure result for path lengths in binary search trees
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 35 / Issue 2 / June 2003
- Published online by Cambridge University Press:
- 22 February 2016, pp. 363-376
- Print publication:
- June 2003
-
- Article
- Export citation
Sooner and later waiting time problems for patterns in Markov dependent trials
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 40 / Issue 1 / March 2003
- Published online by Cambridge University Press:
- 14 July 2016, pp. 73-86
- Print publication:
- March 2003
-
- Article
- Export citation
Compound random mappings
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 39 / Issue 4 / December 2002
- Published online by Cambridge University Press:
- 14 July 2016, pp. 712-729
- Print publication:
- December 2002
-
- Article
- Export citation
Breakage and restoration in recursive trees
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 39 / Issue 2 / June 2002
- Published online by Cambridge University Press:
- 14 July 2016, pp. 383-390
- Print publication:
- June 2002
-
- Article
- Export citation
The coupon subset collection problem
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 38 / Issue 3 / September 2001
- Published online by Cambridge University Press:
- 14 July 2016, pp. 737-746
- Print publication:
- September 2001
-
- Article
- Export citation
Upper bounds for the probability of a union by multitrees
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 33 / Issue 2 / June 2001
- Published online by Cambridge University Press:
- 01 July 2016, pp. 437-452
- Print publication:
- June 2001
-
- Article
- Export citation
Local matching of random restriction maps
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 38 / Issue 2 / June 2001
- Published online by Cambridge University Press:
- 14 July 2016, pp. 335-356
- Print publication:
- June 2001
-
- Article
- Export citation
