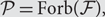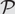Refine listing
Actions for selected content:
130 results in 68Qxx
CONTRIBUTIONS TO THE THEORY OF F-AUTOMATIC SETS
- Part of
-
- Journal:
- The Journal of Symbolic Logic / Volume 87 / Issue 1 / March 2022
- Published online by Cambridge University Press:
- 08 June 2021, pp. 127-158
- Print publication:
- March 2022
-
- Article
- Export citation
-
Fix an abelian group
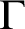 $\Gamma $ and an injective endomorphism
$\Gamma $ and an injective endomorphism 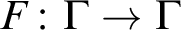 $F\colon \Gamma \to \Gamma $. Improving on the results of [2], new characterizations are here obtained for the existence of spanning sets, F-automaticity, and F-sparsity. The model theoretic status of these sets is also investigated, culminating with a combinatorial description of the F-sparse sets that are stable in
$F\colon \Gamma \to \Gamma $. Improving on the results of [2], new characterizations are here obtained for the existence of spanning sets, F-automaticity, and F-sparsity. The model theoretic status of these sets is also investigated, culminating with a combinatorial description of the F-sparse sets that are stable in 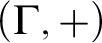 $(\Gamma ,+)$, and a proof that the expansion of
$(\Gamma ,+)$, and a proof that the expansion of 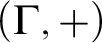 $(\Gamma ,+)$ by any F-sparse set is NIP. These methods are also used to show for prime
$(\Gamma ,+)$ by any F-sparse set is NIP. These methods are also used to show for prime 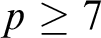 $p\ge 7$ that the expansion of
$p\ge 7$ that the expansion of 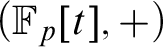 $(\mathbb {F}_p[t],+)$ by multiplication restricted to
$(\mathbb {F}_p[t],+)$ by multiplication restricted to 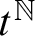 $t^{\mathbb {N}}$ is NIP.
$t^{\mathbb {N}}$ is NIP.
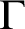
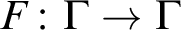
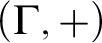
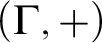
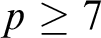
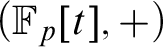
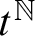
The power of two choices for random walks
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 31 / Issue 1 / January 2022
- Published online by Cambridge University Press:
- 28 May 2021, pp. 73-100
-
- Article
-
- You have access
- Open access
- Export citation
-
We apply the power-of-two-choices paradigm to a random walk on a graph: rather than moving to a uniform random neighbour at each step, a controller is allowed to choose from two independent uniform random neighbours. We prove that this allows the controller to significantly accelerate the hitting and cover times in several natural graph classes. In particular, we show that the cover time becomes linear in the number n of vertices on discrete tori and bounded degree trees, of order
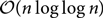 $${\mathcal O}(n\log \log n)$$ on bounded degree expanders, and of order
$${\mathcal O}(n\log \log n)$$ on bounded degree expanders, and of order 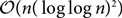 $${\mathcal O}(n{(\log \log n)^2})$$ on the Erdős–Rényi random graph in a certain sparsely connected regime. We also consider the algorithmic question of computing an optimal strategy and prove a dichotomy in efficiency between computing strategies for hitting and cover times.
$${\mathcal O}(n{(\log \log n)^2})$$ on the Erdős–Rényi random graph in a certain sparsely connected regime. We also consider the algorithmic question of computing an optimal strategy and prove a dichotomy in efficiency between computing strategies for hitting and cover times.
Most permutations power to a cycle of small prime length
- Part of
-
- Journal:
- Proceedings of the Edinburgh Mathematical Society / Volume 64 / Issue 2 / May 2021
- Published online by Cambridge University Press:
- 24 May 2021, pp. 234-246
-
- Article
- Export citation
-
We prove that most permutations of degree $n$
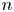 have some power which is a cycle of prime length approximately $\log n$
have some power which is a cycle of prime length approximately $\log n$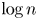 . Explicitly, we show that for $n$
. Explicitly, we show that for $n$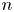 sufficiently large, the proportion of such elements is at least $1-5/\log \log n$
sufficiently large, the proportion of such elements is at least $1-5/\log \log n$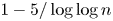 with the prime between $\log n$
with the prime between $\log n$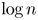 and $(\log n)^{\log \log n}$
and $(\log n)^{\log \log n}$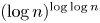 . The proportion of even permutations with this property is at least $1-7/\log \log n$
. The proportion of even permutations with this property is at least $1-7/\log \log n$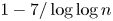 .
.
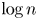
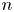
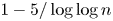
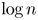
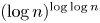
BEING CAYLEY AUTOMATIC IS CLOSED UNDER TAKING WREATH PRODUCT WITH VIRTUALLY CYCLIC GROUPS
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 104 / Issue 3 / December 2021
- Published online by Cambridge University Press:
- 13 April 2021, pp. 464-474
- Print publication:
- December 2021
-
- Article
- Export citation
Polynomial-time approximation algorithms for the antiferromagnetic Ising model on line graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 6 / November 2021
- Published online by Cambridge University Press:
- 12 April 2021, pp. 905-921
-
- Article
- Export citation
BISIMULATIONS FOR KNOWING HOW LOGICS
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 15 / Issue 2 / June 2022
- Published online by Cambridge University Press:
- 22 March 2021, pp. 450-486
- Print publication:
- June 2022
-
- Article
- Export citation
Computable Følner monotilings and a theorem of Brudno
- Part of
-
- Journal:
- Ergodic Theory and Dynamical Systems / Volume 41 / Issue 11 / November 2021
- Published online by Cambridge University Press:
- 13 November 2020, pp. 3389-3416
- Print publication:
- November 2021
-
- Article
- Export citation
-
A theorem of Brudno says that the Kolmogorov–Sinai entropy of an ergodic subshift over
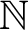 $\mathbb {N}$ equals the asymptotic Kolmogorov complexity of almost every word in the subshift. The purpose of this paper is to extend this result to subshifts over computable groups that admit computable regular symmetric Følner monotilings, which we introduce in this work. For every
$\mathbb {N}$ equals the asymptotic Kolmogorov complexity of almost every word in the subshift. The purpose of this paper is to extend this result to subshifts over computable groups that admit computable regular symmetric Følner monotilings, which we introduce in this work. For every 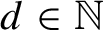 $d \in \mathbb {N}$, the groups
$d \in \mathbb {N}$, the groups 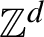 $\mathbb {Z}^d$ and
$\mathbb {Z}^d$ and 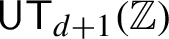 $\mathsf{UT}_{d+1}(\mathbb {Z})$ admit computable regular symmetric Følner monotilings for which the required computing algorithms are provided.
$\mathsf{UT}_{d+1}(\mathbb {Z})$ admit computable regular symmetric Følner monotilings for which the required computing algorithms are provided.
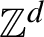
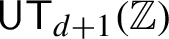
Tail bounds on hitting times of randomized search heuristics using variable drift analysis
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 4 / July 2021
- Published online by Cambridge University Press:
- 05 November 2020, pp. 550-569
-
- Article
- Export citation
INFINITE STRINGS AND THEIR LARGE SCALE PROPERTIES
- Part of
-
- Journal:
- The Journal of Symbolic Logic / Volume 87 / Issue 2 / June 2022
- Published online by Cambridge University Press:
- 30 October 2020, pp. 585-625
- Print publication:
- June 2022
-
- Article
- Export citation
-
The aim of this paper is to shed light on our understanding of large scale properties of infinite strings. We say that one string
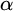 $\alpha $ has weaker large scale geometry than that of
$\alpha $ has weaker large scale geometry than that of 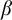 $\beta $ if there is color preserving bi-Lipschitz map from
$\beta $ if there is color preserving bi-Lipschitz map from 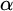 $\alpha $ into
$\alpha $ into 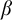 $\beta $ with small distortion. This definition allows us to define a partially ordered set of large scale geometries on the classes of all infinite strings. This partial order compares large scale geometries of infinite strings. As such, it presents an algebraic tool for classification of global patterns. We study properties of this partial order. We prove, for instance, that this partial order has a greatest element and also possess infinite chains and antichains. We also investigate the sets of large scale geometries of strings accepted by finite state machines such as Büchi automata. We provide an algorithm that describes large scale geometries of strings accepted by Büchi automata. This connects the work with the complexity theory. We also prove that the quasi-isometry problem is a
$\beta $ with small distortion. This definition allows us to define a partially ordered set of large scale geometries on the classes of all infinite strings. This partial order compares large scale geometries of infinite strings. As such, it presents an algebraic tool for classification of global patterns. We study properties of this partial order. We prove, for instance, that this partial order has a greatest element and also possess infinite chains and antichains. We also investigate the sets of large scale geometries of strings accepted by finite state machines such as Büchi automata. We provide an algorithm that describes large scale geometries of strings accepted by Büchi automata. This connects the work with the complexity theory. We also prove that the quasi-isometry problem is a 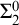 $\Sigma _2^0$-complete set, thus providing a bridge with computability theory. Finally, we build algebraic structures that are invariants of large scale geometries. We invoke asymptotic cones, a key concept in geometric group theory, defined via model-theoretic notion of ultra-product. Partly, we study asymptotic cones of algorithmically random strings, thus connecting the topic with algorithmic randomness.
$\Sigma _2^0$-complete set, thus providing a bridge with computability theory. Finally, we build algebraic structures that are invariants of large scale geometries. We invoke asymptotic cones, a key concept in geometric group theory, defined via model-theoretic notion of ultra-product. Partly, we study asymptotic cones of algorithmically random strings, thus connecting the topic with algorithmic randomness.
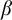
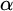
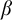
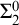
MODEL THEORY AND COMBINATORICS OF BANNED SEQUENCES
- Part of
-
- Journal:
- The Journal of Symbolic Logic / Volume 87 / Issue 1 / March 2022
- Published online by Cambridge University Press:
- 05 October 2020, pp. 1-20
- Print publication:
- March 2022
-
- Article
- Export citation
-
We set up a general context in which one can prove Sauer–Shelah type lemmas. We apply our general results to answer a question of Bhaskar [1] and give a slight improvement to a result of Malliaris and Terry [7]. We also prove a new Sauer–Shelah type lemma in the context of
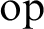 $ \operatorname {\textrm{op}}$-rank, a notion of Guingona and Hill [4].
$ \operatorname {\textrm{op}}$-rank, a notion of Guingona and Hill [4].
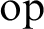
Inessential directed maps and directed homotopy equivalences
- Part of
-
- Journal:
- Proceedings of the Royal Society of Edinburgh. Section A: Mathematics / Volume 151 / Issue 4 / August 2021
- Published online by Cambridge University Press:
- 25 September 2020, pp. 1383-1406
- Print publication:
- August 2021
-
- Article
- Export citation
-
A directed space is a topological space
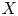 $X$ together with a subspace
$X$ together with a subspace 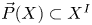 $\vec {P}(X)\subset X^I$ of directed paths on
$\vec {P}(X)\subset X^I$ of directed paths on 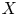 $X$. A symmetry of a directed space should therefore respect both the topology of the underlying space and the topology of the associated spaces
$X$. A symmetry of a directed space should therefore respect both the topology of the underlying space and the topology of the associated spaces 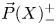 $\vec {P}(X)_-^+$ of directed paths between a source (
$\vec {P}(X)_-^+$ of directed paths between a source ( $-$) and a target (
$-$) and a target (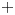 $+$)—up to homotopy. If it is, moreover, homotopic to the identity map—in a directed sense—such a symmetry will be called an inessential d-map, and the paper explores the algebra and topology of inessential d-maps. Comparing two d-spaces
$+$)—up to homotopy. If it is, moreover, homotopic to the identity map—in a directed sense—such a symmetry will be called an inessential d-map, and the paper explores the algebra and topology of inessential d-maps. Comparing two d-spaces 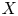 $X$ and
$X$ and 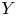 $Y$ ‘up to symmetry’ yields the notion of a directed homotopy equivalence between them. Under appropriate conditions, all directed homotopy equivalences are shown to satisfy a 2-out-of-3 property. Our notion of directed homotopy equivalence does not agree completely with the one defined in Goubault (2017, arxiv:1709:05702v2) and Goubault, Farber and Sagnier (2020, J. Appl. Comput. Topol. 4, 11–27); the deviation is motivated by examples. Nevertheless, directed topological complexity, introduced in Goubault, Farber and Sagnier (2020) is shown to be invariant under our notion of directed homotopy equivalence. Finally, we show that directed homotopy equivalences result in isomorphisms on the pair component categories of directed spaces introduced in Goubault, Farber and Sagnier (2020).
$Y$ ‘up to symmetry’ yields the notion of a directed homotopy equivalence between them. Under appropriate conditions, all directed homotopy equivalences are shown to satisfy a 2-out-of-3 property. Our notion of directed homotopy equivalence does not agree completely with the one defined in Goubault (2017, arxiv:1709:05702v2) and Goubault, Farber and Sagnier (2020, J. Appl. Comput. Topol. 4, 11–27); the deviation is motivated by examples. Nevertheless, directed topological complexity, introduced in Goubault, Farber and Sagnier (2020) is shown to be invariant under our notion of directed homotopy equivalence. Finally, we show that directed homotopy equivalences result in isomorphisms on the pair component categories of directed spaces introduced in Goubault, Farber and Sagnier (2020).
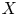
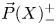

A SCHEMATIC DEFINITION OF QUANTUM POLYNOMIAL TIME COMPUTABILITY
- Part of
-
- Journal:
- The Journal of Symbolic Logic / Volume 85 / Issue 4 / December 2020
- Published online by Cambridge University Press:
- 08 September 2020, pp. 1546-1587
- Print publication:
- December 2020
-
- Article
- Export citation
THE LOGIC OF INFORMATION IN STATE SPACES
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 14 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 25 August 2020, pp. 155-186
- Print publication:
- March 2021
-
- Article
- Export citation
CATEGORICAL COMPLEXITY
- Part of
-
- Journal:
- Forum of Mathematics, Sigma / Volume 8 / 2020
- Published online by Cambridge University Press:
- 30 June 2020, e34
-
- Article
-
- You have access
- Open access
- Export citation
COMPOSITIONALITY, COMPUTABILITY, AND COMPLEXITY
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 14 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 29 June 2020, pp. 551-591
- Print publication:
- September 2021
-
- Article
- Export citation
GÖDEL’S SECOND INCOMPLETENESS THEOREM: HOW IT IS DERIVED AND WHAT IT DELIVERS
- Part of
-
- Journal:
- Bulletin of Symbolic Logic / Volume 26 / Issue 3-4 / December 2020
- Published online by Cambridge University Press:
- 10 June 2020, pp. 241-256
- Print publication:
- December 2020
-
- Article
- Export citation
DECIDING SOME MALTSEV CONDITIONS IN FINITE IDEMPOTENT ALGEBRAS
- Part of
-
- Journal:
- The Journal of Symbolic Logic / Volume 85 / Issue 2 / June 2020
- Published online by Cambridge University Press:
- 16 June 2020, pp. 539-562
- Print publication:
- June 2020
-
- Article
- Export citation
Eventually dendric shift spaces
- Part of
-
- Journal:
- Ergodic Theory and Dynamical Systems / Volume 41 / Issue 7 / July 2021
- Published online by Cambridge University Press:
- 26 May 2020, pp. 2023-2048
- Print publication:
- July 2021
-
- Article
- Export citation
Pointer chasing via triangular discrimination
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 4 / July 2020
- Published online by Cambridge University Press:
- 15 May 2020, pp. 485-494
-
- Article
-
- You have access
- Open access
- Export citation
-
We prove an essentially sharp
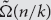 $\tilde \Omega (n/k)$ lower bound on the k-round distributional complexity of the k-step pointer chasing problem under the uniform distribution, when Bob speaks first. This is an improvement over Nisan and Wigderson’s
$\tilde \Omega (n/k)$ lower bound on the k-round distributional complexity of the k-step pointer chasing problem under the uniform distribution, when Bob speaks first. This is an improvement over Nisan and Wigderson’s 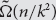 $\tilde \Omega (n/{k^2})$ lower bound, and essentially matches the randomized lower bound proved by Klauck. The proof is information-theoretic, and a key part of it is using asymmetric triangular discrimination instead of total variation distance; this idea may be useful elsewhere.
$\tilde \Omega (n/{k^2})$ lower bound, and essentially matches the randomized lower bound proved by Klauck. The proof is information-theoretic, and a key part of it is using asymmetric triangular discrimination instead of total variation distance; this idea may be useful elsewhere.
Estimating parameters associated with monotone properties
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 4 / July 2020
- Published online by Cambridge University Press:
- 24 March 2020, pp. 616-632
-
- Article
- Export citation
-
There has been substantial interest in estimating the value of a graph parameter, i.e. of a real-valued function defined on the set of finite graphs, by querying a randomly sampled substructure whose size is independent of the size of the input. Graph parameters that may be successfully estimated in this way are said to be testable or estimable, and the sample complexity qz = qz(ε) of an estimable parameter z is the size of a random sample of a graph G required to ensure that the value of z(G) may be estimated within an error of ε with probability at least 2/3. In this paper, for any fixed monotone graph property
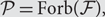 $\mathcal{P}= \text{Forb}\!(\mathcal{F}),$ we study the sample complexity of estimating a bounded graph parameter z that, for an input graph G, counts the number of spanning subgraphs of G that satisfy
$\mathcal{P}= \text{Forb}\!(\mathcal{F}),$ we study the sample complexity of estimating a bounded graph parameter z that, for an input graph G, counts the number of spanning subgraphs of G that satisfy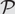 $\mathcal{P}$. To improve upon previous upper bounds on the sample complexity, we show that the vertex set of any graph that satisfies a monotone property $\mathcal{P}$ may be partitioned equitably into a constant number of classes in such a way that the cluster graph induced by the partition is not far from satisfying a natural weighted graph generalization of $\mathcal{P}$. Properties for which this holds are said to be recoverable, and the study of recoverable properties may be of independent interest.
$\mathcal{P}$. To improve upon previous upper bounds on the sample complexity, we show that the vertex set of any graph that satisfies a monotone property $\mathcal{P}$ may be partitioned equitably into a constant number of classes in such a way that the cluster graph induced by the partition is not far from satisfying a natural weighted graph generalization of $\mathcal{P}$. Properties for which this holds are said to be recoverable, and the study of recoverable properties may be of independent interest.