Refine listing
Actions for selected content:
532 results in 60Exx
Negative Association Does not Imply Log-Concavity of the Rank Sequence
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 44 / Issue 4 / December 2007
- Published online by Cambridge University Press:
- 14 July 2016, pp. 1119-1121
- Print publication:
- December 2007
-
- Article
-
- You have access
- Export citation
Characterizations of Conditional Comonotonicity
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 44 / Issue 3 / September 2007
- Published online by Cambridge University Press:
- 14 July 2016, pp. 607-617
- Print publication:
- September 2007
-
- Article
-
- You have access
- Export citation
A Stochastic Maximin Fixed-Point Equation Related to Game Tree Evaluation
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 44 / Issue 3 / September 2007
- Published online by Cambridge University Press:
- 14 July 2016, pp. 586-606
- Print publication:
- September 2007
-
- Article
-
- You have access
- Export citation
-
After suitable normalization the asymptotic root value W of a minimax game tree of order b ≥ 2 with independent and identically distributed input values having a continuous, strictly increasing distribution function on a subinterval of R appears to be a particular solution of the stochastic maximin fixed-point equation W
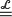 ξ max1≤i≤b min1≤j≤b W i,j , where W i,j are independent copies of W and denotes equality in law. Moreover, ξ= g'(α) > 1, where g(x) := (1 − (1 − x)b )b and α denotes the unique fixed point of g in (0, 1). This equation, which takes the form F(t) = g(F(t/ξ)) in terms of the distribution function F of W, is studied in the present paper for a reasonably extended class of functions g so as to encompass more general stochastic maximin equations as well. A complete description of the set of solutions F is provided followed by a discussion of additional properties such as continuity, differentiability, or existence of moments. Based on these results, it is further shown that the particular solution mentioned above stands out among all other ones in that its distribution function is the restriction of an entire function to the real line. This extends recent work of Ali Khan, Devroye and Neininger (2005). A connection with another class of stochastic fixed-point equations for weighted minima and maxima is also discussed.
ξ max1≤i≤b min1≤j≤b W i,j , where W i,j are independent copies of W and denotes equality in law. Moreover, ξ= g'(α) > 1, where g(x) := (1 − (1 − x)b )b and α denotes the unique fixed point of g in (0, 1). This equation, which takes the form F(t) = g(F(t/ξ)) in terms of the distribution function F of W, is studied in the present paper for a reasonably extended class of functions g so as to encompass more general stochastic maximin equations as well. A complete description of the set of solutions F is provided followed by a discussion of additional properties such as continuity, differentiability, or existence of moments. Based on these results, it is further shown that the particular solution mentioned above stands out among all other ones in that its distribution function is the restriction of an entire function to the real line. This extends recent work of Ali Khan, Devroye and Neininger (2005). A connection with another class of stochastic fixed-point equations for weighted minima and maxima is also discussed.
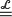 ξ max
ξ maxConvolution Equivalence and Infinite Divisibility: Corrections and Corollaries
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 44 / Issue 2 / June 2007
- Published online by Cambridge University Press:
- 14 July 2016, pp. 295-305
- Print publication:
- June 2007
-
- Article
-
- You have access
- Export citation
First-crossing and ballot-type results for some nonstationary sequences
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 39 / Issue 2 / June 2007
- Published online by Cambridge University Press:
- 01 July 2016, pp. 492-509
- Print publication:
- June 2007
-
- Article
-
- You have access
- Export citation
Mean Residual Lifetimes of Consecutive-k-out-of-n Systems
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 44 / Issue 1 / March 2007
- Published online by Cambridge University Press:
- 14 July 2016, pp. 82-98
- Print publication:
- March 2007
-
- Article
-
- You have access
- Export citation
Arbitrary Threshold Widths for Monotone, Symmetric Properties
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 44 / Issue 1 / March 2007
- Published online by Cambridge University Press:
- 14 July 2016, pp. 164-180
- Print publication:
- March 2007
-
- Article
-
- You have access
- Export citation
Thou Shalt not Diversify: Why ‘Two Of Every Sort’?
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 44 / Issue 1 / March 2007
- Published online by Cambridge University Press:
- 14 July 2016, pp. 58-70
- Print publication:
- March 2007
-
- Article
-
- You have access
- Export citation
On Generating Functions of Waiting Times and Numbers of Occurrences of Compound Patterns in a Sequence of Multistate Trials
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 44 / Issue 1 / March 2007
- Published online by Cambridge University Press:
- 14 July 2016, pp. 71-81
- Print publication:
- March 2007
-
- Article
-
- You have access
- Export citation
Comparison Results for Branching Processes in Random Environments
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 44 / Issue 1 / March 2007
- Published online by Cambridge University Press:
- 14 July 2016, pp. 142-150
- Print publication:
- March 2007
-
- Article
-
- You have access
- Export citation
Study of a Stochastic Failure Model in a Random Environment
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 44 / Issue 1 / March 2007
- Published online by Cambridge University Press:
- 14 July 2016, pp. 151-163
- Print publication:
- March 2007
-
- Article
-
- You have access
- Export citation
General convex stochastic orderings and related martingale-type structures
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 39 / Issue 1 / March 2007
- Published online by Cambridge University Press:
- 01 July 2016, pp. 105-127
- Print publication:
- March 2007
-
- Article
-
- You have access
- Export citation
Exact distributions for reward functions on semi-Markov and Markov additive processes
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 43 / Issue 4 / December 2006
- Published online by Cambridge University Press:
- 14 July 2016, pp. 1053-1065
- Print publication:
- December 2006
-
- Article
-
- You have access
- Export citation
Multivariate subexponential distributions and random sums of random vectors
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 38 / Issue 4 / December 2006
- Published online by Cambridge University Press:
- 08 September 2016, pp. 1028-1046
- Print publication:
- December 2006
-
- Article
-
- You have access
- Export citation
Genealogy for supercritical branching processes
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 43 / Issue 4 / December 2006
- Published online by Cambridge University Press:
- 14 July 2016, pp. 1066-1076
- Print publication:
- December 2006
-
- Article
-
- You have access
- Export citation
A relation between positive dependence of signal and the variability of conditional expectation given signal
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 43 / Issue 4 / December 2006
- Published online by Cambridge University Press:
- 14 July 2016, pp. 1181-1185
- Print publication:
- December 2006
-
- Article
-
- You have access
- Export citation
Stochastic orders and majorization of mean order statistics
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 43 / Issue 3 / September 2006
- Published online by Cambridge University Press:
- 14 July 2016, pp. 704-712
- Print publication:
- September 2006
-
- Article
-
- You have access
- Export citation
Asymptotics of the density of the supremum of a random walk with heavy-tailed increments
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 43 / Issue 3 / September 2006
- Published online by Cambridge University Press:
- 14 July 2016, pp. 874-879
- Print publication:
- September 2006
-
- Article
-
- You have access
- Export citation
A discrete multivariate distribution resulting from the law of small numbers
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 43 / Issue 3 / September 2006
- Published online by Cambridge University Press:
- 14 July 2016, pp. 852-866
- Print publication:
- September 2006
-
- Article
-
- You have access
- Export citation
On stochastic recursive equations of sum and max type
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 43 / Issue 3 / September 2006
- Published online by Cambridge University Press:
- 14 July 2016, pp. 687-703
- Print publication:
- September 2006
-
- Article
-
- You have access
- Export citation
-
In this paper we consider stochastic recursive equations of sum type,
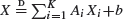 , and of max type,
, and of max type, 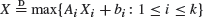 , where A i , b i , and b are random, (X i ) are independent, identically distributed copies of X, and
, where A i , b i , and b are random, (X i ) are independent, identically distributed copies of X, and 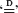 denotes equality in distribution. Equations of these types typically characterize limits in the probabilistic analysis of algorithms, in combinatorial optimization problems, and in many other problems having a recursive structure. We develop some new contraction properties of minimal L s -metrics which allow us to establish general existence and uniqueness results for solutions without imposing any moment conditions. As an application we obtain a one-to-one relationship between the set of solutions to the homogeneous equation and the set of solutions to the inhomogeneous equation, for sum- and max-type equations. We also give a stochastic interpretation of a recent transfer principle of Rösler from nonnegative solutions of sum type to those of max type, by means of random scaled Weibull distributions.
denotes equality in distribution. Equations of these types typically characterize limits in the probabilistic analysis of algorithms, in combinatorial optimization problems, and in many other problems having a recursive structure. We develop some new contraction properties of minimal L s -metrics which allow us to establish general existence and uniqueness results for solutions without imposing any moment conditions. As an application we obtain a one-to-one relationship between the set of solutions to the homogeneous equation and the set of solutions to the inhomogeneous equation, for sum- and max-type equations. We also give a stochastic interpretation of a recent transfer principle of Rösler from nonnegative solutions of sum type to those of max type, by means of random scaled Weibull distributions.
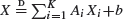 , and of max type,
, and of max type, 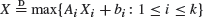 , where A
, where A 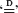 denotes equality in distribution. Equations of these types typically characterize limits in the probabilistic analysis of algorithms, in combinatorial optimization problems, and in many other problems having a recursive structure. We develop some new contraction properties of minimal L
denotes equality in distribution. Equations of these types typically characterize limits in the probabilistic analysis of algorithms, in combinatorial optimization problems, and in many other problems having a recursive structure. We develop some new contraction properties of minimal L 