Refine search
Actions for selected content:
49426 results in Computer Science
Frontmatter
-
- Book:
- Cultures of Programming
- Published online:
- 19 December 2025
- Print publication:
- 08 January 2026, pp i-iv
-
- Chapter
-
- You have access
- Open access
- Export citation
Preface
-
- Book:
- Human–Computer Interaction and U.S. Law
- Published online:
- 12 December 2025
- Print publication:
- 08 January 2026, pp xv-xviii
-
- Chapter
- Export citation
Index
-
- Book:
- Human–Computer Interaction and U.S. Law
- Published online:
- 12 December 2025
- Print publication:
- 08 January 2026, pp 263-275
-
- Chapter
- Export citation
4 - Software Engineering
-
- Book:
- Cultures of Programming
- Published online:
- 19 December 2025
- Print publication:
- 08 January 2026, pp 132-190
-
- Chapter
-
- You have access
- Open access
- Export citation
Contents
-
- Book:
- Cultures of Programming
- Published online:
- 19 December 2025
- Print publication:
- 08 January 2026, pp v-viii
-
- Chapter
-
- You have access
- Open access
- Export citation
Index
-
- Book:
- Cultures of Programming
- Published online:
- 19 December 2025
- Print publication:
- 08 January 2026, pp 332-352
-
- Chapter
-
- You have access
- Open access
- Export citation
9 - Dark Patterns
-
- Book:
- Human–Computer Interaction and U.S. Law
- Published online:
- 12 December 2025
- Print publication:
- 08 January 2026, pp 212-229
-
- Chapter
- Export citation
References
-
- Book:
- Cultures of Programming
- Published online:
- 19 December 2025
- Print publication:
- 08 January 2026, pp 309-331
-
- Chapter
-
- You have access
- Open access
- Export citation
7 - Telecommunications
-
- Book:
- Human–Computer Interaction and U.S. Law
- Published online:
- 12 December 2025
- Print publication:
- 08 January 2026, pp 173-197
-
- Chapter
- Export citation
1 - Introduction to Law for Human–Computer Interaction
-
- Book:
- Human–Computer Interaction and U.S. Law
- Published online:
- 12 December 2025
- Print publication:
- 08 January 2026, pp 1-20
-
- Chapter
- Export citation
Congruence relations on domains
-
- Journal:
- Mathematical Structures in Computer Science / Volume 35 / 2025
- Published online by Cambridge University Press:
- 02 January 2026, e40
-
- Article
- Export citation
-
Domains exhibit a variety of different aspects, some are order theoretical, some are topological, some belong to topological algebra. In this paper, we introduce two kinds of congruence relations on domains: I-congruence relation and II-congruence relation on domains. We obtain that there is a bijection from the set of all kernel operators of domain
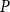 $P$ preserving directed sups onto the set of all I-congruence relations on
$P$ preserving directed sups onto the set of all I-congruence relations on 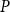 $P$ which exclude
$P$ which exclude 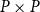 $P\times P$. There is also a bijection from the set of all closure operators of domain
$P\times P$. There is also a bijection from the set of all closure operators of domain 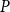 $P$ preserving directed sups onto the set of all II-congruence relations on
$P$ preserving directed sups onto the set of all II-congruence relations on 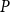 $P$ which exclude
$P$ which exclude 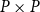 $P\times P$. Furthermore, between two domains, we propose a new homomorphism called I-homomorphism and II-homomorphism, respectively. We conclude that the kernels of I-homomorphisms and II-homomorphisms between domains are I-congruence relations and II-congruence relations on domains, respectively. Therefore, we obtain the I-homomorphism and I-isomorphism theorems, as well as II-homomorphism and II-isomorphism theorems for domains. Besides, we give a positive answer to an open problem on homomorphisms and quotients of continuous semilattices posed by G. Gierz, et al.
$P\times P$. Furthermore, between two domains, we propose a new homomorphism called I-homomorphism and II-homomorphism, respectively. We conclude that the kernels of I-homomorphisms and II-homomorphisms between domains are I-congruence relations and II-congruence relations on domains, respectively. Therefore, we obtain the I-homomorphism and I-isomorphism theorems, as well as II-homomorphism and II-isomorphism theorems for domains. Besides, we give a positive answer to an open problem on homomorphisms and quotients of continuous semilattices posed by G. Gierz, et al.
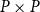
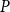
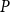
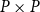
Autonomous Agents and Policy Compliance: A Framework for Reasoning About Penalties
-
- Journal:
- Theory and Practice of Logic Programming , First View
- Published online by Cambridge University Press:
- 02 January 2026, pp. 1-30
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This paper presents a logic programming-based framework for policy-aware autonomous agents that can reason about potential penalties for noncompliance and act accordingly. While prior work has primarily focused on ensuring compliance, our approach considers scenarios where deviating from policies may be necessary to achieve high-stakes goals. Additionally, modeling noncompliant behavior can assist policymakers by simulating realistic human decision-making. Our framework extends Gelfond and Lobo’s Authorization and Obligation Policy Language (
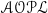 $\mathscr{AOPL}$) to incorporate penalties and integrates Answer Set Programming (ASP) for reasoning. Compared to previous approaches, our method ensures well-formed policies, accounts for policy priorities, and enhances explainability by explicitly identifying rule violations and their consequences. Building on the work of Harders and Inclezan, we introduce penalty-based reasoning to distinguish between noncompliant plans, prioritizing those with minimal repercussions. To support this, we develop an automated translation from the extended
$\mathscr{AOPL}$) to incorporate penalties and integrates Answer Set Programming (ASP) for reasoning. Compared to previous approaches, our method ensures well-formed policies, accounts for policy priorities, and enhances explainability by explicitly identifying rule violations and their consequences. Building on the work of Harders and Inclezan, we introduce penalty-based reasoning to distinguish between noncompliant plans, prioritizing those with minimal repercussions. To support this, we develop an automated translation from the extended 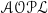 $\mathscr{AOPL}$ into ASP and refine ASP-based planning algorithms to account for incurred penalties. Experiments in two domains demonstrate that our framework generates higher-quality plans that avoid harmful actions while, in some cases, also improving computational efficiency. These findings underscore its potential for enhancing autonomous decision-making and informing policy refinement.
$\mathscr{AOPL}$ into ASP and refine ASP-based planning algorithms to account for incurred penalties. Experiments in two domains demonstrate that our framework generates higher-quality plans that avoid harmful actions while, in some cases, also improving computational efficiency. These findings underscore its potential for enhancing autonomous decision-making and informing policy refinement.
Deductive Systems for Logic Programs with Counting
-
- Journal:
- Theory and Practice of Logic Programming / Volume 25 / Issue 5 / September 2025
- Published online by Cambridge University Press:
- 02 January 2026, pp. 924-964
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Introduction to Neuromorphic Computing
-
- Published online:
- 01 January 2026
- Print publication:
- 22 January 2026

Computer Vision
- Fundamentals and Applications
-
- Published online:
- 31 December 2025
- Print publication:
- 31 March 2026
-
- Textbook
- Export citation

Creative research communication
- Theory and practice
-
- Published by:
- Manchester University Press
- Published online:
- 30 December 2025
