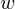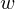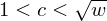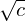Refine listing
Actions for selected content:
130 results in 68Qxx
The replica symmetric phase of random constraint satisfaction problems
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 3 / May 2020
- Published online by Cambridge University Press:
- 03 December 2019, pp. 346-422
-
- Article
- Export citation
A LEARNING-THEORETIC CHARACTERISATION OF MARTIN-LÖF RANDOMNESS AND SCHNORR RANDOMNESS
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 14 / Issue 2 / June 2021
- Published online by Cambridge University Press:
- 04 November 2019, pp. 531-549
- Print publication:
- June 2021
-
- Article
- Export citation
The string of diamonds is nearly tight for rumour spreading
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 2 / March 2020
- Published online by Cambridge University Press:
- 04 November 2019, pp. 190-199
-
- Article
- Export citation
-
For a rumour spreading protocol, the spread time is defined as the first time everyone learns the rumour. We compare the synchronous push&pull rumour spreading protocol with its asynchronous variant, and show that for any n-vertex graph and any starting vertex, the ratio between their expected spread times is bounded by
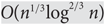 $O({n^{1/3}}{\log ^{2/3}}n)$. This improves the
$O({n^{1/3}}{\log ^{2/3}}n)$. This improves the 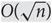 $O(\sqrt n)$ upper bound of Giakkoupis, Nazari and Woelfel (2016). Our bound is tight up to a factor of O(log n), as illustrated by the string of diamonds graph. We also show that if, for a pair α, β of real numbers, there exist infinitely many graphs for which the two spread times are nα and nβ in expectation, then
$O(\sqrt n)$ upper bound of Giakkoupis, Nazari and Woelfel (2016). Our bound is tight up to a factor of O(log n), as illustrated by the string of diamonds graph. We also show that if, for a pair α, β of real numbers, there exist infinitely many graphs for which the two spread times are nα and nβ in expectation, then 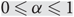 $0 \le \alpha \le 1$ and
$0 \le \alpha \le 1$ and  $\alpha \le \beta \le {1 \over 3} + {2 \over 3} \alpha $; and we show each such pair α, β is achievable.
$\alpha \le \beta \le {1 \over 3} + {2 \over 3} \alpha $; and we show each such pair α, β is achievable.
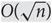
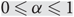

Deciding the Existence of Minority Terms
- Part of
-
- Journal:
- Canadian Mathematical Bulletin / Volume 63 / Issue 3 / September 2020
- Published online by Cambridge University Press:
- 24 October 2019, pp. 577-591
- Print publication:
- September 2020
-
- Article
-
- You have access
- Export citation
-
This paper investigates the computational complexity of deciding if a given finite idempotent algebra has a ternary term operation
 $m$ that satisfies the minority equations
$m$ that satisfies the minority equations 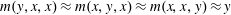 $m(y,x,x)\approx m(x,y,x)\approx m(x,x,y)\approx y$. We show that a common polynomial-time approach to testing for this type of condition will not work in this case and that this decision problem lies in the class
$m(y,x,x)\approx m(x,y,x)\approx m(x,x,y)\approx y$. We show that a common polynomial-time approach to testing for this type of condition will not work in this case and that this decision problem lies in the class NP .

DEGREE BOUNDED GEOMETRIC SPANNING TREES WITH A BOTTLENECK OBJECTIVE FUNCTION
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 101 / Issue 1 / February 2020
- Published online by Cambridge University Press:
- 23 October 2019, pp. 170-171
- Print publication:
- February 2020
-
- Article
-
- You have access
- Export citation
A natural barrier in random greedy hypergraph matching
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 6 / November 2019
- Published online by Cambridge University Press:
- 27 June 2019, pp. 816-825
-
- Article
- Export citation
-
Let r ⩾ 2 be a fixed constant and let
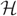 $ {\cal H} $ be an r-uniform, D-regular hypergraph on N vertices. Assume further that D → ∞ as N → ∞ and that degrees of pairs of vertices in
$ {\cal H} $ be an r-uniform, D-regular hypergraph on N vertices. Assume further that D → ∞ as N → ∞ and that degrees of pairs of vertices in 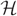 $ {\cal H} $ are at most L where L = D/( log N)ω(1). We consider the random greedy algorithm for forming a matching in
$ {\cal H} $ are at most L where L = D/( log N)ω(1). We consider the random greedy algorithm for forming a matching in 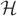 $ {\cal H} $. We choose a matching at random by iteratively choosing edges uniformly at random to be in the matching and deleting all edges that share at least one vertex with a chosen edge before moving on to the next choice. This process terminates when there are no edges remaining in the graph. We show that with high probability the proportion of vertices of
$ {\cal H} $. We choose a matching at random by iteratively choosing edges uniformly at random to be in the matching and deleting all edges that share at least one vertex with a chosen edge before moving on to the next choice. This process terminates when there are no edges remaining in the graph. We show that with high probability the proportion of vertices of 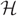 $ {\cal H} $ that are not saturated by the final matching is at most (L/D)(1/(2(r−1)))+o(1). This point is a natural barrier in the analysis of the random greedy hypergraph matching process.
$ {\cal H} $ that are not saturated by the final matching is at most (L/D)(1/(2(r−1)))+o(1). This point is a natural barrier in the analysis of the random greedy hypergraph matching process.
Weighted counting of solutions to sparse systems of equations
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 5 / September 2019
- Published online by Cambridge University Press:
- 15 April 2019, pp. 696-719
-
- Article
- Export citation
-
Given complex numbers w1,…,wn, we define the weight w(X) of a set X of 0–1 vectors as the sum of
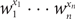 $w_1^{x_1} \cdots w_n^{x_n}$ over all vectors (x1,…,xn) in X. We present an algorithm which, for a set X defined by a system of homogeneous linear equations with at most r variables per equation and at most c equations per variable, computes w(X) within relative error ∊ > 0 in (rc)O(lnn-ln∊) time provided
$w_1^{x_1} \cdots w_n^{x_n}$ over all vectors (x1,…,xn) in X. We present an algorithm which, for a set X defined by a system of homogeneous linear equations with at most r variables per equation and at most c equations per variable, computes w(X) within relative error ∊ > 0 in (rc)O(lnn-ln∊) time provided 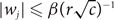 $|w_j| \leq \beta (r \sqrt{c})^{-1}$ for an absolute constant β > 0 and all j = 1,…,n. A similar algorithm is constructed for computing the weight of a linear code over
$|w_j| \leq \beta (r \sqrt{c})^{-1}$ for an absolute constant β > 0 and all j = 1,…,n. A similar algorithm is constructed for computing the weight of a linear code over 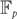 ${\mathbb F}_p$. Applications include counting weighted perfect matchings in hypergraphs, counting weighted graph homomorphisms, computing weight enumerators of linear codes with sparse code generating matrices, and computing the partition functions of the ferromagnetic Potts model at low temperatures and of the hard-core model at high fugacity on biregular bipartite graphs.
${\mathbb F}_p$. Applications include counting weighted perfect matchings in hypergraphs, counting weighted graph homomorphisms, computing weight enumerators of linear codes with sparse code generating matrices, and computing the partition functions of the ferromagnetic Potts model at low temperatures and of the hard-core model at high fugacity on biregular bipartite graphs.
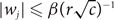
Abelian Logic Gates
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 3 / May 2019
- Published online by Cambridge University Press:
- 13 March 2019, pp. 388-422
-
- Article
- Export citation
Merge Decompositions, Two-sided Krohn–Rhodes, and Aperiodic Pointlikes
- Part of
-
- Journal:
- Canadian Mathematical Bulletin / Volume 62 / Issue 1 / March 2019
- Published online by Cambridge University Press:
- 07 January 2019, pp. 199-208
- Print publication:
- March 2019
-
- Article
-
- You have access
- Export citation
-
This paper provides short proofs of two fundamental theorems of finite semigroup theory whose previous proofs were significantly longer, namely the two-sided Krohn-Rhodes decomposition theorem and Henckell’s aperiodic pointlike theorem. We use a new algebraic technique that we call the merge decomposition. A prototypical application of this technique decomposes a semigroup
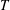 $T$ into a two-sided semidirect product whose components are built from two subsemigroups
$T$ into a two-sided semidirect product whose components are built from two subsemigroups 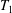 $T_{1}$,
$T_{1}$, 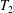 $T_{2}$, which together generate
$T_{2}$, which together generate 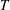 $T$, and the subsemigroup generated by their setwise product
$T$, and the subsemigroup generated by their setwise product 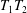 $T_{1}T_{2}$. In this sense we decompose
$T_{1}T_{2}$. In this sense we decompose 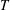 $T$ by merging the subsemigroups
$T$ by merging the subsemigroups 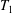 $T_{1}$ and
$T_{1}$ and 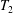 $T_{2}$. More generally, our technique merges semigroup homomorphisms from free semigroups.
$T_{2}$. More generally, our technique merges semigroup homomorphisms from free semigroups.
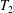
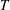
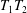
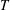
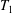
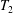
ON FINDING SOLUTIONS TO EXPONENTIAL CONGRUENCES
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 99 / Issue 3 / June 2019
- Published online by Cambridge University Press:
- 27 December 2018, pp. 388-391
- Print publication:
- June 2019
-
- Article
-
- You have access
- Export citation
-
We improve some previously known deterministic algorithms for finding integer solutions
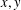 $x,y$ to the exponential equation of the form
$x,y$ to the exponential equation of the form 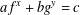 $af^{x}+bg^{y}=c$ over finite fields.
$af^{x}+bg^{y}=c$ over finite fields.
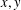
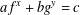
Polynomial Mixing of the Edge-Flip Markov Chain for Unbiased Dyadic Tilings
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 3 / May 2019
- Published online by Cambridge University Press:
- 31 October 2018, pp. 365-387
-
- Article
- Export citation
Dual-Pivot Quicksort: Optimality, Analysis and Zeros of Associated Lattice Paths
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 4 / July 2019
- Published online by Cambridge University Press:
- 14 August 2018, pp. 485-518
-
- Article
- Export citation
A GENERAL POSITION PROBLEM IN GRAPH THEORY
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 98 / Issue 2 / October 2018
- Published online by Cambridge University Press:
- 18 July 2018, pp. 177-187
- Print publication:
- October 2018
-
- Article
-
- You have access
- Export citation
-
The paper introduces a graph theory variation of the general position problem: given a graph
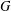 $G$, determine a largest set
$G$, determine a largest set 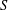 $S$ of vertices of
$S$ of vertices of 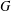 $G$ such that no three vertices of
$G$ such that no three vertices of 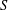 $S$ lie on a common geodesic. Such a set is a max-gp-set of
$S$ lie on a common geodesic. Such a set is a max-gp-set of 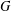 $G$ and its size is the gp-number
$G$ and its size is the gp-number 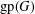 $\text{gp}(G)$ of
$\text{gp}(G)$ of 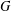 $G$. Upper bounds on
$G$. Upper bounds on 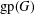 $\text{gp}(G)$ in terms of different isometric covers are given and used to determine the gp-number of several classes of graphs. Connections between general position sets and packings are investigated and used to give lower bounds on the gp-number. It is also proved that the general position problem is NP-complete.
$\text{gp}(G)$ in terms of different isometric covers are given and used to determine the gp-number of several classes of graphs. Connections between general position sets and packings are investigated and used to give lower bounds on the gp-number. It is also proved that the general position problem is NP-complete.
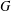
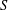
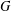
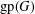
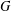
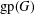
Asymmetric Rényi Problem
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 4 / July 2019
- Published online by Cambridge University Press:
- 27 June 2018, pp. 542-573
-
- Article
- Export citation
-
In 1960 Rényi, in his Michigan State University lectures, asked for the number of random queries necessary to recover a hidden bijective labelling of n distinct objects. In each query one selects a random subset of labels and asks, which objects have these labels? We consider here an asymmetric version of the problem in which in every query an object is chosen with probability p > 1/2 and we ignore ‘inconclusive’ queries. We study the number of queries needed to recover the labelling in its entirety (Hn), before at least one element is recovered (Fn), and to recover a randomly chosen element (Dn). This problem exhibits several remarkable behaviours: Dn converges in probability but not almost surely; Hn and Fn exhibit phase transitions with respect to p in the second term. We prove that for p > 1/2 with high probability we need
queries to recover the entire bijection. This should be compared to its symmetric (p = 1/2) counterpart established by Pittel and Rubin, who proved that in this case one requires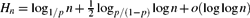 $$H_n=\log_{1/p} n +{\tfrac{1}{2}} \log_{p/(1-p)}\log n +o(\log \log n)$$queries. As a bonus, our analysis implies novel results for random PATRICIA tries, as the problem is probabilistically equivalent to that of the height, fillup level, and typical depth of a PATRICIA trie built from n independent binary sequences generated by a biased(p) memoryless source.
$$H_n=\log_{1/p} n +{\tfrac{1}{2}} \log_{p/(1-p)}\log n +o(\log \log n)$$queries. As a bonus, our analysis implies novel results for random PATRICIA tries, as the problem is probabilistically equivalent to that of the height, fillup level, and typical depth of a PATRICIA trie built from n independent binary sequences generated by a biased(p) memoryless source.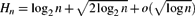 $$ H_n=\log_{2} n +\sqrt{2 \log_{2} n} +o(\sqrt{\log n})$$
$$ H_n=\log_{2} n +\sqrt{2 \log_{2} n} +o(\sqrt{\log n})$$
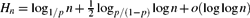
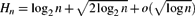
ON SEMIGROUPS WITH PSPACE-COMPLETE SUBPOWER MEMBERSHIP PROBLEM
- Part of
-
- Journal:
- Journal of the Australian Mathematical Society / Volume 106 / Issue 1 / February 2019
- Published online by Cambridge University Press:
- 30 May 2018, pp. 127-142
-
- Article
-
- You have access
- Export citation
-
Fix a finite semigroup
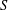 $S$ and let
$S$ and let 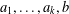 $a_{1},\ldots ,a_{k},b$ be tuples in a direct power
$a_{1},\ldots ,a_{k},b$ be tuples in a direct power 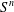 $S^{n}$. The subpower membership problem (SMP) for
$S^{n}$. The subpower membership problem (SMP) for 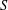 $S$ asks whether
$S$ asks whether 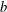 $b$ can be generated by
$b$ can be generated by 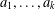 $a_{1},\ldots ,a_{k}$. For combinatorial Rees matrix semigroups we establish a dichotomy result: if the corresponding matrix is of a certain form, then the SMP is in P; otherwise it is NP-complete. For combinatorial Rees matrix semigroups with adjoined identity, we obtain a trichotomy: the SMP is either in P, NP-complete, or PSPACE-complete. This result yields various semigroups with PSPACE-complete SMP including the six-element Brandt monoid, the full transformation semigroup on three or more letters, and semigroups of all
$a_{1},\ldots ,a_{k}$. For combinatorial Rees matrix semigroups we establish a dichotomy result: if the corresponding matrix is of a certain form, then the SMP is in P; otherwise it is NP-complete. For combinatorial Rees matrix semigroups with adjoined identity, we obtain a trichotomy: the SMP is either in P, NP-complete, or PSPACE-complete. This result yields various semigroups with PSPACE-complete SMP including the six-element Brandt monoid, the full transformation semigroup on three or more letters, and semigroups of all  $n$ by
$n$ by  $n$ matrices over a field for
$n$ matrices over a field for 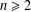 $n\geq 2$.
$n\geq 2$.
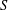
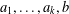
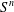
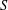
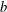
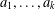


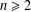
COMPLEXITY OF SHORT GENERATING FUNCTIONS
- Part of
-
- Journal:
- Forum of Mathematics, Sigma / Volume 6 / 2018
- Published online by Cambridge University Press:
- 14 February 2018, e1
-
- Article
-
- You have access
- Open access
- Export citation
-
We give complexity analysis for the class of short generating functions. Assuming
#P 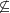 $\not \subseteq$
$\not \subseteq$ FP/poly , we show that this class is not closed under taking many intersections, unions or projections of generating functions, in the sense that these operations can increase the bit length of coefficients of generating functions by a super-polynomial factor. We also prove that truncated theta functions are hard for this class.
A Simple SVD Algorithm for Finding Hidden Partitions
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 27 / Issue 1 / January 2018
- Published online by Cambridge University Press:
- 09 October 2017, pp. 124-140
-
- Article
- Export citation
EXPONENTIAL IMPROVEMENT IN PRECISION FOR SIMULATING SPARSE HAMILTONIANS
- Part of
-
- Journal:
- Forum of Mathematics, Sigma / Volume 5 / 2017
- Published online by Cambridge University Press:
- 02 March 2017, e8
-
- Article
-
- You have access
- Open access
- Export citation
-
We provide a quantum algorithm for simulating the dynamics of sparse Hamiltonians with complexity sublogarithmic in the inverse error, an exponential improvement over previous methods. Specifically, we show that a
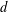 $d$ -sparse Hamiltonian
$d$ -sparse Hamiltonian 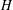 $H$ acting on
$H$ acting on  $n$ qubits can be simulated for time
$n$ qubits can be simulated for time  $t$ with precision
$t$ with precision  $\unicode[STIX]{x1D716}$ using
$\unicode[STIX]{x1D716}$ using 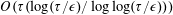 $O(\unicode[STIX]{x1D70F}(\log (\unicode[STIX]{x1D70F}/\unicode[STIX]{x1D716})/\log \log (\unicode[STIX]{x1D70F}/\unicode[STIX]{x1D716})))$ queries and
$O(\unicode[STIX]{x1D70F}(\log (\unicode[STIX]{x1D70F}/\unicode[STIX]{x1D716})/\log \log (\unicode[STIX]{x1D70F}/\unicode[STIX]{x1D716})))$ queries and 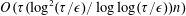 $O(\unicode[STIX]{x1D70F}(\log ^{2}(\unicode[STIX]{x1D70F}/\unicode[STIX]{x1D716})/\log \log (\unicode[STIX]{x1D70F}/\unicode[STIX]{x1D716}))n)$ additional 2-qubit gates, where
$O(\unicode[STIX]{x1D70F}(\log ^{2}(\unicode[STIX]{x1D70F}/\unicode[STIX]{x1D716})/\log \log (\unicode[STIX]{x1D70F}/\unicode[STIX]{x1D716}))n)$ additional 2-qubit gates, where 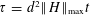 $\unicode[STIX]{x1D70F}=d^{2}\Vert H\Vert _{\max }t$ . Unlike previous approaches based on product formulas, the query complexity is independent of the number of qubits acted on, and for time-varying Hamiltonians, the gate complexity is logarithmic in the norm of the derivative of the Hamiltonian. Our algorithm is based on a significantly improved simulation of the continuous- and fractional-query models using discrete quantum queries, showing that the former models are not much more powerful than the discrete model even for very small error. We also simplify the analysis of this conversion, avoiding the need for a complex fault-correction procedure. Our simplification relies on a new form of ‘oblivious amplitude amplification’ that can be applied even though the reflection about the input state is unavailable. Finally, we prove new lower bounds showing that our algorithms are optimal as a function of the error.
$\unicode[STIX]{x1D70F}=d^{2}\Vert H\Vert _{\max }t$ . Unlike previous approaches based on product formulas, the query complexity is independent of the number of qubits acted on, and for time-varying Hamiltonians, the gate complexity is logarithmic in the norm of the derivative of the Hamiltonian. Our algorithm is based on a significantly improved simulation of the continuous- and fractional-query models using discrete quantum queries, showing that the former models are not much more powerful than the discrete model even for very small error. We also simplify the analysis of this conversion, avoiding the need for a complex fault-correction procedure. Our simplification relies on a new form of ‘oblivious amplitude amplification’ that can be applied even though the reflection about the input state is unavailable. Finally, we prove new lower bounds showing that our algorithms are optimal as a function of the error.
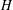



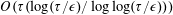
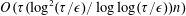
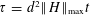
Bit flipping and time to recover
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 53 / Issue 3 / September 2016
- Published online by Cambridge University Press:
- 24 October 2016, pp. 650-666
- Print publication:
- September 2016
-
- Article
- Export citation
Reduced memory meet-in-the-middle attackagainst the NTRU private key
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 19 / Issue A / 2016
- Published online by Cambridge University Press:
- 26 August 2016, pp. 43-57
-
- Article
-
- You have access
- Export citation
-
NTRU is a public-key cryptosystem introduced at ANTS-III. The two most used techniques in attacking the NTRU private key are meet-in-the-middle attacks and lattice-basis reduction attacks. Howgrave-Graham combined both techniques in 2007 and pointed out that the largest obstacle to attacks is the memory capacity that is required for the meet-in-the-middle phase. In the present paper an algorithm is presented that applies low-memory techniques to find ‘golden’ collisions to Odlyzko’s meet-in-the-middle attack against the NTRU private key. Several aspects of NTRU secret keys and the algorithm are analysed. The running time of the algorithm with a maximum storage capacity of
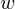 $w$ is estimated and experimentally verified. Experiments indicate that decreasing the storage capacity
$w$ is estimated and experimentally verified. Experiments indicate that decreasing the storage capacity 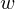 $w$ by a factor
$w$ by a factor 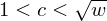 $1<c<\sqrt{w}$ increases the running time by a factor
$1<c<\sqrt{w}$ increases the running time by a factor 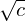 $\sqrt{c}$ .
$\sqrt{c}$ .