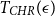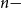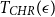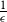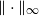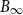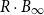Refine listing
Actions for selected content:
130 results in 68Qxx
SOME CONSEQUENCES OF
 ${\mathrm {TD}}$ AND
${\mathrm {TD}}$ AND 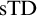 ${\mathrm {sTD}}$
${\mathrm {sTD}}$
- Part of
-
- Journal:
- The Journal of Symbolic Logic / Volume 88 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 15 May 2023, pp. 1573-1589
- Print publication:
- December 2023
-
- Article
- Export citation
-
Strong Turing Determinacy, or
 ${\mathrm {sTD}}$, is the statement that for every set A of reals, if
${\mathrm {sTD}}$, is the statement that for every set A of reals, if 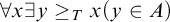 $\forall x\exists y\geq _T x (y\in A)$, then there is a pointed set
$\forall x\exists y\geq _T x (y\in A)$, then there is a pointed set 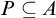 $P\subseteq A$. We prove the following consequences of Turing Determinacy (
$P\subseteq A$. We prove the following consequences of Turing Determinacy ( ${\mathrm {TD}}$) and
${\mathrm {TD}}$) and  ${\mathrm {sTD}}$ over
${\mathrm {sTD}}$ over 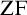 ${\mathrm {ZF}}$—the Zermelo–Fraenkel axiomatic set theory without the Axiom of Choice:
${\mathrm {ZF}}$—the Zermelo–Fraenkel axiomatic set theory without the Axiom of Choice: (1)
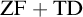 ${\mathrm {ZF}}+{\mathrm {TD}}$ implies
${\mathrm {ZF}}+{\mathrm {TD}}$ implies 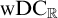 $\mathrm {wDC}_{\mathbb {R}}$—a weaker version of
$\mathrm {wDC}_{\mathbb {R}}$—a weaker version of 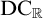 $\mathrm {DC}_{\mathbb {R}}$.
$\mathrm {DC}_{\mathbb {R}}$.(2)
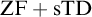 ${\mathrm {ZF}}+{\mathrm {sTD}}$ implies that every set of reals is measurable and has Baire property.
${\mathrm {ZF}}+{\mathrm {sTD}}$ implies that every set of reals is measurable and has Baire property.(3)
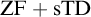 ${\mathrm {ZF}}+{\mathrm {sTD}}$ implies that every uncountable set of reals has a perfect subset.
${\mathrm {ZF}}+{\mathrm {sTD}}$ implies that every uncountable set of reals has a perfect subset.(4)
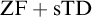 ${\mathrm {ZF}}+{\mathrm {sTD}}$ implies that for every set of reals A and every
${\mathrm {ZF}}+{\mathrm {sTD}}$ implies that for every set of reals A and every 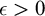 $\epsilon>0$:
$\epsilon>0$:(a) There is a closed set
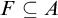 $F\subseteq A$ such that
$F\subseteq A$ such that 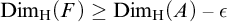 $\mathrm {Dim_H}(F)\geq \mathrm {Dim_H}(A)-\epsilon $, where
$\mathrm {Dim_H}(F)\geq \mathrm {Dim_H}(A)-\epsilon $, where 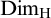 $\mathrm {Dim_H}$ is the Hausdorff dimension.
$\mathrm {Dim_H}$ is the Hausdorff dimension.(b) There is a closed set
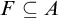 $F\subseteq A$ such that
$F\subseteq A$ such that 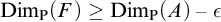 $\mathrm {Dim_P}(F)\geq \mathrm {Dim_P}(A)-\epsilon $, where
$\mathrm {Dim_P}(F)\geq \mathrm {Dim_P}(A)-\epsilon $, where 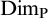 $\mathrm {Dim_P}$ is the packing dimension.
$\mathrm {Dim_P}$ is the packing dimension.

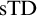

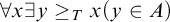
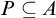


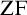
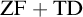
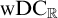
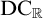
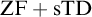
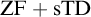
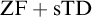
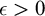
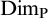
Rigid continuation paths II. structured polynomial systems
- Part of
-
- Journal:
- Forum of Mathematics, Pi / Volume 11 / 2023
- Published online by Cambridge University Press:
- 14 April 2023, e12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This work studies the average complexity of solving structured polynomial systems that are characterised by a low evaluation cost, as opposed to the dense random model previously used. Firstly, we design a continuation algorithm that computes, with high probability, an approximate zero of a polynomial system given only as black-box evaluation program. Secondly, we introduce a universal model of random polynomial systems with prescribed evaluation complexity L. Combining both, we show that we can compute an approximate zero of a random structured polynomial system with n equations of degree at most
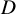 ${D}$ in n variables with only
${D}$ in n variables with only 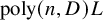 $\operatorname {poly}(n, {D}) L$ operations with high probability. This exceeds the expectations implicit in Smale’s 17th problem.
$\operatorname {poly}(n, {D}) L$ operations with high probability. This exceeds the expectations implicit in Smale’s 17th problem.
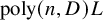
Asymptotic normality for
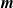 $\boldsymbol{m}$-dependent and constrained
$\boldsymbol{m}$-dependent and constrained 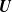 $\boldsymbol{U}$-statistics, with applications to pattern matching in random strings and permutations
$\boldsymbol{U}$-statistics, with applications to pattern matching in random strings and permutations
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 28 March 2023, pp. 841-894
- Print publication:
- September 2023
-
- Article
- Export citation
-
We study (asymmetric)
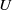 $U$-statistics based on a stationary sequence of
$U$-statistics based on a stationary sequence of 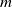 $m$-dependent variables; moreover, we consider constrained
$m$-dependent variables; moreover, we consider constrained 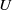 $U$-statistics, where the defining multiple sum only includes terms satisfying some restrictions on the gaps between indices. Results include a law of large numbers and a central limit theorem, together with results on rate of convergence, moment convergence, functional convergence, and a renewal theory version.
$U$-statistics, where the defining multiple sum only includes terms satisfying some restrictions on the gaps between indices. Results include a law of large numbers and a central limit theorem, together with results on rate of convergence, moment convergence, functional convergence, and a renewal theory version.Special attention is paid to degenerate cases where, after the standard normalization, the asymptotic variance vanishes; in these cases non-normal limits occur after a different normalization.
The results are motivated by applications to pattern matching in random strings and permutations. We obtain both new results and new proofs of old results.
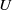
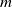
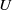
MULTIPLICATION TABLES AND WORD-HYPERBOLICITY IN FREE PRODUCTS OF SEMIGROUPS, MONOIDS AND GROUPS
- Part of
-
- Journal:
- Journal of the Australian Mathematical Society / Volume 115 / Issue 3 / December 2023
- Published online by Cambridge University Press:
- 17 March 2023, pp. 396-430
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This article studies the properties of word-hyperbolic semigroups and monoids, that is, those having context-free multiplication tables with respect to a regular combing, as defined by Duncan and Gilman [‘Word hyperbolic semigroups’, Math. Proc. Cambridge Philos. Soc. 136(3) (2004), 513–524]. In particular, the preservation of word-hyperbolicity under taking free products is considered. Under mild conditions on the semigroups involved, satisfied, for example, by monoids or regular semigroups, we prove that the semigroup free product of two word-hyperbolic semigroups is again word-hyperbolic. Analogously, with a mild condition on the uniqueness of representation for the identity element, satisfied, for example, by groups, we prove that the monoid free product of two word-hyperbolic monoids is word-hyperbolic. The methods are language-theoretically general, and apply equally well to semigroups, monoids or groups with a
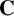 $\mathbf {C}$-multiplication table, where
$\mathbf {C}$-multiplication table, where 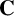 $\mathbf {C}$ is any reversal-closed super-
$\mathbf {C}$ is any reversal-closed super-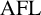 $\operatorname {\mathrm {AFL}}$. In particular, we deduce that the free product of two groups with
$\operatorname {\mathrm {AFL}}$. In particular, we deduce that the free product of two groups with 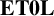 $\mathbf {ET0L}$ with respect to indexed multiplication tables again has an
$\mathbf {ET0L}$ with respect to indexed multiplication tables again has an 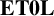 $\mathbf {ET0L}$ with respect to an indexed multiplication table.
$\mathbf {ET0L}$ with respect to an indexed multiplication table.
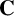
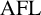
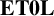
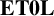
An efficient method for generating a discrete uniform distribution using a biased random source
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 07 March 2023, pp. 1069-1078
- Print publication:
- September 2023
-
- Article
- Export citation
-
We present an efficient algorithm to generate a discrete uniform distribution on a set of p elements using a biased random source for p prime. The algorithm generalizes Von Neumann’s method and improves the computational efficiency of Dijkstra’s method. In addition, the algorithm is extended to generate a discrete uniform distribution on any finite set based on the prime factorization of integers. The average running time of the proposed algorithm is overall sublinear:
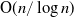 $\operatorname{O}\!(n/\log n)$.
$\operatorname{O}\!(n/\log n)$.
THE ZHOU ORDINAL OF LABELLED MARKOV PROCESSES OVER SEPARABLE SPACES
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 16 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 27 February 2023, pp. 1011-1032
- Print publication:
- December 2023
-
- Article
- Export citation
-
There exist two notions of equivalence of behavior between states of a Labelled Markov Process (LMP): state bisimilarity and event bisimilarity. The first one can be considered as an appropriate generalization to continuous spaces of Larsen and Skou’s probabilistic bisimilarity, whereas the second one is characterized by a natural logic. C. Zhou expressed state bisimilarity as the greatest fixed point of an operator
 $\mathcal {O}$, and thus introduced an ordinal measure of the discrepancy between it and event bisimilarity. We call this ordinal the Zhou ordinal of
$\mathcal {O}$, and thus introduced an ordinal measure of the discrepancy between it and event bisimilarity. We call this ordinal the Zhou ordinal of 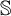 $\mathbb {S}$,
$\mathbb {S}$, 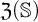 $\mathfrak {Z}(\mathbb {S})$. When
$\mathfrak {Z}(\mathbb {S})$. When 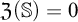 $\mathfrak {Z}(\mathbb {S})=0$,
$\mathfrak {Z}(\mathbb {S})=0$, 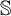 $\mathbb {S}$ satisfies the Hennessy–Milner property. The second author proved the existence of an LMP
$\mathbb {S}$ satisfies the Hennessy–Milner property. The second author proved the existence of an LMP 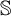 $\mathbb {S}$ with
$\mathbb {S}$ with 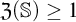 $\mathfrak {Z}(\mathbb {S}) \geq 1$ and Zhou showed that there are LMPs having an infinite Zhou ordinal. In this paper we show that there are LMPs
$\mathfrak {Z}(\mathbb {S}) \geq 1$ and Zhou showed that there are LMPs having an infinite Zhou ordinal. In this paper we show that there are LMPs 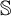 $\mathbb {S}$ over separable metrizable spaces having arbitrary large countable
$\mathbb {S}$ over separable metrizable spaces having arbitrary large countable 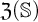 $\mathfrak {Z}(\mathbb {S})$ and that it is consistent with the axioms of
$\mathfrak {Z}(\mathbb {S})$ and that it is consistent with the axioms of 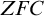 $\mathit {ZFC}$ that there is such a process with an uncountable Zhou ordinal.
$\mathit {ZFC}$ that there is such a process with an uncountable Zhou ordinal.

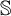
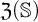
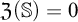
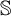
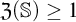
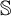
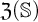
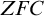
Functional norms, condition numbers and numerical algorithms in algebraic geometry
- Part of
-
- Journal:
- Forum of Mathematics, Sigma / Volume 10 / 2022
- Published online by Cambridge University Press:
- 22 November 2022, e103
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In numerical linear algebra, a well-established practice is to choose a norm that exploits the structure of the problem at hand to optimise accuracy or computational complexity. In numerical polynomial algebra, a single norm (attributed to Weyl) dominates the literature. This article initiates the use of
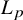 $L_p$ norms for numerical algebraic geometry, with an emphasis on
$L_p$ norms for numerical algebraic geometry, with an emphasis on 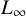 $L_{\infty }$. This classical idea yields strong improvements in the analysis of the number of steps performed by numerous iterative algorithms. In particular, we exhibit three algorithms where, despite the complexity of computing
$L_{\infty }$. This classical idea yields strong improvements in the analysis of the number of steps performed by numerous iterative algorithms. In particular, we exhibit three algorithms where, despite the complexity of computing 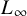 $L_{\infty }$-norm, the use of
$L_{\infty }$-norm, the use of 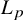 $L_p$-norms substantially reduces computational complexity: a subdivision-based algorithm in real algebraic geometry for computing the homology of semialgebraic sets, a well-known meshing algorithm in computational geometry and the computation of zeros of systems of complex quadratic polynomials (a particular case of Smale’s 17th problem).
$L_p$-norms substantially reduces computational complexity: a subdivision-based algorithm in real algebraic geometry for computing the homology of semialgebraic sets, a well-known meshing algorithm in computational geometry and the computation of zeros of systems of complex quadratic polynomials (a particular case of Smale’s 17th problem).
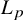
On images of subshifts under embeddings of symbolic varieties
- Part of
-
- Journal:
- Ergodic Theory and Dynamical Systems / Volume 43 / Issue 9 / September 2023
- Published online by Cambridge University Press:
- 01 August 2022, pp. 3131-3149
- Print publication:
- September 2023
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We show that the image of a subshift X under various injective morphisms of symbolic algebraic varieties over monoid universes with algebraic variety alphabets is a subshift of finite type, respectively a sofic subshift, if and only if so is X. Similarly, let G be a countable monoid and let A, B be Artinian modules over a ring. We prove that for every closed subshift submodule
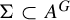 $\Sigma \subset A^G$ and every injective G-equivariant uniformly continuous module homomorphism
$\Sigma \subset A^G$ and every injective G-equivariant uniformly continuous module homomorphism 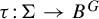 $\tau \colon \! \Sigma \to B^G$, a subshift
$\tau \colon \! \Sigma \to B^G$, a subshift 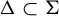 $\Delta \subset \Sigma $ is of finite type, respectively sofic, if and only if so is the image
$\Delta \subset \Sigma $ is of finite type, respectively sofic, if and only if so is the image 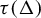 $\tau (\Delta )$. Generalizations for admissible group cellular automata over admissible Artinian group structure alphabets are also obtained.
$\tau (\Delta )$. Generalizations for admissible group cellular automata over admissible Artinian group structure alphabets are also obtained.
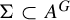
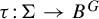
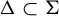
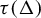
IS CAUSAL REASONING HARDER THAN PROBABILISTIC REASONING?
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 17 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 18 May 2022, pp. 106-131
- Print publication:
- March 2024
-
- Article
- Export citation
-
Many tasks in statistical and causal inference can be construed as problems of entailment in a suitable formal language. We ask whether those problems are more difficult, from a computational perspective, for causal probabilistic languages than for pure probabilistic (or “associational”) languages. Despite several senses in which causal reasoning is indeed more complex—both expressively and inferentially—we show that causal entailment (or satisfiability) problems can be systematically and robustly reduced to purely probabilistic problems. Thus there is no jump in computational complexity. Along the way we answer several open problems concerning the complexity of well-known probability logics, in particular demonstrating the
 ${\exists \mathbb {R}}$-completeness of a polynomial probability calculus, as well as a seemingly much simpler system, the logic of comparative conditional probability.
${\exists \mathbb {R}}$-completeness of a polynomial probability calculus, as well as a seemingly much simpler system, the logic of comparative conditional probability.

SOLENOIDAL MAPS, AUTOMATIC SEQUENCES, VAN DER PUT SERIES, AND MEALY AUTOMATA
- Part of
-
- Journal:
- Journal of the Australian Mathematical Society / Volume 114 / Issue 1 / February 2023
- Published online by Cambridge University Press:
- 06 April 2022, pp. 78-109
-
- Article
- Export citation
-
The ring
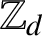 $\mathbb Z_{d}$ of d-adic integers has a natural interpretation as the boundary of a rooted d-ary tree
$\mathbb Z_{d}$ of d-adic integers has a natural interpretation as the boundary of a rooted d-ary tree 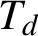 $T_{d}$. Endomorphisms of this tree (that is, solenoidal maps) are in one-to-one correspondence with 1-Lipschitz mappings from
$T_{d}$. Endomorphisms of this tree (that is, solenoidal maps) are in one-to-one correspondence with 1-Lipschitz mappings from 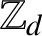 $\mathbb Z_{d}$ to itself. In the case when
$\mathbb Z_{d}$ to itself. In the case when 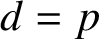 $d=p$ is prime, Anashin [‘Automata finiteness criterion in terms of van der Put series of automata functions’,p-Adic Numbers Ultrametric Anal. Appl. 4(2) (2012), 151–160] showed that
$d=p$ is prime, Anashin [‘Automata finiteness criterion in terms of van der Put series of automata functions’,p-Adic Numbers Ultrametric Anal. Appl. 4(2) (2012), 151–160] showed that 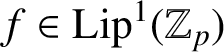 $f\in \mathrm {Lip}^{1}(\mathbb Z_{p})$ is defined by a finite Mealy automaton if and only if the reduced coefficients of its van der Put series constitute a p-automatic sequence over a finite subset of
$f\in \mathrm {Lip}^{1}(\mathbb Z_{p})$ is defined by a finite Mealy automaton if and only if the reduced coefficients of its van der Put series constitute a p-automatic sequence over a finite subset of 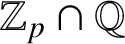 $\mathbb Z_{p}\cap \mathbb Q$. We generalize this result to arbitrary integers
$\mathbb Z_{p}\cap \mathbb Q$. We generalize this result to arbitrary integers 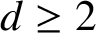 $d\geq 2$ and describe the explicit connection between the Moore automaton producing such a sequence and the Mealy automaton inducing the corresponding endomorphism of a rooted tree. We also produce two algorithms converting one automaton to the other and vice versa. As a demonstration, we apply our algorithms to the Thue–Morse sequence and to one of the generators of the lamplighter group acting on the binary rooted tree.
$d\geq 2$ and describe the explicit connection between the Moore automaton producing such a sequence and the Mealy automaton inducing the corresponding endomorphism of a rooted tree. We also produce two algorithms converting one automaton to the other and vice versa. As a demonstration, we apply our algorithms to the Thue–Morse sequence and to one of the generators of the lamplighter group acting on the binary rooted tree.
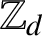
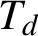
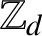
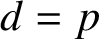
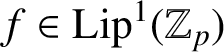
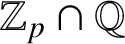
GAPS IN THE THUE–MORSE WORD
- Part of
-
- Journal:
- Journal of the Australian Mathematical Society / Volume 114 / Issue 1 / February 2023
- Published online by Cambridge University Press:
- 25 January 2022, pp. 110-144
-
- Article
- Export citation
-
The Thue–Morse sequence is a prototypical automatic sequence found in diverse areas of mathematics, and in computer science. We study occurrences of factors w within this sequence, or more precisely, the sequence of gaps between consecutive occurrences. This gap sequence is morphic; we prove that it is not automatic as soon as the length of w is at least
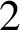 $2$, thereby answering a question by J. Shallit in the affirmative. We give an explicit method to compute the discrepancy of the number of occurrences of the block
$2$, thereby answering a question by J. Shallit in the affirmative. We give an explicit method to compute the discrepancy of the number of occurrences of the block 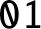 $\mathtt {01}$ in the Thue–Morse sequence. We prove that the sequence of discrepancies is the sequence of output sums of a certain base-
$\mathtt {01}$ in the Thue–Morse sequence. We prove that the sequence of discrepancies is the sequence of output sums of a certain base-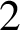 $2$ transducer.
$2$ transducer.
A MINIMAL SET LOW FOR SPEED
- Part of
-
- Journal:
- The Journal of Symbolic Logic / Volume 87 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 03 January 2022, pp. 1693-1728
- Print publication:
- December 2022
-
- Article
- Export citation
-
An oracle A is low-for-speed if it is unable to speed up the computation of a set which is already computable: if a decidable language can be decided in time
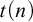 $t(n)$ using A as an oracle, then it can be decided without an oracle in time
$t(n)$ using A as an oracle, then it can be decided without an oracle in time 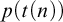 $p(t(n))$ for some polynomial p. The existence of a set which is low-for-speed was first shown by Bayer and Slaman who constructed a non-computable computably enumerable set which is low-for-speed. In this paper we answer a question previously raised by Bienvenu and Downey, who asked whether there is a minimal degree which is low-for-speed. The standard method of constructing a set of minimal degree via forcing is incompatible with making the set low-for-speed; but we are able to use an interesting new combination of forcing and full approximation to construct a set which is both of minimal degree and low-for-speed.
$p(t(n))$ for some polynomial p. The existence of a set which is low-for-speed was first shown by Bayer and Slaman who constructed a non-computable computably enumerable set which is low-for-speed. In this paper we answer a question previously raised by Bienvenu and Downey, who asked whether there is a minimal degree which is low-for-speed. The standard method of constructing a set of minimal degree via forcing is incompatible with making the set low-for-speed; but we are able to use an interesting new combination of forcing and full approximation to construct a set which is both of minimal degree and low-for-speed.
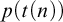
Tuning as convex optimisation: a polynomial tuner for multi-parametric combinatorial samplers
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 31 / Issue 5 / September 2022
- Published online by Cambridge University Press:
- 15 December 2021, pp. 765-811
-
- Article
- Export citation
Topology of random
 $2$-dimensional cubical complexes
$2$-dimensional cubical complexes
- Part of
-
- Journal:
- Forum of Mathematics, Sigma / Volume 9 / 2021
- Published online by Cambridge University Press:
- 29 November 2021, e76
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study a natural model of a random
 $2$-dimensional cubical complex which is a subcomplex of an n-dimensional cube, and where every possible square
$2$-dimensional cubical complex which is a subcomplex of an n-dimensional cube, and where every possible square  $2$-face is included independently with probability p. Our main result exhibits a sharp threshold
$2$-face is included independently with probability p. Our main result exhibits a sharp threshold 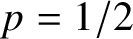 $p=1/2$ for homology vanishing as
$p=1/2$ for homology vanishing as 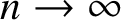 $n \to \infty $. This is a
$n \to \infty $. This is a  $2$-dimensional analogue of the Burtin and Erdoős–Spencer theorems characterising the connectivity threshold for random graphs on the
$2$-dimensional analogue of the Burtin and Erdoős–Spencer theorems characterising the connectivity threshold for random graphs on the  $1$-skeleton of the n-dimensional cube.
$1$-skeleton of the n-dimensional cube.Our main result can also be seen as a cubical counterpart to the Linial–Meshulam theorem for random
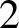 $2$-dimensional simplicial complexes. However, the models exhibit strikingly different behaviours. We show that if
$2$-dimensional simplicial complexes. However, the models exhibit strikingly different behaviours. We show that if 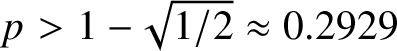 $p> 1 - \sqrt {1/2} \approx 0.2929$, then with high probability the fundamental group is a free group with one generator for every maximal
$p> 1 - \sqrt {1/2} \approx 0.2929$, then with high probability the fundamental group is a free group with one generator for every maximal 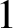 $1$-dimensional face. As a corollary, homology vanishing and simple connectivity have the same threshold, even in the strong ‘hitting time’ sense. This is in contrast with the simplicial case, where the thresholds are far apart. The proof depends on an iterative algorithm for contracting cycles – we show that with high probability, the algorithm rapidly and dramatically simplifies the fundamental group, converging after only a few steps.
$1$-dimensional face. As a corollary, homology vanishing and simple connectivity have the same threshold, even in the strong ‘hitting time’ sense. This is in contrast with the simplicial case, where the thresholds are far apart. The proof depends on an iterative algorithm for contracting cycles – we show that with high probability, the algorithm rapidly and dramatically simplifies the fundamental group, converging after only a few steps.
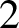
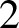
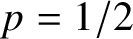
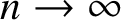
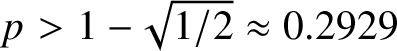
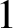
NEW RELATIONS AND SEPARATIONS OF CONJECTURES ABOUT INCOMPLETENESS IN THE FINITE DOMAIN
- Part of
-
- Journal:
- The Journal of Symbolic Logic / Volume 87 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 22 November 2021, pp. 912-937
- Print publication:
- September 2022
-
- Article
- Export citation
-
In [20] Krajíček and Pudlák discovered connections between problems in computational complexity and the lengths of first-order proofs of finite consistency statements. Later Pudlák [25] studied more statements that connect provability with computational complexity and conjectured that they are true. All these conjectures are at least as strong as
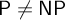 $\mathsf {P}\neq \mathsf {NP}$ [23–25].One of the problems concerning these conjectures is to find out how tightly they are connected with statements about computational complexity classes. Results of this kind had been proved in [20, 22].In this paper, we generalize and strengthen these results. Another question that we address concerns the dependence between these conjectures. We construct two oracles that enable us to answer questions about relativized separations asked in [19, 25] (i.e., for the pairs of conjectures mentioned in the questions, we construct oracles such that one conjecture from the pair is true in the relativized world and the other is false and vice versa). We also show several new connections between the studied conjectures. In particular, we show that the relation between the finite reflection principle and proof systems for existentially quantified Boolean formulas is similar to the one for finite consistency statements and proof systems for non-quantified propositional tautologies.
$\mathsf {P}\neq \mathsf {NP}$ [23–25].One of the problems concerning these conjectures is to find out how tightly they are connected with statements about computational complexity classes. Results of this kind had been proved in [20, 22].In this paper, we generalize and strengthen these results. Another question that we address concerns the dependence between these conjectures. We construct two oracles that enable us to answer questions about relativized separations asked in [19, 25] (i.e., for the pairs of conjectures mentioned in the questions, we construct oracles such that one conjecture from the pair is true in the relativized world and the other is false and vice versa). We also show several new connections between the studied conjectures. In particular, we show that the relation between the finite reflection principle and proof systems for existentially quantified Boolean formulas is similar to the one for finite consistency statements and proof systems for non-quantified propositional tautologies.
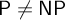
DEGREES OF RANDOMIZED COMPUTABILITY
- Part of
-
- Journal:
- Bulletin of Symbolic Logic / Volume 28 / Issue 1 / March 2022
- Published online by Cambridge University Press:
- 27 September 2021, pp. 27-70
- Print publication:
- March 2022
-
- Article
- Export citation
-
In this survey we discuss work of Levin and V’yugin on collections of sequences that are non-negligible in the sense that they can be computed by a probabilistic algorithm with positive probability. More precisely, Levin and V’yugin introduced an ordering on collections of sequences that are closed under Turing equivalence. Roughly speaking, given two such collections
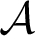 $\mathcal {A}$ and
$\mathcal {A}$ and 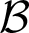 $\mathcal {B}$,
$\mathcal {B}$, 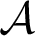 $\mathcal {A}$ is below
$\mathcal {A}$ is below 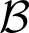 $\mathcal {B}$ in this ordering if
$\mathcal {B}$ in this ordering if 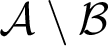 $\mathcal {A}\setminus \mathcal {B}$ is negligible. The degree structure associated with this ordering, the Levin–V’yugin degrees (or
$\mathcal {A}\setminus \mathcal {B}$ is negligible. The degree structure associated with this ordering, the Levin–V’yugin degrees (or 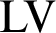 $\mathrm {LV}$-degrees), can be shown to be a Boolean algebra, and in fact a measure algebra. We demonstrate the interactions of this work with recent results in computability theory and algorithmic randomness: First, we recall the definition of the Levin–V’yugin algebra and identify connections between its properties and classical properties from computability theory. In particular, we apply results on the interactions between notions of randomness and Turing reducibility to establish new facts about specific LV-degrees, such as the LV-degree of the collection of 1-generic sequences, that of the collection of sequences of hyperimmune degree, and those collections corresponding to various notions of effective randomness. Next, we provide a detailed explanation of a complex technique developed by V’yugin that allows the construction of semi-measures into which computability-theoretic properties can be encoded. We provide two examples of the use of this technique by explicating a result of V’yugin’s about the LV-degree of the collection of Martin-Löf random sequences and extending the result to the LV-degree of the collection of sequences of DNC degree.
$\mathrm {LV}$-degrees), can be shown to be a Boolean algebra, and in fact a measure algebra. We demonstrate the interactions of this work with recent results in computability theory and algorithmic randomness: First, we recall the definition of the Levin–V’yugin algebra and identify connections between its properties and classical properties from computability theory. In particular, we apply results on the interactions between notions of randomness and Turing reducibility to establish new facts about specific LV-degrees, such as the LV-degree of the collection of 1-generic sequences, that of the collection of sequences of hyperimmune degree, and those collections corresponding to various notions of effective randomness. Next, we provide a detailed explanation of a complex technique developed by V’yugin that allows the construction of semi-measures into which computability-theoretic properties can be encoded. We provide two examples of the use of this technique by explicating a result of V’yugin’s about the LV-degree of the collection of Martin-Löf random sequences and extending the result to the LV-degree of the collection of sequences of DNC degree.
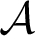
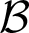
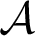
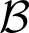
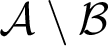
INFORMATION IN PROPOSITIONAL PROOFS AND ALGORITHMIC PROOF SEARCH
- Part of
-
- Journal:
- The Journal of Symbolic Logic / Volume 87 / Issue 2 / June 2022
- Published online by Cambridge University Press:
- 27 September 2021, pp. 852-869
- Print publication:
- June 2022
-
- Article
- Export citation
-
We study from the proof complexity perspective the (informal) proof search problem (cf. [17, Sections 1.5 and 21.5]):
• Is there an optimal way to search for propositional proofs?
We note that, as a consequence of Levin’s universal search, for any fixed proof system there exists a time-optimal proof search algorithm. Using classical proof complexity results about reflection principles we prove that a time-optimal proof search algorithm exists without restricting proof systems iff a p-optimal proof system exists.
To characterize precisely the time proof search algorithms need for individual formulas we introduce a new proof complexity measure based on algorithmic information concepts. In particular, to a proof system P we attach information-efficiency function
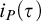 $i_P(\tau )$ assigning to a tautology a natural number, and we show that:
$i_P(\tau )$ assigning to a tautology a natural number, and we show that: •
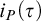 $i_P(\tau )$ characterizes time any P-proof search algorithm has to use on
$i_P(\tau )$ characterizes time any P-proof search algorithm has to use on 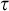 $\tau $,
$\tau $,• for a fixed P there is such an information-optimal algorithm (informally: it finds proofs of minimal information content),
• a proof system is information-efficiency optimal (its information-efficiency function is minimal up to a multiplicative constant) iff it is p-optimal,
• for non-automatizable systems P there are formulas
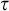 $\tau $ with short proofs but having large information measure
$\tau $ with short proofs but having large information measure 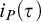 $i_P(\tau )$.
$i_P(\tau )$.
We isolate and motivate the problem to establish unconditional super-logarithmic lower bounds for
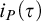 $i_P(\tau )$ where no super-polynomial size lower bounds are known. We also point out connections of the new measure with some topics in proof complexity other than proof search.
$i_P(\tau )$ where no super-polynomial size lower bounds are known. We also point out connections of the new measure with some topics in proof complexity other than proof search.
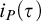
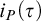
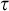
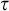
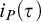
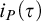
An incompressibility theorem for automatic complexity
- Part of
-
- Journal:
- Forum of Mathematics, Sigma / Volume 9 / 2021
- Published online by Cambridge University Press:
- 10 September 2021, e62
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Shallit and Wang showed that the automatic complexity
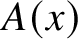 $A(x)$ satisfies
$A(x)$ satisfies 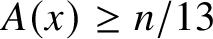 $A(x)\ge n/13$ for almost all
$A(x)\ge n/13$ for almost all 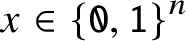 $x\in {\{\mathtt {0},\mathtt {1}\}}^n$. They also stated that Holger Petersen had informed them that the constant
$x\in {\{\mathtt {0},\mathtt {1}\}}^n$. They also stated that Holger Petersen had informed them that the constant 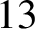 $13$ can be reduced to
$13$ can be reduced to 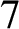 $7$. Here we show that it can be reduced to
$7$. Here we show that it can be reduced to 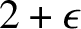 $2+\epsilon $ for any
$2+\epsilon $ for any 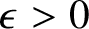 $\epsilon>0$. The result also applies to nondeterministic automatic complexity
$\epsilon>0$. The result also applies to nondeterministic automatic complexity 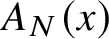 $A_N(x)$. In that setting the result is tight inasmuch as
$A_N(x)$. In that setting the result is tight inasmuch as 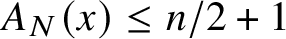 $A_N(x)\le n/2+1$ for all x.
$A_N(x)\le n/2+1$ for all x.
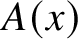
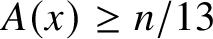
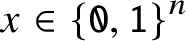
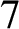
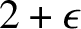
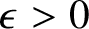
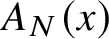
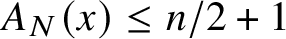
Yaglom limit for stochastic fluid models
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 53 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 08 October 2021, pp. 649-686
- Print publication:
- September 2021
-
- Article
- Export citation
-
In this paper we analyse the limiting conditional distribution (Yaglom limit) for stochastic fluid models (SFMs), a key class of models in the theory of matrix-analytic methods. So far, only transient and stationary analyses of SFMs have been considered in the literature. The limiting conditional distribution gives useful insights into what happens when the process has been evolving for a long time, given that its busy period has not ended yet. We derive expressions for the Yaglom limit in terms of the singularity˜
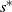 $s^*$ such that the key matrix of the SFM,
$s^*$ such that the key matrix of the SFM, 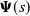 ${\boldsymbol{\Psi}}(s)$, is finite (exists) for all
${\boldsymbol{\Psi}}(s)$, is finite (exists) for all 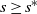 $s\geq s^*$ and infinite for
$s\geq s^*$ and infinite for 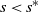 $s<s^*$. We show the uniqueness of the Yaglom limit and illustrate the application of the theory with simple examples.
$s<s^*$. We show the uniqueness of the Yaglom limit and illustrate the application of the theory with simple examples.
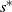
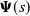
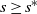
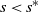
On the mixing time of coordinate Hit-and-Run
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 31 / Issue 2 / March 2022
- Published online by Cambridge University Press:
- 25 August 2021, pp. 320-332
-
- Article
- Export citation
-
We obtain a polynomial upper bound on the mixing time
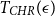 $T_{CHR}(\epsilon)$ of the coordinate Hit-and-Run (CHR) random walk on an
$T_{CHR}(\epsilon)$ of the coordinate Hit-and-Run (CHR) random walk on an 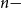 $n-$dimensional convex body, where
$n-$dimensional convex body, where 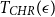 $T_{CHR}(\epsilon)$ is the number of steps needed to reach within
$T_{CHR}(\epsilon)$ is the number of steps needed to reach within  $\epsilon$ of the uniform distribution with respect to the total variation distance, starting from a warm start (i.e., a distribution which has a density with respect to the uniform distribution on the convex body that is bounded above by a constant). Our upper bound is polynomial in n, R and
$\epsilon$ of the uniform distribution with respect to the total variation distance, starting from a warm start (i.e., a distribution which has a density with respect to the uniform distribution on the convex body that is bounded above by a constant). Our upper bound is polynomial in n, R and 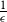 $\frac{1}{\epsilon}$, where we assume that the convex body contains the unit
$\frac{1}{\epsilon}$, where we assume that the convex body contains the unit 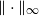 $\Vert\cdot\Vert_\infty$-unit ball
$\Vert\cdot\Vert_\infty$-unit ball 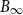 $B_\infty$ and is contained in its R-dilation
$B_\infty$ and is contained in its R-dilation 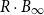 $R\cdot B_\infty$. Whether CHR has a polynomial mixing time has been an open question.
$R\cdot B_\infty$. Whether CHR has a polynomial mixing time has been an open question.