Refine listing
Actions for selected content:
84 results in 68Wxx
Perpetuities in Fair Leader Election Algorithms
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 46 / Issue 1 / March 2014
- Published online by Cambridge University Press:
- 22 February 2016, pp. 203-216
- Print publication:
- March 2014
-
- Article
-
- You have access
- Export citation
On the Nearest-Neighbor Algorithm for the Mean-Field Traveling Salesman Problem
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 51 / Issue 1 / March 2014
- Published online by Cambridge University Press:
- 30 January 2018, pp. 106-117
- Print publication:
- March 2014
-
- Article
-
- You have access
- Export citation
Distributional Convergence for the Number of Symbol Comparisons Used by Quickselect
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 45 / Issue 2 / June 2013
- Published online by Cambridge University Press:
- 22 February 2016, pp. 425-450
- Print publication:
- June 2013
-
- Article
-
- You have access
- Export citation
ON A CLASS OF MONOMIAL IDEALS
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 87 / Issue 3 / June 2013
- Published online by Cambridge University Press:
- 28 January 2013, pp. 514-526
- Print publication:
- June 2013
-
- Article
-
- You have access
- Export citation
-
Let
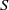 $S$ be a polynomial ring over a field
$S$ be a polynomial ring over a field 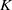 $K$ and let
$K$ and let 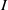 $I$ be a monomial ideal of
$I$ be a monomial ideal of 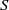 $S$. We say that
$S$. We say that 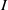 $I$ is MHC (that is,
$I$ is MHC (that is, 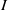 $I$ satisfies the maximal height condition for the associated primes of
$I$ satisfies the maximal height condition for the associated primes of 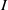 $I$) if there exists a prime ideal
$I$) if there exists a prime ideal 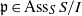 $\mathfrak{p}\in {\mathrm{Ass} }_{S} \hspace{0.167em} S/ I$ for which
$\mathfrak{p}\in {\mathrm{Ass} }_{S} \hspace{0.167em} S/ I$ for which 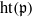 $\mathrm{ht} (\mathfrak{p})$ equals the number of indeterminates that appear in the minimal set of monomials generating
$\mathrm{ht} (\mathfrak{p})$ equals the number of indeterminates that appear in the minimal set of monomials generating 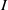 $I$. Let
$I$. Let 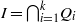 $I= { \mathop{\bigcap }\nolimits}_{i= 1}^{k} {Q}_{i} $ be the irreducible decomposition of
$I= { \mathop{\bigcap }\nolimits}_{i= 1}^{k} {Q}_{i} $ be the irreducible decomposition of 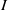 $I$ and let
$I$ and let 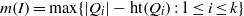 $m(I)= \max \{ \vert Q_{i}\vert - \mathrm{ht} ({Q}_{i} ): 1\leq i\leq k\} $, where
$m(I)= \max \{ \vert Q_{i}\vert - \mathrm{ht} ({Q}_{i} ): 1\leq i\leq k\} $, where 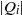 $\vert {Q}_{i} \vert $ denotes the total degree of
$\vert {Q}_{i} \vert $ denotes the total degree of 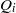 ${Q}_{i} $. Then it can be seen that when
${Q}_{i} $. Then it can be seen that when 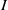 $I$ is primary,
$I$ is primary, 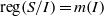 $\mathrm{reg} (S/ I)= m(I)$. In this paper we improve this result and show that whenever
$\mathrm{reg} (S/ I)= m(I)$. In this paper we improve this result and show that whenever 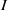 $I$ is MHC, then
$I$ is MHC, then 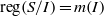 $\mathrm{reg} (S/ I)= m(I)$ provided
$\mathrm{reg} (S/ I)= m(I)$ provided 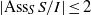 $\vert {\mathrm{Ass} }_{S} \hspace{0.167em} S/ I\vert \leq 2$. We also prove that
$\vert {\mathrm{Ass} }_{S} \hspace{0.167em} S/ I\vert \leq 2$. We also prove that 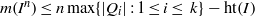 $m({I}^{n} )\leq n\max \{ \vert Q_{i}\vert : 1\leq i\leq ~k\} - \mathrm{ht} (I)$, for all
$m({I}^{n} )\leq n\max \{ \vert Q_{i}\vert : 1\leq i\leq ~k\} - \mathrm{ht} (I)$, for all 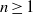 $n\geq 1$. In addition we show that if
$n\geq 1$. In addition we show that if 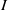 $I$ is MHC and
$I$ is MHC and 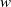 $w$ is an indeterminate which is not in the monomials generating
$w$ is an indeterminate which is not in the monomials generating 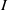 $I$, then
$I$, then 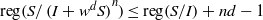 $\mathrm{reg} (S/ \mathop{(I+ {w}^{d} S)}\nolimits ^{n} )\leq \mathrm{reg} (S/ I)+ nd- 1$ for all
$\mathrm{reg} (S/ \mathop{(I+ {w}^{d} S)}\nolimits ^{n} )\leq \mathrm{reg} (S/ I)+ nd- 1$ for all 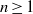 $n\geq 1$ and
$n\geq 1$ and 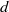 $d$ large enough. Finally, we implement an algorithm for the computation of
$d$ large enough. Finally, we implement an algorithm for the computation of 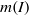 $m(I)$.
$m(I)$.
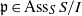
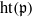
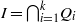
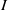
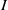
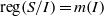
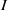
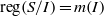
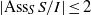
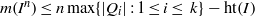
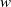
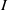
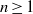
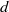
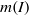
Algebraic boundaries of Hilbert’s SOS cones
- Part of
-
- Journal:
- Compositio Mathematica / Volume 148 / Issue 6 / November 2012
- Published online by Cambridge University Press:
- 15 October 2012, pp. 1717-1735
- Print publication:
- November 2012
-
- Article
-
- You have access
- Export citation
On ε-Optimality of the Pursuit Learning Algorithm
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 49 / Issue 3 / September 2012
- Published online by Cambridge University Press:
- 04 February 2016, pp. 795-805
- Print publication:
- September 2012
-
- Article
-
- You have access
- Export citation
Asymptotics of geometrical navigation on a random set of points in the plane
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 43 / Issue 4 / December 2011
- Published online by Cambridge University Press:
- 01 July 2016, pp. 899-942
- Print publication:
- December 2011
-
- Article
-
- You have access
- Export citation
Numerical-symbolic exact irreducible decomposition of cyclic-12
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 14 / 2011
- Published online by Cambridge University Press:
- 01 August 2011, pp. 155-172
-
- Article
-
- You have access
- Export citation
Asymptotic Properties of a Leader Election Algorithm
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 48 / Issue 2 / June 2011
- Published online by Cambridge University Press:
- 14 July 2016, pp. 569-575
- Print publication:
- June 2011
-
- Article
-
- You have access
- Export citation
A weakly 1-stable distribution for the number of random records and cuttings in split trees
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 43 / Issue 1 / March 2011
- Published online by Cambridge University Press:
- 01 July 2016, pp. 151-177
- Print publication:
- March 2011
-
- Article
-
- You have access
- Export citation
A fluid limit for a cache algorithm with general request processes
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 42 / Issue 3 / September 2010
- Published online by Cambridge University Press:
- 01 July 2016, pp. 816-833
- Print publication:
- September 2010
-
- Article
-
- You have access
- Export citation
Efficient importance sampling in ruin problems for multidimensional regularly varying random walks
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 47 / Issue 2 / June 2010
- Published online by Cambridge University Press:
- 14 July 2016, pp. 301-322
- Print publication:
- June 2010
-
- Article
-
- You have access
- Export citation
Approximate Kernel Clustering
- Part of
-
- Journal:
- Mathematika / Volume 55 / Issue 1-2 / December 2009
- Published online by Cambridge University Press:
- 21 December 2009, pp. 129-165
- Print publication:
- December 2009
-
- Article
- Export citation
-
In the kernel clustering problem we are given a large n × n positive-semidefinite matrix A = (aij) with
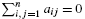 and a small k × k positive-semidefinite matrix B = (bij). The goal is to find a partition S1, …, Sk of {1, … n} which maximizes the quantity
and a small k × k positive-semidefinite matrix B = (bij). The goal is to find a partition S1, …, Sk of {1, … n} which maximizes the quantity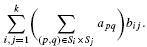
We study the computational complexity of this generic clustering problem which originates in the theory of machine learning. We design a constant factor polynomial time approximation algorithm for this problem, answering a question posed by Song et al. In some cases we manage to compute the sharp approximation threshold for this problem assuming the unique games conjecture (UGC). In particular, when B is the 3 × 3 identity matrix the UGC hardness threshold of this problem is exactly 16π/27. We present and study a geometric conjecture of independent interest which we show would imply that the UGC threshold when B is the k × k identity matrix is (8π/9)(1 – 1/k) for every k ≥ 3.
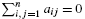 and a small
and a small 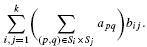
ADVANCES IN CROSS-ENTROPY METHODS
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 80 / Issue 3 / December 2009
- Published online by Cambridge University Press:
- 02 October 2009, pp. 521-522
- Print publication:
- December 2009
-
- Article
-
- You have access
- Export citation
Fixed Precision MCMC Estimation by Median of Products of Averages
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 46 / Issue 2 / June 2009
- Published online by Cambridge University Press:
- 14 July 2016, pp. 309-329
- Print publication:
- June 2009
-
- Article
-
- You have access
- Export citation
-
The standard Markov chain Monte Carlo method of estimating an expected value is to generate a Markov chain which converges to the target distribution and then compute correlated sample averages. In many applications the quantity of interest θ is represented as a product of expected values, θ = µ 1 ⋯ µ k , and a natural estimator is a product of averages. To increase the confidence level, we can compute a median of independent runs. The goal of this paper is to analyze such an estimator
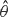 , i.e. an estimator which is a ‘median of products of averages’ (MPA). Sufficient conditions are given for to have fixed relative precision at a given level of confidence, that is, to satisfy
, i.e. an estimator which is a ‘median of products of averages’ (MPA). Sufficient conditions are given for to have fixed relative precision at a given level of confidence, that is, to satisfy 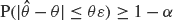 . Our main tool is a new bound on the mean-square error, valid also for nonreversible Markov chains on a finite state space.
. Our main tool is a new bound on the mean-square error, valid also for nonreversible Markov chains on a finite state space.
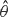 , i.e. an estimator which is a ‘median of products of averages’ (MPA). Sufficient conditions are given for
, i.e. an estimator which is a ‘median of products of averages’ (MPA). Sufficient conditions are given for 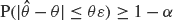 . Our main tool is a new bound on the mean-square error, valid also for nonreversible Markov chains on a finite state space.
. Our main tool is a new bound on the mean-square error, valid also for nonreversible Markov chains on a finite state space.THE DEPRIORITISED APPROACH TO PRIORITISED ALGORITHMS
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 79 / Issue 3 / June 2009
- Published online by Cambridge University Press:
- 14 May 2009, pp. 523-524
- Print publication:
- June 2009
-
- Article
-
- You have access
- Export citation
Expected coalescence time for a nonuniform allocation process
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 40 / Issue 4 / December 2008
- Published online by Cambridge University Press:
- 01 July 2016, pp. 1002-1032
- Print publication:
- December 2008
-
- Article
-
- You have access
- Export citation
State-dependent importance sampling for regularly varying random walks
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 40 / Issue 4 / December 2008
- Published online by Cambridge University Press:
- 01 July 2016, pp. 1104-1128
- Print publication:
- December 2008
-
- Article
-
- You have access
- Export citation
Decentralized search on spheres using small-world Markov chains: expected hitting times and structural properties
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 40 / Issue 4 / December 2008
- Published online by Cambridge University Press:
- 01 July 2016, pp. 966-978
- Print publication:
- December 2008
-
- Article
-
- You have access
- Export citation
Probabilistic Analysis of Unit-Demand Vehicle Routeing Problems
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 44 / Issue 1 / March 2007
- Published online by Cambridge University Press:
- 14 July 2016, pp. 259-278
- Print publication:
- March 2007
-
- Article
-
- You have access
- Export citation
