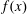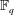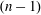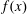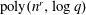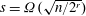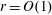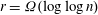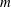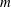Refine listing
Actions for selected content:
84 results in 68Wxx
A spectral method for community detection in moderately sparse degree-corrected stochastic block models
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 49 / Issue 3 / September 2017
- Published online by Cambridge University Press:
- 08 September 2017, pp. 686-721
- Print publication:
- September 2017
-
- Article
- Export citation
THE SHORT RESOLUTION OF A SEMIGROUP ALGEBRA
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 96 / Issue 3 / December 2017
- Published online by Cambridge University Press:
- 29 August 2017, pp. 400-411
- Print publication:
- December 2017
-
- Article
-
- You have access
- Export citation
GPU-Accelerated LOBPCG Method with Inexact Null-Space Filtering for Solving Generalized Eigenvalue Problems in Computational Electromagnetics Analysis with Higher-Order FEM
- Part of
-
- Journal:
- Communications in Computational Physics / Volume 22 / Issue 4 / October 2017
- Published online by Cambridge University Press:
- 28 July 2017, pp. 997-1014
- Print publication:
- October 2017
-
- Article
- Export citation
Convex Polygons in Geometric Triangulations†
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 26 / Issue 5 / September 2017
- Published online by Cambridge University Press:
- 30 May 2017, pp. 641-659
-
- Article
- Export citation
PyCFTBoot: A Flexible Interface for the Conformal Bootstrap
- Part of
-
- Journal:
- Communications in Computational Physics / Volume 22 / Issue 1 / July 2017
- Published online by Cambridge University Press:
- 03 May 2017, pp. 1-38
- Print publication:
- July 2017
-
- Article
- Export citation
Delaunay Graph Based Inverse Distance Weighting for Fast Dynamic Meshing
- Part of
-
- Journal:
- Communications in Computational Physics / Volume 21 / Issue 5 / May 2017
- Published online by Cambridge University Press:
- 27 March 2017, pp. 1282-1309
- Print publication:
- May 2017
-
- Article
- Export citation
From coin tossing to rock-paper-scissors and beyond: a log-exp gap theorem for selecting a leader
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 54 / Issue 1 / March 2017
- Published online by Cambridge University Press:
- 04 April 2017, pp. 213-235
- Print publication:
- March 2017
-
- Article
- Export citation
A Robust and Efficient Adaptive Multigrid Solver for the Optimal Control of Phase Field Formulations of Geometric Evolution Laws
- Part of
-
- Journal:
- Communications in Computational Physics / Volume 21 / Issue 1 / January 2017
- Published online by Cambridge University Press:
- 05 December 2016, pp. 65-92
- Print publication:
- January 2017
-
- Article
- Export citation
New Non-Travelling Wave Solutions of Calogero Equation
- Part of
-
- Journal:
- Advances in Applied Mathematics and Mechanics / Volume 8 / Issue 6 / December 2016
- Published online by Cambridge University Press:
- 19 September 2016, pp. 1036-1049
- Print publication:
- December 2016
-
- Article
- Export citation
An algorithm for NTRU problems and cryptanalysis of the GGH multilinear map without a low-level encoding of zero
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 19 / Issue A / 2016
- Published online by Cambridge University Press:
- 26 August 2016, pp. 255-266
-
- Article
-
- You have access
- Export citation
-
Let
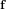 $\mathbf{f}$ and
$\mathbf{f}$ and  $\mathbf{g}$ be polynomials of a bounded Euclidean norm in the ring
$\mathbf{g}$ be polynomials of a bounded Euclidean norm in the ring 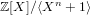 $\mathbb{Z}[X]/\langle X^{n}+1\rangle$ . Given the polynomial
$\mathbb{Z}[X]/\langle X^{n}+1\rangle$ . Given the polynomial 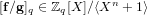 $[\mathbf{f}/\mathbf{g}]_{q}\in \mathbb{Z}_{q}[X]/\langle X^{n}+1\rangle$ , the NTRU problem is to find
$[\mathbf{f}/\mathbf{g}]_{q}\in \mathbb{Z}_{q}[X]/\langle X^{n}+1\rangle$ , the NTRU problem is to find 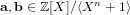 $\mathbf{a},\mathbf{b}\in \mathbb{Z}[X]/\langle X^{n}+1\rangle$ with a small Euclidean norm such that
$\mathbf{a},\mathbf{b}\in \mathbb{Z}[X]/\langle X^{n}+1\rangle$ with a small Euclidean norm such that 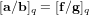 $[\mathbf{a}/\mathbf{b}]_{q}=[\mathbf{f}/\mathbf{g}]_{q}$ . We propose an algorithm to solve the NTRU problem, which runs in
$[\mathbf{a}/\mathbf{b}]_{q}=[\mathbf{f}/\mathbf{g}]_{q}$ . We propose an algorithm to solve the NTRU problem, which runs in 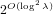 $2^{O(\log ^{2}\unicode[STIX]{x1D706})}$ time when
$2^{O(\log ^{2}\unicode[STIX]{x1D706})}$ time when 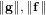 $\Vert \mathbf{g}\Vert ,\Vert \mathbf{f}\Vert$ , and
$\Vert \mathbf{g}\Vert ,\Vert \mathbf{f}\Vert$ , and 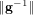 $\Vert \mathbf{g}^{-1}\Vert$ are within some range. The main technique of our algorithm is the reduction of a problem on a field to one on a subfield. The GGH scheme, the first candidate of an (approximate) multilinear map, was recently found to be insecure by the Hu–Jia attack using low-level encodings of zero, but no polynomial-time attack was known without them. In the GGH scheme without low-level encodings of zero, our algorithm can be directly applied to attack this scheme if we have some top-level encodings of zero and a known pair of plaintext and ciphertext. Using our algorithm, we can construct a level-
$\Vert \mathbf{g}^{-1}\Vert$ are within some range. The main technique of our algorithm is the reduction of a problem on a field to one on a subfield. The GGH scheme, the first candidate of an (approximate) multilinear map, was recently found to be insecure by the Hu–Jia attack using low-level encodings of zero, but no polynomial-time attack was known without them. In the GGH scheme without low-level encodings of zero, our algorithm can be directly applied to attack this scheme if we have some top-level encodings of zero and a known pair of plaintext and ciphertext. Using our algorithm, we can construct a level-  $0$ encoding of zero and utilize it to attack a security ground of this scheme in the quasi-polynomial time of its security parameter using the parameters suggested by Garg, Gentry and Halevi [‘Candidate multilinear maps from ideal lattices’, Advances in cryptology — EUROCRYPT 2013 (Springer, 2013) 1–17].
$0$ encoding of zero and utilize it to attack a security ground of this scheme in the quasi-polynomial time of its security parameter using the parameters suggested by Garg, Gentry and Halevi [‘Candidate multilinear maps from ideal lattices’, Advances in cryptology — EUROCRYPT 2013 (Springer, 2013) 1–17].
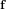

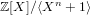
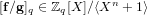
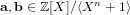
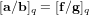
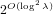
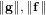
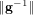

Direct Gravitational Search Algorithm for Global Optimisation Problems
- Part of
-
- Journal:
- East Asian Journal on Applied Mathematics / Volume 6 / Issue 3 / August 2016
- Published online by Cambridge University Press:
- 20 July 2016, pp. 290-313
- Print publication:
- August 2016
-
- Article
- Export citation
Efficient Implementation of Smoothed Particle Hydrodynamics (SPH) with Plane Sweep Algorithm
- Part of
-
- Journal:
- Communications in Computational Physics / Volume 19 / Issue 3 / March 2016
- Published online by Cambridge University Press:
- 16 March 2016, pp. 770-800
- Print publication:
- March 2016
-
- Article
- Export citation
-
Neighbour search (NS) is the core of any implementations of smoothed particle hydrodynamics (SPH). In this paper,we present an efficient
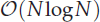 neighbour search method based on the plane sweep (PW) algorithm with N being the number of SPH particles. The resulting method, dubbed the PWNS method, is totally independent of grids (i.e., purely meshfree) and capable of treating variable smoothing length, arbitrary particle distribution and heterogenous kernels. Several state-of-the-art data structures and algorithms, e.g., the segment tree and the Morton code, are optimized and implemented. By simply allowingmultiple lines to sweep the SPH particles simultaneously from different initial positions, a parallelization of the PWNS method with satisfactory speedup and load-balancing can be easily achieved. That is, the PWNS SPH solver has a great potential for large scale fluid dynamics simulations.
neighbour search method based on the plane sweep (PW) algorithm with N being the number of SPH particles. The resulting method, dubbed the PWNS method, is totally independent of grids (i.e., purely meshfree) and capable of treating variable smoothing length, arbitrary particle distribution and heterogenous kernels. Several state-of-the-art data structures and algorithms, e.g., the segment tree and the Morton code, are optimized and implemented. By simply allowingmultiple lines to sweep the SPH particles simultaneously from different initial positions, a parallelization of the PWNS method with satisfactory speedup and load-balancing can be easily achieved. That is, the PWNS SPH solver has a great potential for large scale fluid dynamics simulations.
 neighbour search method based on the plane sweep (PW) algorithm with
neighbour search method based on the plane sweep (PW) algorithm with The Multiple-Orientability Thresholds for Random Hypergraphs†
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 25 / Issue 6 / November 2016
- Published online by Cambridge University Press:
- 28 December 2015, pp. 870-908
-
- Article
- Export citation
Multivariate Distributions with Fixed Marginals and Correlations
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 52 / Issue 2 / June 2015
- Published online by Cambridge University Press:
- 30 January 2018, pp. 602-608
- Print publication:
- June 2015
-
- Article
-
- You have access
- Export citation
A Binomial Splitting Process in Connection with Corner Parking Problems
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 51 / Issue 4 / December 2014
- Published online by Cambridge University Press:
- 30 January 2018, pp. 971-989
- Print publication:
- December 2014
-
- Article
-
- You have access
- Export citation
A study of the representations supported by the orbit closure of the determinant
- Part of
-
- Journal:
- Compositio Mathematica / Volume 151 / Issue 2 / February 2015
- Published online by Cambridge University Press:
- 24 October 2014, pp. 292-312
- Print publication:
- February 2015
-
- Article
- Export citation
Approximating the densest sublattice from Rankin’s inequality
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue A / 2014
- Published online by Cambridge University Press:
- 01 August 2014, pp. 92-111
-
- Article
-
- You have access
- Export citation
Rational functions with maximal radius of absolute monotonicity
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue 1 / 2014
- Published online by Cambridge University Press:
- 01 May 2014, pp. 159-205
-
- Article
-
- You have access
- Export citation
-
We study the radius of absolute monotonicity
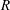 $R$ of rational functions with numerator and denominator of degree
$R$ of rational functions with numerator and denominator of degree  $s$ that approximate the exponential function to order
$s$ that approximate the exponential function to order 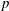 $p$ . Such functions arise in the application of implicit
$p$ . Such functions arise in the application of implicit  $s$ -stage, order
$s$ -stage, order 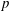 $p$ Runge–Kutta methods for initial value problems, and the radius of absolute monotonicity governs the numerical preservation of properties like positivity and maximum-norm contractivity. We construct a function with
$p$ Runge–Kutta methods for initial value problems, and the radius of absolute monotonicity governs the numerical preservation of properties like positivity and maximum-norm contractivity. We construct a function with 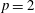 $p=2$ and
$p=2$ and 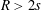 $R>2s$ , disproving a conjecture of van de Griend and Kraaijevanger. We determine the maximum attainable radius for functions in several one-parameter families of rational functions. Moreover, we prove earlier conjectured optimal radii in some families with two or three parameters via uniqueness arguments for systems of polynomial inequalities. Our results also prove the optimality of some strong stability preserving implicit and singly diagonally implicit Runge–Kutta methods. Whereas previous results in this area were primarily numerical, we give all constants as exact algebraic numbers.
$R>2s$ , disproving a conjecture of van de Griend and Kraaijevanger. We determine the maximum attainable radius for functions in several one-parameter families of rational functions. Moreover, we prove earlier conjectured optimal radii in some families with two or three parameters via uniqueness arguments for systems of polynomial inequalities. Our results also prove the optimality of some strong stability preserving implicit and singly diagonally implicit Runge–Kutta methods. Whereas previous results in this area were primarily numerical, we give all constants as exact algebraic numbers.
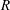

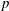

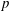
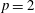
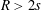
A note on uniform approximation of functions having a double pole
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue 1 / 2014
- Published online by Cambridge University Press:
- 01 May 2014, pp. 233-244
-
- Article
-
- You have access
- Export citation
-
We consider the classical problem of finding the best uniform approximation by polynomials of
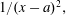 $1/(x-a)^2,$ where
$1/(x-a)^2,$ where 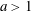 $a>1$ is given, on the interval
$a>1$ is given, on the interval 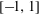 $[-\! 1,1]$ . First, using symbolic computation tools we derive the explicit expressions of the polynomials of best approximation of low degrees and then give a parametric solution of the problem in terms of elliptic functions. Symbolic computation is invoked then once more to derive a recurrence relation for the coefficients of the polynomials of best uniform approximation based on a Pell-type equation satisfied by the solutions.
$[-\! 1,1]$ . First, using symbolic computation tools we derive the explicit expressions of the polynomials of best approximation of low degrees and then give a parametric solution of the problem in terms of elliptic functions. Symbolic computation is invoked then once more to derive a recurrence relation for the coefficients of the polynomials of best uniform approximation based on a Pell-type equation satisfied by the solutions.
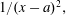
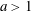
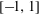
Deterministic polynomial factoring and association schemes
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue 1 / 2014
- Published online by Cambridge University Press:
- 01 April 2014, pp. 123-140
-
- Article
-
- You have access
- Export citation
-
The problem of finding a nontrivial factor of a polynomial
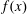 $f(x)$ over a finite field
$f(x)$ over a finite field 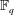 ${\mathbb{F}}_q$ has many known efficient, but randomized, algorithms. The deterministic complexity of this problem is a famous open question even assuming the generalized Riemann hypothesis (GRH). In this work we improve the state of the art by focusing on prime degree polynomials; let
${\mathbb{F}}_q$ has many known efficient, but randomized, algorithms. The deterministic complexity of this problem is a famous open question even assuming the generalized Riemann hypothesis (GRH). In this work we improve the state of the art by focusing on prime degree polynomials; let  $n$ be the degree. If
$n$ be the degree. If 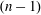 $(n-1)$ has a‘large’
$(n-1)$ has a‘large’  $r$ -smooth divisor
$r$ -smooth divisor  $s$ , then we find a nontrivial factor of
$s$ , then we find a nontrivial factor of 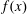 $f(x)$ in deterministic
$f(x)$ in deterministic 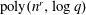 $\mbox{poly}(n^r,\log q)$ time, assuming GRH and that
$\mbox{poly}(n^r,\log q)$ time, assuming GRH and that 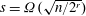 $s=\Omega (\sqrt{n/2^r})$ . Thus, for
$s=\Omega (\sqrt{n/2^r})$ . Thus, for 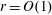 $r=O(1)$ our algorithm is polynomial time. Further, for
$r=O(1)$ our algorithm is polynomial time. Further, for 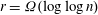 $r=\Omega (\log \log n)$ there are infinitely many prime degrees
$r=\Omega (\log \log n)$ there are infinitely many prime degrees  $n$ for which our algorithm is applicable and better than the best known, assuming GRH. Our methods build on the algebraic-combinatorial framework of
$n$ for which our algorithm is applicable and better than the best known, assuming GRH. Our methods build on the algebraic-combinatorial framework of 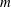 $m$ -schemes initiated by Ivanyos, Karpinski and Saxena (ISSAC 2009). We show that the
$m$ -schemes initiated by Ivanyos, Karpinski and Saxena (ISSAC 2009). We show that the 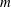 $m$ -scheme on
$m$ -scheme on  $n$ points, implicitly appearing in our factoring algorithm, has an exceptional structure, leading us to the improved time complexity. Our structure theorem proves the existence of small intersection numbers in any association scheme that has many relations, and roughly equal valencies and indistinguishing numbers.
$n$ points, implicitly appearing in our factoring algorithm, has an exceptional structure, leading us to the improved time complexity. Our structure theorem proves the existence of small intersection numbers in any association scheme that has many relations, and roughly equal valencies and indistinguishing numbers.