Refine listing
Actions for selected content:
532 results in 60Exx
Stieltjes classes for moment-indeterminate probability distributions
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 41 / Issue A / 2004
- Published online by Cambridge University Press:
- 14 July 2016, pp. 281-294
- Print publication:
- 2004
-
- Article
- Export citation
-
Let F be a probability distribution function with density f. We assume that (a) F has finite moments of any integer positive order and (b) the classical problem of moments for F has a nonunique solution (F is M-indeterminate). Our goal is to describe a
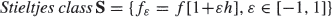 , where h is a ‘small' perturbation function. Such a class S consists of different distributions Fε (fε is the density of Fε ) all sharing the same moments as those of F, thus illustrating the nonuniqueness of F, and of any Fε, in terms of the moments. Power transformations of distributions such as the normal, log-normal and exponential are considered and for them Stieltjes classes written explicitly. We define a characteristic of S called an index of dissimilarity and calculate its value in some cases. A new Stieltjes class involving a power of the normal distribution is presented. An open question about the inverse Gaussian distribution is formulated. Related topics are briefly discussed.
, where h is a ‘small' perturbation function. Such a class S consists of different distributions Fε (fε is the density of Fε ) all sharing the same moments as those of F, thus illustrating the nonuniqueness of F, and of any Fε, in terms of the moments. Power transformations of distributions such as the normal, log-normal and exponential are considered and for them Stieltjes classes written explicitly. We define a characteristic of S called an index of dissimilarity and calculate its value in some cases. A new Stieltjes class involving a power of the normal distribution is presented. An open question about the inverse Gaussian distribution is formulated. Related topics are briefly discussed.
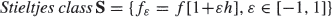 , where h is a ‘small' perturbation function. Such a class
, where h is a ‘small' perturbation function. Such a class Zonoids, linear dependence, and size-biased distributions on the simplex
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 35 / Issue 4 / December 2003
- Published online by Cambridge University Press:
- 01 July 2016, pp. 871-884
- Print publication:
- December 2003
-
- Article
- Export citation
Infinitely divisible approximations for discrete nonlattice variables
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 35 / Issue 4 / December 2003
- Published online by Cambridge University Press:
- 01 July 2016, pp. 982-1006
- Print publication:
- December 2003
-
- Article
- Export citation
On ordered series and later waiting time distributions in a sequence of Markov dependent multistate trials
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 40 / Issue 3 / September 2003
- Published online by Cambridge University Press:
- 14 July 2016, pp. 623-642
- Print publication:
- September 2003
-
- Article
- Export citation
Convergence of lower records and infinite divisibility
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 40 / Issue 4 / September 2003
- Published online by Cambridge University Press:
- 14 July 2016, pp. 865-880
- Print publication:
- September 2003
-
- Article
- Export citation
Geometric bounds on certain sublinear functionals of geometric Brownian motion
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 40 / Issue 4 / September 2003
- Published online by Cambridge University Press:
- 14 July 2016, pp. 893-905
- Print publication:
- September 2003
-
- Article
- Export citation
On the moment problem for random sums
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 40 / Issue 3 / September 2003
- Published online by Cambridge University Press:
- 14 July 2016, pp. 797-802
- Print publication:
- September 2003
-
- Article
- Export citation
Stability and exponential convergence of continuous-time Markov chains
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 40 / Issue 4 / September 2003
- Published online by Cambridge University Press:
- 14 July 2016, pp. 970-979
- Print publication:
- September 2003
-
- Article
- Export citation
From the central limit theorem to heavy-tailed distributions
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 40 / Issue 3 / September 2003
- Published online by Cambridge University Press:
- 14 July 2016, pp. 803-806
- Print publication:
- September 2003
-
- Article
- Export citation
A method for computing total downtime distributions in repairable systems
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 40 / Issue 3 / September 2003
- Published online by Cambridge University Press:
- 14 July 2016, pp. 643-653
- Print publication:
- September 2003
-
- Article
- Export citation
The intersite distances between pattern occurrences in strings generated by general discrete- and continuous-time models: an algorithmic approach
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 40 / Issue 4 / September 2003
- Published online by Cambridge University Press:
- 14 July 2016, pp. 881-892
- Print publication:
- September 2003
-
- Article
- Export citation
Poisson approximation of multivariate Poisson mixtures
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 40 / Issue 2 / June 2003
- Published online by Cambridge University Press:
- 14 July 2016, pp. 376-390
- Print publication:
- June 2003
-
- Article
- Export citation
Symmetric fixed points of a smoothing transformation
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 35 / Issue 2 / June 2003
- Published online by Cambridge University Press:
- 22 February 2016, pp. 377-394
- Print publication:
- June 2003
-
- Article
- Export citation
Stochastic ordering for continuous-time processes
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 40 / Issue 2 / June 2003
- Published online by Cambridge University Press:
- 14 July 2016, pp. 361-375
- Print publication:
- June 2003
-
- Article
- Export citation
On exact and large deviation approximation for the distribution of the longest run in a sequence of two-state Markov dependent trials
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 40 / Issue 2 / June 2003
- Published online by Cambridge University Press:
- 14 July 2016, pp. 346-360
- Print publication:
- June 2003
-
- Article
- Export citation
Characterizations of classes of lifetime distributions generalizing the NBUE class
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 40 / Issue 1 / March 2003
- Published online by Cambridge University Press:
- 14 July 2016, pp. 20-32
- Print publication:
- March 2003
-
- Article
- Export citation
Compound Poisson approximations for sums of discrete nonlattice variables
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 35 / Issue 1 / March 2003
- Published online by Cambridge University Press:
- 01 July 2016, pp. 228-250
- Print publication:
- March 2003
-
- Article
- Export citation
On the distance between the distributions of random sums
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 40 / Issue 1 / March 2003
- Published online by Cambridge University Press:
- 14 July 2016, pp. 87-106
- Print publication:
- March 2003
-
- Article
- Export citation
Sooner and later waiting time problems for patterns in Markov dependent trials
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 40 / Issue 1 / March 2003
- Published online by Cambridge University Press:
- 14 July 2016, pp. 73-86
- Print publication:
- March 2003
-
- Article
- Export citation
The total time on test transform and the excess wealth stochastic orders of distributions
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 34 / Issue 4 / December 2002
- Published online by Cambridge University Press:
- 01 July 2016, pp. 826-845
- Print publication:
- December 2002
-
- Article
- Export citation
