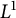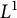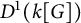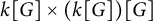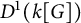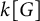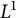Refine listing
Actions for selected content:
130 results in 68Qxx
The promise of neuromorphic edge AI for rural environmental monitoring
- Part of
-
- Journal:
- Environmental Data Science / Volume 3 / 2024
- Published online by Cambridge University Press:
- 02 January 2025, e34
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Sampling from the random cluster model on random regular graphs at all temperatures via Glauber dynamics
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 3 / May 2025
- Published online by Cambridge University Press:
- 09 December 2024, pp. 359-391
-
- Article
- Export citation
-
We consider the performance of Glauber dynamics for the random cluster model with real parameter
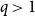 $q\gt 1$ and temperature
$q\gt 1$ and temperature 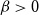 $\beta \gt 0$. Recent work by Helmuth, Jenssen, and Perkins detailed the ordered/disordered transition of the model on random
$\beta \gt 0$. Recent work by Helmuth, Jenssen, and Perkins detailed the ordered/disordered transition of the model on random 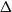 $\Delta$-regular graphs for all sufficiently large
$\Delta$-regular graphs for all sufficiently large 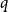 $q$ and obtained an efficient sampling algorithm for all temperatures
$q$ and obtained an efficient sampling algorithm for all temperatures 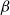 $\beta$ using cluster expansion methods. Despite this major progress, the performance of natural Markov chains, including Glauber dynamics, is not yet well understood on the random regular graph, partly because of the non-local nature of the model (especially at low temperatures) and partly because of severe bottleneck phenomena that emerge in a window around the ordered/disordered transition. Nevertheless, it is widely conjectured that the bottleneck phenomena that impede mixing from worst-case starting configurations can be avoided by initialising the chain more judiciously. Our main result establishes this conjecture for all sufficiently large
$\beta$ using cluster expansion methods. Despite this major progress, the performance of natural Markov chains, including Glauber dynamics, is not yet well understood on the random regular graph, partly because of the non-local nature of the model (especially at low temperatures) and partly because of severe bottleneck phenomena that emerge in a window around the ordered/disordered transition. Nevertheless, it is widely conjectured that the bottleneck phenomena that impede mixing from worst-case starting configurations can be avoided by initialising the chain more judiciously. Our main result establishes this conjecture for all sufficiently large 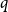 $q$ (with respect to
$q$ (with respect to 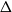 $\Delta$). Specifically, we consider the mixing time of Glauber dynamics initialised from the two extreme configurations, the all-in and all-out, and obtain a pair of fast mixing bounds which cover all temperatures
$\Delta$). Specifically, we consider the mixing time of Glauber dynamics initialised from the two extreme configurations, the all-in and all-out, and obtain a pair of fast mixing bounds which cover all temperatures 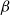 $\beta$, including in particular the bottleneck window. Our result is inspired by the recent approach of Gheissari and Sinclair for the Ising model who obtained a similar flavoured mixing-time bound on the random regular graph for sufficiently low temperatures. To cover all temperatures in the RC model, we refine appropriately the structural results of Helmuth, Jenssen and Perkins about the ordered/disordered transition and show spatial mixing properties ‘within the phase’, which are then related to the evolution of the chain.
$\beta$, including in particular the bottleneck window. Our result is inspired by the recent approach of Gheissari and Sinclair for the Ising model who obtained a similar flavoured mixing-time bound on the random regular graph for sufficiently low temperatures. To cover all temperatures in the RC model, we refine appropriately the structural results of Helmuth, Jenssen and Perkins about the ordered/disordered transition and show spatial mixing properties ‘within the phase’, which are then related to the evolution of the chain.
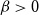
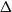
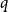
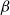
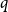
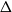
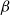
Equality cases of the Alexandrov–Fenchel inequality are not in the polynomial hierarchy
- Part of
-
- Journal:
- Forum of Mathematics, Pi / Volume 12 / 2024
- Published online by Cambridge University Press:
- 11 November 2024, e21
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A PARAMETERIZED HALTING PROBLEM,
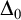 $ \Delta _0$ TRUTH AND THE MRDP THEOREM
$ \Delta _0$ TRUTH AND THE MRDP THEOREM
- Part of
-
- Journal:
- The Journal of Symbolic Logic / Volume 90 / Issue 2 / June 2025
- Published online by Cambridge University Press:
- 30 September 2024, pp. 483-508
- Print publication:
- June 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study the parameterized complexity of the problem to decide whether a given natural number n satisfies a given
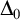 $\Delta _0$-formula
$\Delta _0$-formula 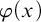 $\varphi (x)$; the parameter is the size of
$\varphi (x)$; the parameter is the size of 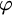 $\varphi $. This parameterization focusses attention on instances where n is large compared to the size of
$\varphi $. This parameterization focusses attention on instances where n is large compared to the size of 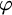 $\varphi $. We show unconditionally that this problem does not belong to the parameterized analogue of
$\varphi $. We show unconditionally that this problem does not belong to the parameterized analogue of 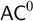 $\mathsf {AC}^0$. From this we derive that certain natural upper bounds on the complexity of our parameterized problem imply certain separations of classical complexity classes. This connection is obtained via an analysis of a parameterized halting problem. Some of these upper bounds follow assuming that
$\mathsf {AC}^0$. From this we derive that certain natural upper bounds on the complexity of our parameterized problem imply certain separations of classical complexity classes. This connection is obtained via an analysis of a parameterized halting problem. Some of these upper bounds follow assuming that 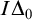 $I\Delta _0$ proves the MRDP theorem in a certain weak sense.
$I\Delta _0$ proves the MRDP theorem in a certain weak sense.
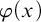
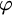
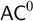
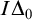
The dutch draw: constructing a universal baseline for binary classification problems
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 2 / June 2025
- Published online by Cambridge University Press:
- 19 September 2024, pp. 475-493
- Print publication:
- June 2025
-
- Article
- Export citation
-
Novel prediction methods should always be compared to a baseline to determine their performance. Without this frame of reference, the performance score of a model is basically meaningless. What does it mean when a model achieves an
 $F_1$ of 0.8 on a test set? A proper baseline is, therefore, required to evaluate the ‘goodness’ of a performance score. Comparing results with the latest state-of-the-art model is usually insightful. However, being state-of-the-art is dynamic, as newer models are continuously developed. Contrary to an advanced model, it is also possible to use a simple dummy classifier. However, the latter model could be beaten too easily, making the comparison less valuable. Furthermore, most existing baselines are stochastic and need to be computed repeatedly to get a reliable expected performance, which could be computationally expensive. We present a universal baseline method for all binary classification models, named the Dutch Draw (DD). This approach weighs simple classifiers and determines the best classifier to use as a baseline. Theoretically, we derive the DD baseline for many commonly used evaluation measures and show that in most situations it reduces to (almost) always predicting either zero or one. Summarizing, the DD baseline is general, as it is applicable to any binary classification problem; simple, as it can be quickly determined without training or parameter tuning; and informative, as insightful conclusions can be drawn from the results. The DD baseline serves two purposes. First, it is a robust and universal baseline that enables comparisons across research papers. Second, it provides a sanity check during the prediction model’s development process. When a model does not outperform the DD baseline, it is a major warning sign.
$F_1$ of 0.8 on a test set? A proper baseline is, therefore, required to evaluate the ‘goodness’ of a performance score. Comparing results with the latest state-of-the-art model is usually insightful. However, being state-of-the-art is dynamic, as newer models are continuously developed. Contrary to an advanced model, it is also possible to use a simple dummy classifier. However, the latter model could be beaten too easily, making the comparison less valuable. Furthermore, most existing baselines are stochastic and need to be computed repeatedly to get a reliable expected performance, which could be computationally expensive. We present a universal baseline method for all binary classification models, named the Dutch Draw (DD). This approach weighs simple classifiers and determines the best classifier to use as a baseline. Theoretically, we derive the DD baseline for many commonly used evaluation measures and show that in most situations it reduces to (almost) always predicting either zero or one. Summarizing, the DD baseline is general, as it is applicable to any binary classification problem; simple, as it can be quickly determined without training or parameter tuning; and informative, as insightful conclusions can be drawn from the results. The DD baseline serves two purposes. First, it is a robust and universal baseline that enables comparisons across research papers. Second, it provides a sanity check during the prediction model’s development process. When a model does not outperform the DD baseline, it is a major warning sign.

Exact recovery of community detection in k-community Gaussian mixture models
- Part of
-
- Journal:
- European Journal of Applied Mathematics / Volume 36 / Issue 3 / June 2025
- Published online by Cambridge University Press:
- 18 September 2024, pp. 491-523
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study the community detection problem on a Gaussian mixture model, in which vertices are divided into
 $k\geq 2$ distinct communities. The major difference in our model is that the intensities for Gaussian perturbations are different for different entries in the observation matrix, and we do not assume that every community has the same number of vertices. We explicitly find the necessary and sufficient conditions for the exact recovery of the maximum likelihood estimation, which can give a sharp phase transition for the exact recovery even though the Gaussian perturbations are not identically distributed; see Section 7. Applications include the community detection on hypergraphs.
$k\geq 2$ distinct communities. The major difference in our model is that the intensities for Gaussian perturbations are different for different entries in the observation matrix, and we do not assume that every community has the same number of vertices. We explicitly find the necessary and sufficient conditions for the exact recovery of the maximum likelihood estimation, which can give a sharp phase transition for the exact recovery even though the Gaussian perturbations are not identically distributed; see Section 7. Applications include the community detection on hypergraphs.

LIMIT COMPLEXITIES, MINIMAL DESCRIPTIONS, AND n-RANDOMNESS
- Part of
-
- Journal:
- The Journal of Symbolic Logic / Volume 90 / Issue 3 / September 2025
- Published online by Cambridge University Press:
- 05 June 2024, pp. 1261-1276
- Print publication:
- September 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Let K denote prefix-free Kolmogorov complexity, and let
 $K^A$ denote it relative to an oracle A. We show that for any n,
$K^A$ denote it relative to an oracle A. We show that for any n,  $K^{\emptyset ^{(n)}}$ is definable purely in terms of the unrelativized notion K. It was already known that 2-randomness is definable in terms of K (and plain complexity C) as those reals which infinitely often have maximal complexity. We can use our characterization to show that n-randomness is definable purely in terms of K. To do this we extend a certain “limsup” formula from the literature, and apply Symmetry of Information. This extension entails a novel use of semilow sets, and a more precise analysis of the complexity of
$K^{\emptyset ^{(n)}}$ is definable purely in terms of the unrelativized notion K. It was already known that 2-randomness is definable in terms of K (and plain complexity C) as those reals which infinitely often have maximal complexity. We can use our characterization to show that n-randomness is definable purely in terms of K. To do this we extend a certain “limsup” formula from the literature, and apply Symmetry of Information. This extension entails a novel use of semilow sets, and a more precise analysis of the complexity of  $\Delta _2^0$ sets of minimal descriptions.
$\Delta _2^0$ sets of minimal descriptions.



Many problems, different frameworks: classification of problems in computable analysis and algorithmic learning theory
- Part of
-
- Journal:
- Bulletin of Symbolic Logic / Volume 30 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 11 November 2024, pp. 287-288
- Print publication:
- June 2024
-
- Article
-
- You have access
- Export citation
-
In this thesis, we study the complexity of some mathematical problems: in particular, those arising in computable analysis and algorithmic learning theory for algebraic structures. Our study is not limited to these two areas: indeed, in both cases, the results we obtain are tightly connected to ideas and tools coming from different areas of mathematical logic, including for example descriptive set theory and reverse mathematics.
After giving the necessary preliminaries, we first study the uniform computational strength of the Cantor–Bendixson theorem in the Weihrauch lattice. This work falls into the program connecting reverse mathematics and computable analysis via the framework of Weihrauch reducibility. We concentrate on problems related to perfect subsets of Polish spaces, studying the perfect set theorem, the Cantor–Bendixson theorem, and various problems arising from them. As far as we know, this is the first systematic study of problems at the level of
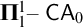 $\mathbf {\Pi }^1_1\mathsf {-CA}_0$ in the Weihrauch lattice. We show that the strength of some of the problems we study depends on the topological properties of the Polish space under consideration, while others have the same strength once the space is rich enough.
$\mathbf {\Pi }^1_1\mathsf {-CA}_0$ in the Weihrauch lattice. We show that the strength of some of the problems we study depends on the topological properties of the Polish space under consideration, while others have the same strength once the space is rich enough.We continue considering problems related to (induced) subgraphs. We provide results on the (effective) Wadge complexity of sets of graphs, that are also used to determine the Weihrauch degree of certain decision problems. The decision problems we consider are defined for a fixed graph G, and they take as input a graph H, answering whether G is an (induced) subgraph of H: we also consider the opposite problem (i.e., answering whether H is an induced subgraph of G). We conclude this part on (induced) subgraphs considering the Weihrauch degree of “search problems.”These problems are defined for a fixed graph G, and they take as input a graph H such that G is an (induced) subgraph H: the output is a copy of G in H. In both cases, we highlight differences and analogies between the subgraph and the induced subgraph relation.
We then move our attention to algorithmic learning theory, and we present the framework we use to study the learnability of families of algebraic structures: here, given a countable family of pairwise nonisomorphic structures
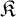 $\mathfrak {K}$, a learner receives larger and larger pieces of an arbitrary copy of a structure in
$\mathfrak {K}$, a learner receives larger and larger pieces of an arbitrary copy of a structure in 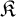 $\mathfrak {K}$ and, at each stage, is required to output a conjecture about the isomorphism type of such a structure. We say that
$\mathfrak {K}$ and, at each stage, is required to output a conjecture about the isomorphism type of such a structure. We say that 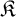 $\mathfrak {K}$ is learnable if there exists a learner which eventually stabilizes to a correct guess. The framework was lacking a method for comparing the complexity of nonlearnable families, and so we propose a solution to this problem using tools coming from invariant descriptive set theory. To do so, we first prove that a family of structures is learnable if and only if its learning domain is continuously reducible to the relation
$\mathfrak {K}$ is learnable if there exists a learner which eventually stabilizes to a correct guess. The framework was lacking a method for comparing the complexity of nonlearnable families, and so we propose a solution to this problem using tools coming from invariant descriptive set theory. To do so, we first prove that a family of structures is learnable if and only if its learning domain is continuously reducible to the relation 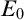 $E_0$ of eventual agreement on infinite binary sequences and then, replacing
$E_0$ of eventual agreement on infinite binary sequences and then, replacing 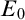 $E_0$ with Borel equivalence relations of higher complexity, we obtain a new hierarchy of learning problems. This leads to the notion of E-learnability, where a family of structures
$E_0$ with Borel equivalence relations of higher complexity, we obtain a new hierarchy of learning problems. This leads to the notion of E-learnability, where a family of structures 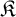 $\mathfrak {K}$ is E-learnable, for a Borel equivalence relation E, if there is a continuous reduction from the isomorphism relation associated with
$\mathfrak {K}$ is E-learnable, for a Borel equivalence relation E, if there is a continuous reduction from the isomorphism relation associated with 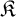 $\mathfrak {K}$ to E. It is then natural to ask how the notion of E-learnability interacts with “classical” learning paradigms.
$\mathfrak {K}$ to E. It is then natural to ask how the notion of E-learnability interacts with “classical” learning paradigms.Finally, we study the number of mind changes that a learner needs to learn a given family, both from a topological and a combinatorial point of view, and we consider how the complexity of a learner (in terms of Turing reducibility) affects the number of mind changes for learning a given family.
Abstract prepared by Vittorio Cipriani.
E-mail: vittorio.cipriani17@gmail.com.
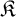
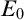
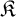
Binary pattern retrieval with Kuramoto-type oscillators via a least orthogonal lift of three patterns
- Part of
-
- Journal:
- European Journal of Applied Mathematics / Volume 36 / Issue 2 / April 2025
- Published online by Cambridge University Press:
- 16 May 2024, pp. 448-463
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ON THE FRAGILITY OF INTERPOLATION
- Part of
-
- Journal:
- The Journal of Symbolic Logic , First View
- Published online by Cambridge University Press:
- 21 March 2024, pp. 1-38
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Invariant sets and nilpotency of endomorphisms of algebraic sofic shifts
- Part of
-
- Journal:
- Ergodic Theory and Dynamical Systems / Volume 44 / Issue 10 / October 2024
- Published online by Cambridge University Press:
- 15 February 2024, pp. 2859-2900
- Print publication:
- October 2024
-
- Article
- Export citation
-
Let G be a group and let V be an algebraic variety over an algebraically closed field K. Let A denote the set of K-points of V. We introduce algebraic sofic subshifts
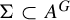 ${\Sigma \subset A^G}$ and study endomorphisms
${\Sigma \subset A^G}$ and study endomorphisms 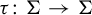 $\tau \colon \Sigma \to \Sigma $. We generalize several results for dynamical invariant sets and nilpotency of
$\tau \colon \Sigma \to \Sigma $. We generalize several results for dynamical invariant sets and nilpotency of 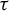 $\tau $ that are well known for finite alphabet cellular automata. Under mild assumptions, we prove that
$\tau $ that are well known for finite alphabet cellular automata. Under mild assumptions, we prove that 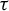 $\tau $ is nilpotent if and only if its limit set, that is, the intersection of the images of its iterates, is a singleton. If moreover G is infinite, finitely generated and
$\tau $ is nilpotent if and only if its limit set, that is, the intersection of the images of its iterates, is a singleton. If moreover G is infinite, finitely generated and 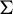 $\Sigma $ is topologically mixing, we show that
$\Sigma $ is topologically mixing, we show that 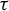 $\tau $ is nilpotent if and only if its limit set consists of periodic configurations and has a finite set of alphabet values.
$\tau $ is nilpotent if and only if its limit set consists of periodic configurations and has a finite set of alphabet values.
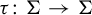
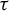
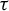
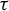
REGAININGLY APPROXIMABLE NUMBERS AND SETS
- Part of
-
- Journal:
- The Journal of Symbolic Logic / Volume 90 / Issue 4 / December 2025
- Published online by Cambridge University Press:
- 22 January 2024, pp. 1664-1694
- Print publication:
- December 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We call an
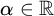 $\alpha \in \mathbb {R}$ regainingly approximable if there exists a computable nondecreasing sequence
$\alpha \in \mathbb {R}$ regainingly approximable if there exists a computable nondecreasing sequence 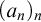 $(a_n)_n$ of rational numbers converging to
$(a_n)_n$ of rational numbers converging to 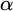 $\alpha $ with
$\alpha $ with 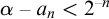 $\alpha - a_n < 2^{-n}$ for infinitely many
$\alpha - a_n < 2^{-n}$ for infinitely many 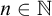 ${n \in \mathbb {N}}$. We also call a set
${n \in \mathbb {N}}$. We also call a set 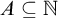 $A\subseteq \mathbb {N}$ regainingly approximable if it is c.e. and the strongly left-computable number
$A\subseteq \mathbb {N}$ regainingly approximable if it is c.e. and the strongly left-computable number 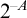 $2^{-A}$ is regainingly approximable. We show that the set of regainingly approximable sets is neither closed under union nor intersection and that every c.e. Turing degree contains such a set. Furthermore, the regainingly approximable numbers lie properly between the computable and the left-computable numbers and are not closed under addition. While regainingly approximable numbers are easily seen to be i.o. K-trivial, we construct such an
$2^{-A}$ is regainingly approximable. We show that the set of regainingly approximable sets is neither closed under union nor intersection and that every c.e. Turing degree contains such a set. Furthermore, the regainingly approximable numbers lie properly between the computable and the left-computable numbers and are not closed under addition. While regainingly approximable numbers are easily seen to be i.o. K-trivial, we construct such an 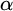 $\alpha $ such that
$\alpha $ such that 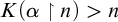 ${K(\alpha \restriction n)>n}$ for infinitely many n. Similarly, there exist regainingly approximable sets whose initial segment complexity infinitely often reaches the maximum possible for c.e. sets. Finally, there is a uniform algorithm splitting regular real numbers into two regainingly approximable numbers that are still regular.
${K(\alpha \restriction n)>n}$ for infinitely many n. Similarly, there exist regainingly approximable sets whose initial segment complexity infinitely often reaches the maximum possible for c.e. sets. Finally, there is a uniform algorithm splitting regular real numbers into two regainingly approximable numbers that are still regular.
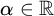
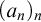
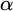
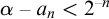
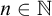
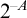
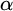
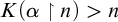
Zeros, chaotic ratios and the computational complexity of approximating the independence polynomial
- Part of
-
- Journal:
- Mathematical Proceedings of the Cambridge Philosophical Society / Volume 176 / Issue 2 / March 2024
- Published online by Cambridge University Press:
- 24 November 2023, pp. 459-494
- Print publication:
- March 2024
-
- Article
- Export citation
ON THE EXISTENCE OF STRONG PROOF COMPLEXITY GENERATORS
- Part of
-
- Journal:
- Bulletin of Symbolic Logic / Volume 30 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 22 November 2023, pp. 20-40
- Print publication:
- March 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Cook and Reckhow [5] pointed out that
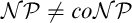 $\mathcal {N}\mathcal {P} \neq co\mathcal {N}\mathcal {P}$ iff there is no propositional proof system that admits polynomial size proofs of all tautologies. The theory of proof complexity generators aims at constructing sets of tautologies hard for strong and possibly for all proof systems. We focus on a conjecture from [16] in foundations of the theory that there is a proof complexity generator hard for all proof systems. This can be equivalently formulated (for p-time generators) without a reference to proof complexity notions as follows:
$\mathcal {N}\mathcal {P} \neq co\mathcal {N}\mathcal {P}$ iff there is no propositional proof system that admits polynomial size proofs of all tautologies. The theory of proof complexity generators aims at constructing sets of tautologies hard for strong and possibly for all proof systems. We focus on a conjecture from [16] in foundations of the theory that there is a proof complexity generator hard for all proof systems. This can be equivalently formulated (for p-time generators) without a reference to proof complexity notions as follows:• There exists a p-time function g stretching each input by one bit such that its range
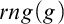 $rng(g)$ intersects all infinite
$rng(g)$ intersects all infinite 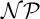 $\mathcal {N}\mathcal {P}$ sets.
$\mathcal {N}\mathcal {P}$ sets.
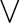 $\bigvee $-hardness, and show that one specific gadget generator is the
$\bigvee $-hardness, and show that one specific gadget generator is the 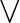 $\bigvee $-hardest (w.r.t. any sufficiently strong proof system). We define the class of feasibly infinite
$\bigvee $-hardest (w.r.t. any sufficiently strong proof system). We define the class of feasibly infinite 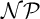 $\mathcal {N}\mathcal {P}$ sets and show, assuming a hypothesis from circuit complexity, that the conjecture holds for all feasibly infinite
$\mathcal {N}\mathcal {P}$ sets and show, assuming a hypothesis from circuit complexity, that the conjecture holds for all feasibly infinite 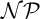 $\mathcal {N}\mathcal {P}$ sets.
$\mathcal {N}\mathcal {P}$ sets.
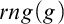
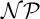
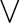
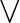
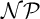
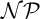
A PROOF COMPLEXITY CONJECTURE AND THE INCOMPLETENESS THEOREM
- Part of
-
- Journal:
- The Journal of Symbolic Logic / Volume 90 / Issue 3 / September 2025
- Published online by Cambridge University Press:
- 19 September 2023, pp. 1206-1210
- Print publication:
- September 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Given a sound first-order p-time theory T capable of formalizing syntax of first-order logic we define a p-time function
 $g_T$ that stretches all inputs by one bit and we use its properties to show that T must be incomplete. We leave it as an open problem whether for some T the range of
$g_T$ that stretches all inputs by one bit and we use its properties to show that T must be incomplete. We leave it as an open problem whether for some T the range of  $g_T$ intersects all infinite
$g_T$ intersects all infinite  ${\mbox {NP}}$ sets (i.e., whether it is a proof complexity generator hard for all proof systems).
${\mbox {NP}}$ sets (i.e., whether it is a proof complexity generator hard for all proof systems).A propositional version of the construction shows that at least one of the following three statements is true:
1. There is no p-optimal propositional proof system (this is equivalent to the non-existence of a time-optimal propositional proof search algorithm).
2.
 $E \not \subseteq P/poly$.
$E \not \subseteq P/poly$.3. There exists function h that stretches all inputs by one bit, is computable in sub-exponential time, and its range
 $Rng(h)$ intersects all infinite
$Rng(h)$ intersects all infinite  ${\text {NP}}$ sets.
${\text {NP}}$ sets.






Phase transition for the generalized two-community stochastic block model
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 31 July 2023, pp. 385-400
- Print publication:
- June 2024
-
- Article
- Export citation
Polarised random
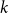 $k$-SAT
$k$-SAT
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 6 / November 2023
- Published online by Cambridge University Press:
- 20 July 2023, pp. 885-899
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In this paper we study a variation of the random
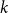 $k$-SAT problem, called polarised random
$k$-SAT problem, called polarised random 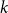 $k$-SAT, which contains both the classical random
$k$-SAT, which contains both the classical random 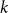 $k$-SAT model and the random version of monotone
$k$-SAT model and the random version of monotone 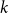 $k$-SAT another well-known NP-complete version of SAT. In this model there is a polarisation parameter
$k$-SAT another well-known NP-complete version of SAT. In this model there is a polarisation parameter 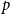 $p$, and in half of the clauses each variable occurs negated with probability
$p$, and in half of the clauses each variable occurs negated with probability 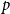 $p$ and pure otherwise, while in the other half the probabilities are interchanged. For
$p$ and pure otherwise, while in the other half the probabilities are interchanged. For 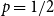 $p=1/2$ we get the classical random
$p=1/2$ we get the classical random 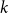 $k$-SAT model, and at the other extreme we have the fully polarised model where
$k$-SAT model, and at the other extreme we have the fully polarised model where 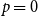 $p=0$, or 1. Here there are only two types of clauses: clauses where all
$p=0$, or 1. Here there are only two types of clauses: clauses where all 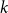 $k$ variables occur pure, and clauses where all
$k$ variables occur pure, and clauses where all 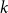 $k$ variables occur negated. That is, for
$k$ variables occur negated. That is, for 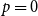 $p=0$, and
$p=0$, and 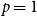 $p=1$, we get an instance of random monotone
$p=1$, we get an instance of random monotone 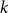 $k$-SAT.
$k$-SAT.We show that the threshold of satisfiability does not decrease as
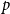 $p$ moves away from
$p$ moves away from 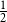 $\frac{1}{2}$ and thus that the satisfiability threshold for polarised random
$\frac{1}{2}$ and thus that the satisfiability threshold for polarised random 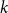 $k$-SAT with
$k$-SAT with 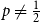 $p\neq \frac{1}{2}$ is an upper bound on the threshold for random
$p\neq \frac{1}{2}$ is an upper bound on the threshold for random 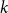 $k$-SAT. Hence the satisfiability threshold for random monotone
$k$-SAT. Hence the satisfiability threshold for random monotone 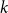 $k$-SAT is at least as large as for random
$k$-SAT is at least as large as for random 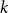 $k$-SAT, and we conjecture that asymptotically, for a fixed
$k$-SAT, and we conjecture that asymptotically, for a fixed 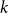 $k$, the two thresholds coincide.
$k$, the two thresholds coincide.
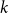
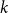
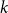
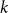
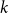
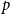
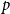
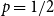
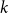
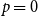
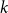
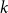
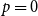
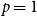
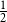
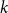
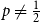
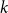
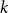
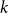
New lower bounds for matrix multiplication and
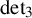 $\operatorname {det}_3$
$\operatorname {det}_3$
- Part of
-
- Journal:
- Forum of Mathematics, Pi / Volume 11 / 2023
- Published online by Cambridge University Press:
- 29 May 2023, e17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Let
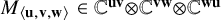 $M_{\langle \mathbf {u},\mathbf {v},\mathbf {w}\rangle }\in \mathbb C^{\mathbf {u}\mathbf {v}}{\mathord { \otimes } } \mathbb C^{\mathbf {v}\mathbf {w}}{\mathord { \otimes } } \mathbb C^{\mathbf {w}\mathbf {u}}$ denote the matrix multiplication tensor (and write
$M_{\langle \mathbf {u},\mathbf {v},\mathbf {w}\rangle }\in \mathbb C^{\mathbf {u}\mathbf {v}}{\mathord { \otimes } } \mathbb C^{\mathbf {v}\mathbf {w}}{\mathord { \otimes } } \mathbb C^{\mathbf {w}\mathbf {u}}$ denote the matrix multiplication tensor (and write 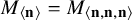 $M_{\langle \mathbf {n} \rangle }=M_{\langle \mathbf {n},\mathbf {n},\mathbf {n}\rangle }$), and let
$M_{\langle \mathbf {n} \rangle }=M_{\langle \mathbf {n},\mathbf {n},\mathbf {n}\rangle }$), and let 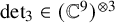 $\operatorname {det}_3\in (\mathbb C^9)^{{\mathord { \otimes } } 3}$ denote the determinant polynomial considered as a tensor. For a tensor T, let
$\operatorname {det}_3\in (\mathbb C^9)^{{\mathord { \otimes } } 3}$ denote the determinant polynomial considered as a tensor. For a tensor T, let 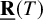 $\underline {\mathbf {R}}(T)$ denote its border rank. We (i) give the first hand-checkable algebraic proof that
$\underline {\mathbf {R}}(T)$ denote its border rank. We (i) give the first hand-checkable algebraic proof that 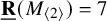 $\underline {\mathbf {R}}(M_{\langle 2\rangle })=7$, (ii) prove
$\underline {\mathbf {R}}(M_{\langle 2\rangle })=7$, (ii) prove 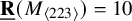 $\underline {\mathbf {R}}(M_{\langle 223\rangle })=10$ and
$\underline {\mathbf {R}}(M_{\langle 223\rangle })=10$ and 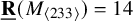 $\underline {\mathbf {R}}(M_{\langle 233\rangle })=14$, where previously the only nontrivial matrix multiplication tensor whose border rank had been determined was
$\underline {\mathbf {R}}(M_{\langle 233\rangle })=14$, where previously the only nontrivial matrix multiplication tensor whose border rank had been determined was 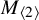 $M_{\langle 2\rangle }$, (iii) prove
$M_{\langle 2\rangle }$, (iii) prove 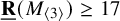 $\underline {\mathbf {R}}( M_{\langle 3\rangle })\geq 17$, (iv) prove
$\underline {\mathbf {R}}( M_{\langle 3\rangle })\geq 17$, (iv) prove 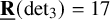 $\underline {\mathbf {R}}(\operatorname {det}_3)=17$, improving the previous lower bound of
$\underline {\mathbf {R}}(\operatorname {det}_3)=17$, improving the previous lower bound of 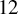 $12$, (v) prove
$12$, (v) prove 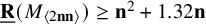 $\underline {\mathbf {R}}(M_{\langle 2\mathbf {n}\mathbf {n}\rangle })\geq \mathbf {n}^2+1.32\mathbf {n}$ for all
$\underline {\mathbf {R}}(M_{\langle 2\mathbf {n}\mathbf {n}\rangle })\geq \mathbf {n}^2+1.32\mathbf {n}$ for all 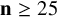 $\mathbf {n}\geq 25$, where previously only
$\mathbf {n}\geq 25$, where previously only 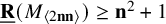 $\underline {\mathbf {R}}(M_{\langle 2\mathbf {n}\mathbf {n}\rangle })\geq \mathbf {n}^2+1$ was known, as well as lower bounds for
$\underline {\mathbf {R}}(M_{\langle 2\mathbf {n}\mathbf {n}\rangle })\geq \mathbf {n}^2+1$ was known, as well as lower bounds for 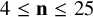 $4\leq \mathbf {n}\leq 25$, and (vi) prove
$4\leq \mathbf {n}\leq 25$, and (vi) prove 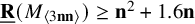 $\underline {\mathbf {R}}(M_{\langle 3\mathbf {n}\mathbf {n}\rangle })\geq \mathbf {n}^2+1.6\mathbf {n}$ for all
$\underline {\mathbf {R}}(M_{\langle 3\mathbf {n}\mathbf {n}\rangle })\geq \mathbf {n}^2+1.6\mathbf {n}$ for all  $\mathbf {n} \ge 18$, where previously only
$\mathbf {n} \ge 18$, where previously only 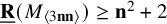 $\underline {\mathbf {R}}(M_{\langle 3\mathbf {n}\mathbf {n}\rangle })\geq \mathbf {n}^2+2$ was known. The last two results are significant for two reasons: (i) they are essentially the first nontrivial lower bounds for tensors in an “unbalanced” ambient space and (ii) they demonstrate that the methods we use (border apolarity) may be applied to sequences of tensors.
$\underline {\mathbf {R}}(M_{\langle 3\mathbf {n}\mathbf {n}\rangle })\geq \mathbf {n}^2+2$ was known. The last two results are significant for two reasons: (i) they are essentially the first nontrivial lower bounds for tensors in an “unbalanced” ambient space and (ii) they demonstrate that the methods we use (border apolarity) may be applied to sequences of tensors.The methods used to obtain the results are new and “nonnatural” in the sense of Razborov and Rudich, in that the results are obtained via an algorithm that cannot be effectively applied to generic tensors. We utilize a new technique, called border apolarity developed by Buczyńska and Buczyński in the general context of toric varieties. We apply this technique to develop an algorithm that, given a tensor T and an integer r, in a finite number of steps, either outputs that there is no border rank r decomposition for T or produces a list of all normalized ideals which could potentially result from a border rank decomposition. The algorithm is effectively implementable when T has a large symmetry group, in which case it outputs potential decompositions in a natural normal form. The algorithm is based on algebraic geometry and representation theory.
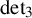
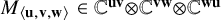
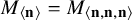
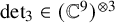
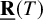
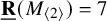
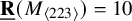
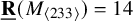
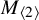
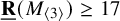
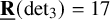
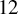
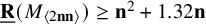
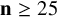
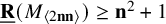
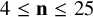
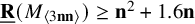

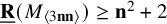
The first-order theory of binary overlap-free words is decidable
- Part of
-
- Journal:
- Canadian Journal of Mathematics / Volume 76 / Issue 4 / August 2024
- Published online by Cambridge University Press:
- 26 May 2023, pp. 1144-1162
- Print publication:
- August 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We show that the first-order logical theory of the binary overlap-free words (and, more generally, the
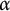 $\alpha $-free words for rational
$\alpha $-free words for rational 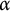 $\alpha $,
$\alpha $, 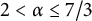 $2 < \alpha \leq 7/3$), is decidable. As a consequence, many results previously obtained about this class through tedious case-based proofs can now be proved “automatically,” using a decision procedure, and new claims can be proved or disproved simply by restating them as logical formulas.
$2 < \alpha \leq 7/3$), is decidable. As a consequence, many results previously obtained about this class through tedious case-based proofs can now be proved “automatically,” using a decision procedure, and new claims can be proved or disproved simply by restating them as logical formulas.
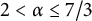
Stable finiteness of twisted group rings and noisy linear cellular automata
- Part of
-
- Journal:
- Canadian Journal of Mathematics / Volume 76 / Issue 4 / August 2024
- Published online by Cambridge University Press:
- 22 May 2023, pp. 1089-1108
- Print publication:
- August 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
For linear nonuniform cellular automata (NUCA) which are local perturbations of linear CA over a group universe G and a finite-dimensional vector space alphabet V over an arbitrary field k, we investigate their Dedekind finiteness property, also known as the direct finiteness property, i.e., left or right invertibility implies invertibility. We say that the group G is
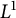 $L^1$-surjunctive, resp. finitely
$L^1$-surjunctive, resp. finitely 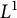 $L^1$-surjunctive, if all such linear NUCA are automatically surjective whenever they are stably injective, resp. when in addition k is finite. In parallel, we introduce the ring
$L^1$-surjunctive, if all such linear NUCA are automatically surjective whenever they are stably injective, resp. when in addition k is finite. In parallel, we introduce the ring 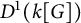 $D^1(k[G])$ which is the Cartesian product
$D^1(k[G])$ which is the Cartesian product 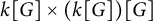 $k[G] \times (k[G])[G]$ as an additive group but the multiplication is twisted in the second component. The ring
$k[G] \times (k[G])[G]$ as an additive group but the multiplication is twisted in the second component. The ring 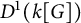 $D^1(k[G])$ contains naturally the group ring
$D^1(k[G])$ contains naturally the group ring 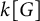 $k[G]$ and we obtain a dynamical characterization of its stable finiteness for every field k in terms of the finite
$k[G]$ and we obtain a dynamical characterization of its stable finiteness for every field k in terms of the finite 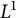 $L^1$-surjunctivity of the group G, which holds, for example, when G is residually finite or initially subamenable. Our results extend known results in the case of CA.
$L^1$-surjunctivity of the group G, which holds, for example, when G is residually finite or initially subamenable. Our results extend known results in the case of CA.