Refine search
Actions for selected content:
48289 results in Computer Science
Chapter 20 - Concluding Thoughts
-
- Book:
- Data Science in Context
- Published online:
- 29 September 2022
- Print publication:
- 20 October 2022, pp 265-277
-
- Chapter
- Export citation
Part IV - Addressing Concerns
-
- Book:
- Data Science in Context
- Published online:
- 29 September 2022
- Print publication:
- 20 October 2022, pp 229-264
-
- Chapter
- Export citation
Chapter 11 - Understandability
- from Part III - Challenges in Applying Data Science
-
- Book:
- Data Science in Context
- Published online:
- 29 September 2022
- Print publication:
- 20 October 2022, pp 154-186
-
- Chapter
- Export citation
References
-
- Book:
- Data Science in Context
- Published online:
- 29 September 2022
- Print publication:
- 20 October 2022, pp 282-305
-
- Chapter
- Export citation
Chapter 1 - Foundations of Data Science
- from Part I - Data Science
-
- Book:
- Data Science in Context
- Published online:
- 29 September 2022
- Print publication:
- 20 October 2022, pp 7-28
-
- Chapter
- Export citation
Chapter 9 - Building and Deploying Models
- from Part III - Challenges in Applying Data Science
-
- Book:
- Data Science in Context
- Published online:
- 29 September 2022
- Print publication:
- 20 October 2022, pp 118-125
-
- Chapter
- Export citation
Recap of Part I: Data Science
- from Part I - Data Science
-
- Book:
- Data Science in Context
- Published online:
- 29 September 2022
- Print publication:
- 20 October 2022, pp 41-44
-
- Chapter
- Export citation
Tables
-
- Book:
- Data Science in Context
- Published online:
- 29 September 2022
- Print publication:
- 20 October 2022, pp xi-xii
-
- Chapter
- Export citation
Appendix - Summary of Recommendations from Part IV
-
- Book:
- Data Science in Context
- Published online:
- 29 September 2022
- Print publication:
- 20 October 2022, pp 278-279
-
- Chapter
- Export citation
Part III - Challenges in Applying Data Science
-
- Book:
- Data Science in Context
- Published online:
- 29 September 2022
- Print publication:
- 20 October 2022, pp 109-228
-
- Chapter
- Export citation
An Application of a Runtime Epistemic Probabilistic Event Calculus to Decision-making in e-Health Systems
-
- Journal:
- Theory and Practice of Logic Programming / Volume 23 / Issue 5 / September 2023
- Published online by Cambridge University Press:
- 20 October 2022, pp. 1070-1093
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Identifying and minimising the impact of fake visual media: Current and future directions
- Part of
-
- Journal:
- Memory, Mind & Media / Volume 1 / 2022
- Published online by Cambridge University Press:
- 20 October 2022, e15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Observing non-uniform, non-Lüders yielding in a cold-rolled medium manganese steel with digital image correlation
-
- Journal:
- Experimental Results / Volume 3 / 2022
- Published online by Cambridge University Press:
- 19 October 2022, e23
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Socio-spatial aspects of creativity and their role in the planning and design of university campuses’ public spaces: A practitioners’ perspective
-
- Journal:
- Data & Policy / Volume 4 / 2022
- Published online by Cambridge University Press:
- 18 October 2022, e35
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Approximately symmetric forms far from being exactly symmetric
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 2 / March 2023
- Published online by Cambridge University Press:
- 18 October 2022, pp. 299-315
-
- Article
- Export citation
-
Let
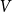 $V$ be a finite-dimensional vector space over
$V$ be a finite-dimensional vector space over 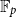 $\mathbb{F}_p$. We say that a multilinear form
$\mathbb{F}_p$. We say that a multilinear form 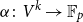 $\alpha \colon V^k \to \mathbb{F}_p$ in
$\alpha \colon V^k \to \mathbb{F}_p$ in 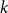 $k$ variables is
$k$ variables is 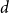 $d$-approximately symmetric if the partition rank of difference
$d$-approximately symmetric if the partition rank of difference 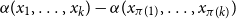 $\alpha (x_1, \ldots, x_k) - \alpha (x_{\pi (1)}, \ldots, x_{\pi (k)})$ is at most
$\alpha (x_1, \ldots, x_k) - \alpha (x_{\pi (1)}, \ldots, x_{\pi (k)})$ is at most 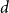 $d$ for every permutation
$d$ for every permutation 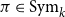 $\pi \in \textrm{Sym}_k$. In a work concerning the inverse theorem for the Gowers uniformity
$\pi \in \textrm{Sym}_k$. In a work concerning the inverse theorem for the Gowers uniformity 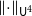 $\|\!\cdot\! \|_{\mathsf{U}^4}$ norm in the case of low characteristic, Tidor conjectured that any
$\|\!\cdot\! \|_{\mathsf{U}^4}$ norm in the case of low characteristic, Tidor conjectured that any 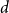 $d$-approximately symmetric multilinear form
$d$-approximately symmetric multilinear form 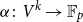 $\alpha \colon V^k \to \mathbb{F}_p$ differs from a symmetric multilinear form by a multilinear form of partition rank at most
$\alpha \colon V^k \to \mathbb{F}_p$ differs from a symmetric multilinear form by a multilinear form of partition rank at most 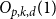 $O_{p,k,d}(1)$ and proved this conjecture in the case of trilinear forms. In this paper, somewhat surprisingly, we show that this conjecture is false. In fact, we show that approximately symmetric forms can be quite far from the symmetric ones, by constructing a multilinear form
$O_{p,k,d}(1)$ and proved this conjecture in the case of trilinear forms. In this paper, somewhat surprisingly, we show that this conjecture is false. In fact, we show that approximately symmetric forms can be quite far from the symmetric ones, by constructing a multilinear form 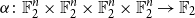 $\alpha \colon \mathbb{F}_2^n \times \mathbb{F}_2^n \times \mathbb{F}_2^n \times \mathbb{F}_2^n \to \mathbb{F}_2$ which is 3-approximately symmetric, while the difference between
$\alpha \colon \mathbb{F}_2^n \times \mathbb{F}_2^n \times \mathbb{F}_2^n \times \mathbb{F}_2^n \to \mathbb{F}_2$ which is 3-approximately symmetric, while the difference between 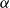 $\alpha$ and any symmetric multilinear form is of partition rank at least
$\alpha$ and any symmetric multilinear form is of partition rank at least 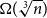 $\Omega (\sqrt [3]{n})$.
$\Omega (\sqrt [3]{n})$.
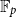
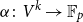
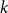
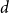
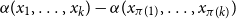
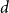
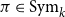
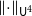
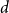
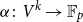
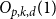
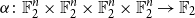
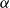
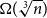
On mappings on the hypercube with small average stretch
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 2 / March 2023
- Published online by Cambridge University Press:
- 18 October 2022, pp. 334-348
-
- Article
- Export citation
-
Let
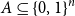 $A \subseteq \{0,1\}^n$ be a set of size
$A \subseteq \{0,1\}^n$ be a set of size 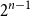 $2^{n-1}$, and let
$2^{n-1}$, and let 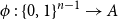 $\phi \,:\, \{0,1\}^{n-1} \to A$ be a bijection. We define the average stretch of
$\phi \,:\, \{0,1\}^{n-1} \to A$ be a bijection. We define the average stretch of 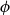 $\phi$ aswhere the expectation is taken over uniformly random
$\phi$ aswhere the expectation is taken over uniformly random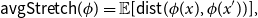 \begin{equation*} {\sf avgStretch}(\phi ) = {\mathbb E}[{{\sf dist}}(\phi (x),\phi (x'))], \end{equation*}
\begin{equation*} {\sf avgStretch}(\phi ) = {\mathbb E}[{{\sf dist}}(\phi (x),\phi (x'))], \end{equation*}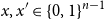 $x,x' \in \{0,1\}^{n-1}$ that differ in exactly one coordinate.
$x,x' \in \{0,1\}^{n-1}$ that differ in exactly one coordinate.In this paper, we continue the line of research studying mappings on the discrete hypercube with small average stretch. We prove the following results.
For any set
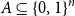 $A \subseteq \{0,1\}^n$ of density
$A \subseteq \{0,1\}^n$ of density 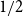 $1/2$ there exists a bijection
$1/2$ there exists a bijection 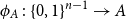 $\phi _A \,:\, \{0,1\}^{n-1} \to A$ such that
$\phi _A \,:\, \{0,1\}^{n-1} \to A$ such that 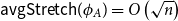 ${\sf avgStretch}(\phi _A) = O\left(\sqrt{n}\right)$.
${\sf avgStretch}(\phi _A) = O\left(\sqrt{n}\right)$.For
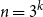 $n = 3^k$ let
$n = 3^k$ let 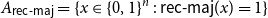 ${A_{\textsf{rec-maj}}} = \{x \in \{0,1\}^n \,:\,{\textsf{rec-maj}}(x) = 1\}$, where
${A_{\textsf{rec-maj}}} = \{x \in \{0,1\}^n \,:\,{\textsf{rec-maj}}(x) = 1\}$, where 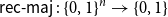 ${\textsf{rec-maj}} \,:\, \{0,1\}^n \to \{0,1\}$ is the function recursive majority of 3’s. There exists a bijection
${\textsf{rec-maj}} \,:\, \{0,1\}^n \to \{0,1\}$ is the function recursive majority of 3’s. There exists a bijection 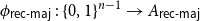 $\phi _{{\textsf{rec-maj}}} \,:\, \{0,1\}^{n-1} \to{A_{\textsf{rec-maj}}}$ such that
$\phi _{{\textsf{rec-maj}}} \,:\, \{0,1\}^{n-1} \to{A_{\textsf{rec-maj}}}$ such that 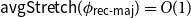 ${\sf avgStretch}(\phi _{{\textsf{rec-maj}}}) = O(1)$.
${\sf avgStretch}(\phi _{{\textsf{rec-maj}}}) = O(1)$.Let
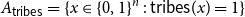 ${A_{{\sf tribes}}} = \{x \in \{0,1\}^n \,:\,{\sf tribes}(x) = 1\}$. There exists a bijection
${A_{{\sf tribes}}} = \{x \in \{0,1\}^n \,:\,{\sf tribes}(x) = 1\}$. There exists a bijection 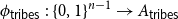 $\phi _{{\sf tribes}} \,:\, \{0,1\}^{n-1} \to{A_{{\sf tribes}}}$ such that
$\phi _{{\sf tribes}} \,:\, \{0,1\}^{n-1} \to{A_{{\sf tribes}}}$ such that 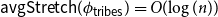 ${\sf avgStretch}(\phi _{{\sf tribes}}) = O(\!\log (n))$.
${\sf avgStretch}(\phi _{{\sf tribes}}) = O(\!\log (n))$.
These results answer the questions raised by Benjamini, Cohen, and Shinkar (Isr. J. Math 2016).
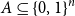
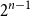
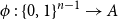
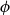
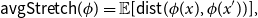
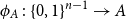
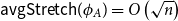
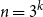
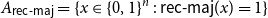
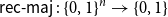
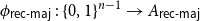
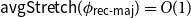
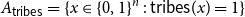
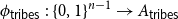
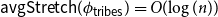
The Collection of Papers Celebrating the 20th Anniversary of TPLP, Part II
-
- Journal:
- Theory and Practice of Logic Programming / Volume 23 / Issue 1 / January 2023
- Published online by Cambridge University Press:
- 18 October 2022, p. 1
-
- Article
-
- You have access
- HTML
- Export citation
Preserving consistency in geometric modeling with graph transformations
-
- Journal:
- Mathematical Structures in Computer Science / Volume 32 / Issue 3 / March 2022
- Published online by Cambridge University Press:
- 18 October 2022, pp. 300-347
-
- Article
- Export citation
A benchmark for evaluating Arabic word embedding models
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 4 / July 2023
- Published online by Cambridge University Press:
- 17 October 2022, pp. 978-1003
-
- Article
- Export citation
High-resolution tropical rain-forest canopy climate data
-
- Journal:
- Environmental Data Science / Volume 1 / 2022
- Published online by Cambridge University Press:
- 17 October 2022, e13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
