Refine listing
Actions for selected content:
87 results in 68Wxx
The critical mean-field Chayes–Machta dynamics
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 31 / Issue 6 / November 2022
- Published online by Cambridge University Press:
- 11 May 2022, pp. 924-975
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The random-cluster model is a unifying framework for studying random graphs, spin systems and electrical networks that plays a fundamental role in designing efficient Markov Chain Monte Carlo (MCMC) sampling algorithms for the classical ferromagnetic Ising and Potts models. In this paper, we study a natural non-local Markov chain known as the Chayes–Machta (CM) dynamics for the mean-field case of the random-cluster model, where the underlying graph is the complete graph on n vertices. The random-cluster model is parametrised by an edge probability p and a cluster weight q. Our focus is on the critical regime:
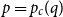 $p = p_c(q)$ and
$p = p_c(q)$ and 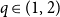 $q \in (1,2)$, where
$q \in (1,2)$, where 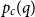 $p_c(q)$ is the threshold corresponding to the order–disorder phase transition of the model. We show that the mixing time of the CM dynamics is
$p_c(q)$ is the threshold corresponding to the order–disorder phase transition of the model. We show that the mixing time of the CM dynamics is 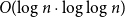 $O({\log}\ n \cdot \log \log n)$ in this parameter regime, which reveals that the dynamics does not undergo an exponential slowdown at criticality, a surprising fact that had been predicted (but not proved) by statistical physicists. This also provides a nearly optimal bound (up to the
$O({\log}\ n \cdot \log \log n)$ in this parameter regime, which reveals that the dynamics does not undergo an exponential slowdown at criticality, a surprising fact that had been predicted (but not proved) by statistical physicists. This also provides a nearly optimal bound (up to the 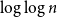 $\log\log n$ factor) for the mixing time of the mean-field CM dynamics in the only regime of parameters where no non-trivial bound was previously known. Our proof consists of a multi-phased coupling argument that combines several key ingredients, including a new local limit theorem, a precise bound on the maximum of symmetric random walks with varying step sizes and tailored estimates for critical random graphs. In addition, we derive an improved comparison inequality between the mixing time of the CM dynamics and that of the local Glauber dynamics on general graphs; this results in better mixing time bounds for the local dynamics in the mean-field setting.
$\log\log n$ factor) for the mixing time of the mean-field CM dynamics in the only regime of parameters where no non-trivial bound was previously known. Our proof consists of a multi-phased coupling argument that combines several key ingredients, including a new local limit theorem, a precise bound on the maximum of symmetric random walks with varying step sizes and tailored estimates for critical random graphs. In addition, we derive an improved comparison inequality between the mixing time of the CM dynamics and that of the local Glauber dynamics on general graphs; this results in better mixing time bounds for the local dynamics in the mean-field setting.
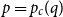
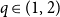
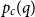
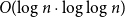
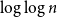
Lee–Yang zeros and the complexity of the ferromagnetic Ising model on bounded-degree graphs
- Part of
-
- Journal:
- Forum of Mathematics, Sigma / Volume 10 / 2022
- Published online by Cambridge University Press:
- 07 February 2022, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study the computational complexity of approximating the partition function of the ferromagnetic Ising model with the external field parameter
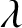 $\lambda $ on the unit circle in the complex plane. Complex-valued parameters for the Ising model are relevant for quantum circuit computations and phase transitions in statistical physics but have also been key in the recent deterministic approximation scheme for all
$\lambda $ on the unit circle in the complex plane. Complex-valued parameters for the Ising model are relevant for quantum circuit computations and phase transitions in statistical physics but have also been key in the recent deterministic approximation scheme for all 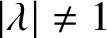 $|\lambda |\neq 1$ by Liu, Sinclair and Srivastava. Here, we focus on the unresolved complexity picture on the unit circle and on the tantalising question of what happens around
$|\lambda |\neq 1$ by Liu, Sinclair and Srivastava. Here, we focus on the unresolved complexity picture on the unit circle and on the tantalising question of what happens around 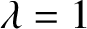 $\lambda =1$, where, on one hand, the classical algorithm of Jerrum and Sinclair gives a randomised approximation scheme on the real axis suggesting tractability and, on the other hand, the presence of Lee–Yang zeros alludes to computational hardness. Our main result establishes a sharp computational transition at the point
$\lambda =1$, where, on one hand, the classical algorithm of Jerrum and Sinclair gives a randomised approximation scheme on the real axis suggesting tractability and, on the other hand, the presence of Lee–Yang zeros alludes to computational hardness. Our main result establishes a sharp computational transition at the point 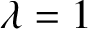 $\lambda =1$ and, more generally, on the entire unit circle. For an integer
$\lambda =1$ and, more generally, on the entire unit circle. For an integer 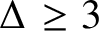 $\Delta \geq 3$ and edge interaction parameter
$\Delta \geq 3$ and edge interaction parameter 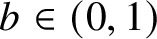 $b\in (0,1)$, we show
$b\in (0,1)$, we show 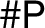 $\mathsf {\#P}$-hardness for approximating the partition function on graphs of maximum degree
$\mathsf {\#P}$-hardness for approximating the partition function on graphs of maximum degree 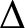 $\Delta $ on the arc of the unit circle where the Lee–Yang zeros are dense. This result contrasts with known approximation algorithms when
$\Delta $ on the arc of the unit circle where the Lee–Yang zeros are dense. This result contrasts with known approximation algorithms when 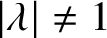 $|\lambda |\neq 1$ or when
$|\lambda |\neq 1$ or when 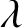 $\lambda $ is in the complementary arc around
$\lambda $ is in the complementary arc around 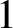 $1$ of the unit circle. Our work thus gives a direct connection between the presence/absence of Lee–Yang zeros and the tractability of efficiently approximating the partition function on bounded-degree graphs.
$1$ of the unit circle. Our work thus gives a direct connection between the presence/absence of Lee–Yang zeros and the tractability of efficiently approximating the partition function on bounded-degree graphs.
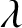
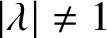
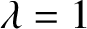
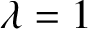
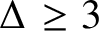
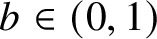
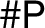
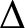
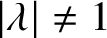
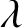
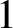
Spectral alignment of correlated Gaussian matrices
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 54 / Issue 1 / March 2022
- Published online by Cambridge University Press:
- 28 January 2022, pp. 279-310
- Print publication:
- March 2022
-
- Article
- Export citation
-
In this paper we analyze a simple spectral method (EIG1) for the problem of matrix alignment, consisting in aligning their leading eigenvectors: given two matrices A and B, we compute two corresponding leading eigenvectors
 $v_1$ and
$v_1$ and 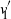 $v'_{\!\!1}$. The algorithm returns the permutation
$v'_{\!\!1}$. The algorithm returns the permutation 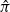 $\hat{\pi}$ such that the rank of coordinate
$\hat{\pi}$ such that the rank of coordinate 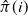 $\hat{\pi}(i)$ in
$\hat{\pi}(i)$ in 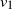 $v_1$ and that of coordinate i in
$v_1$ and that of coordinate i in 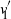 $v'_{\!\!1}$ (up to the sign of
$v'_{\!\!1}$ (up to the sign of 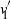 $v'_{\!\!1}$) are the same.
$v'_{\!\!1}$) are the same.We consider a model of weighted graphs where the adjacency matrix A belongs to the Gaussian orthogonal ensemble of size
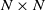 $N \times N$, and B is a noisy version of A where all nodes have been relabeled according to some planted permutation
$N \times N$, and B is a noisy version of A where all nodes have been relabeled according to some planted permutation 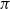 $\pi$; that is,
$\pi$; that is, 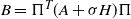 $B= \Pi^T (A+\sigma H) \Pi $, where
$B= \Pi^T (A+\sigma H) \Pi $, where 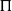 $\Pi$ is the permutation matrix associated with
$\Pi$ is the permutation matrix associated with 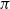 $\pi$ and H is an independent copy of A. We show the following zero–one law: with high probability, under the condition
$\pi$ and H is an independent copy of A. We show the following zero–one law: with high probability, under the condition 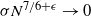 $\sigma N^{7/6+\epsilon} \to 0$ for some
$\sigma N^{7/6+\epsilon} \to 0$ for some 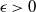 $\epsilon>0$, EIG1 recovers all but a vanishing part of the underlying permutation
$\epsilon>0$, EIG1 recovers all but a vanishing part of the underlying permutation 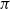 $\pi$, whereas if
$\pi$, whereas if 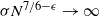 $\sigma N^{7/6-\epsilon} \to \infty$, this method cannot recover more than o(N) correct matches.
$\sigma N^{7/6-\epsilon} \to \infty$, this method cannot recover more than o(N) correct matches.This result gives an understanding of the simplest and fastest spectral method for matrix alignment (or complete weighted graph alignment), and involves proof methods and techniques which could be of independent interest.

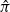
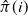
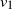
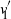
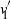
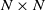
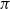
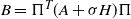
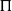
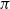
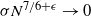
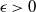
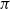
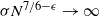
Rejection- and importance-sampling-based perfect simulation for Gibbs hard-sphere models
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 53 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 08 October 2021, pp. 839-885
- Print publication:
- September 2021
-
- Article
- Export citation
Average-case complexity of the Euclidean algorithm with a fixed polynomial over a finite field
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 31 / Issue 1 / January 2022
- Published online by Cambridge University Press:
- 06 July 2021, pp. 166-183
-
- Article
- Export citation
-
We analyse the behaviour of the Euclidean algorithm applied to pairs (g,f) of univariate nonconstant polynomials over a finite field
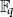 $\mathbb{F}_{q}$ of q elements when the highest degree polynomial g is fixed. Considering all the elements f of fixed degree, we establish asymptotically optimal bounds in terms of q for the number of elements f that are relatively prime with g and for the average degree of
$\mathbb{F}_{q}$ of q elements when the highest degree polynomial g is fixed. Considering all the elements f of fixed degree, we establish asymptotically optimal bounds in terms of q for the number of elements f that are relatively prime with g and for the average degree of 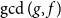 $\gcd(g,f)$. We also exhibit asymptotically optimal bounds for the average-case complexity of the Euclidean algorithm applied to pairs (g,f) as above.
$\gcd(g,f)$. We also exhibit asymptotically optimal bounds for the average-case complexity of the Euclidean algorithm applied to pairs (g,f) as above.
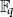
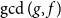
More on zeros and approximation of the Ising partition function
- Part of
-
- Journal:
- Forum of Mathematics, Sigma / Volume 9 / 2021
- Published online by Cambridge University Press:
- 07 June 2021, e46
-
- Article
-
- You have access
- Open access
- Export citation
-
We consider the problem of computing the partition function
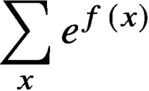 $\sum _x e^{f(x)}$, where
$\sum _x e^{f(x)}$, where 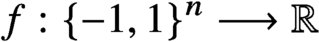 $f: \{-1, 1\}^n \longrightarrow {\mathbb R}$ is a quadratic or cubic polynomial on the Boolean cube
$f: \{-1, 1\}^n \longrightarrow {\mathbb R}$ is a quadratic or cubic polynomial on the Boolean cube 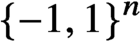 $\{-1, 1\}^n$. In the case of a quadratic polynomial f, we show that the partition function can be approximated within relative error
$\{-1, 1\}^n$. In the case of a quadratic polynomial f, we show that the partition function can be approximated within relative error 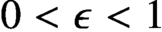 $0 < \epsilon < 1$ in quasi-polynomial
$0 < \epsilon < 1$ in quasi-polynomial 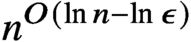 $n^{O(\ln n - \ln \epsilon )}$ time if the Lipschitz constant of the non-linear part of f with respect to the
$n^{O(\ln n - \ln \epsilon )}$ time if the Lipschitz constant of the non-linear part of f with respect to the 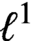 $\ell ^1$ metric on the Boolean cube does not exceed
$\ell ^1$ metric on the Boolean cube does not exceed 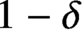 $1-\delta $, for any
$1-\delta $, for any 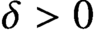 $\delta>0$, fixed in advance. For a cubic polynomial f, we get the same result under a somewhat stronger condition. We apply the method of polynomial interpolation, for which we prove that
$\delta>0$, fixed in advance. For a cubic polynomial f, we get the same result under a somewhat stronger condition. We apply the method of polynomial interpolation, for which we prove that 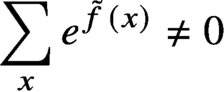 $\sum _x e^{\tilde {f}(x)} \ne 0$ for complex-valued polynomials
$\sum _x e^{\tilde {f}(x)} \ne 0$ for complex-valued polynomials 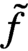 $\tilde {f}$ in a neighborhood of a real-valued f satisfying the above mentioned conditions. The bounds are asymptotically optimal. Results on the zero-free region are interpreted as the absence of a phase transition in the Lee–Yang sense in the corresponding Ising model. The novel feature of the bounds is that they control the total interaction of each vertex but not every single interaction of sets of vertices.
$\tilde {f}$ in a neighborhood of a real-valued f satisfying the above mentioned conditions. The bounds are asymptotically optimal. Results on the zero-free region are interpreted as the absence of a phase transition in the Lee–Yang sense in the corresponding Ising model. The novel feature of the bounds is that they control the total interaction of each vertex but not every single interaction of sets of vertices.
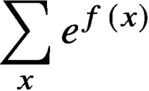
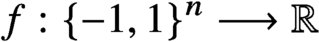
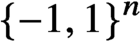
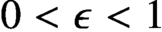
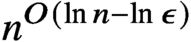
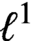
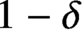
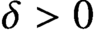
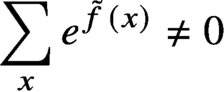
AN ALGORITHM OF COMPUTING COHOMOLOGY INTERSECTION NUMBER OF HYPERGEOMETRIC INTEGRALS
- Part of
-
- Journal:
- Nagoya Mathematical Journal / Volume 246 / June 2022
- Published online by Cambridge University Press:
- 07 May 2021, pp. 256-272
-
- Article
- Export citation
Polynomial-time approximation algorithms for the antiferromagnetic Ising model on line graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 6 / November 2021
- Published online by Cambridge University Press:
- 12 April 2021, pp. 905-921
-
- Article
- Export citation
Tail bounds on hitting times of randomized search heuristics using variable drift analysis
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 4 / July 2021
- Published online by Cambridge University Press:
- 05 November 2020, pp. 550-569
-
- Article
-
- You have access
- Export citation
Approximately counting bases of bicircular matroids
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 1 / January 2021
- Published online by Cambridge University Press:
- 06 August 2020, pp. 124-135
-
- Article
- Export citation
Deterministic counting of graph colourings using sequences of subgraphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 4 / July 2020
- Published online by Cambridge University Press:
- 22 June 2020, pp. 555-586
-
- Article
- Export citation
-
In this paper we propose a polynomial-time deterministic algorithm for approximately counting the k-colourings of the random graph G(n, d/n), for constant d>0. In particular, our algorithm computes in polynomial time a
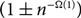 $(1\pm n^{-\Omega(1)})$-approximation of the so-called ‘free energy’ of the k-colourings of G(n, d/n), for
$(1\pm n^{-\Omega(1)})$-approximation of the so-called ‘free energy’ of the k-colourings of G(n, d/n), for 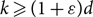 $k\geq (1+\varepsilon) d$ with probability
$k\geq (1+\varepsilon) d$ with probability 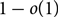 $1-o(1)$ over the graph instances.
$1-o(1)$ over the graph instances.Our algorithm uses spatial correlation decay to compute numerically estimates of marginals of the Gibbs distribution. Spatial correlation decay has been used in different counting schemes for deterministic counting. So far algorithms have exploited a certain kind of set-to-point correlation decay, e.g. the so-called Gibbs uniqueness. Here we deviate from this setting and exploit a point-to-point correlation decay. The spatial mixing requirement is that for a pair of vertices the correlation between their corresponding configurations becomes weaker with their distance.
Furthermore, our approach generalizes in that it allows us to compute the Gibbs marginals for small sets of nearby vertices. Also, we establish a connection between the fluctuations of the number of colourings of G(n, d/n) and the fluctuations of the number of short cycles and edges in the graph.
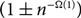
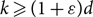
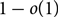
Estimating parameters associated with monotone properties
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 4 / July 2020
- Published online by Cambridge University Press:
- 24 March 2020, pp. 616-632
-
- Article
- Export citation
-
There has been substantial interest in estimating the value of a graph parameter, i.e. of a real-valued function defined on the set of finite graphs, by querying a randomly sampled substructure whose size is independent of the size of the input. Graph parameters that may be successfully estimated in this way are said to be testable or estimable, and the sample complexity qz = qz(ε) of an estimable parameter z is the size of a random sample of a graph G required to ensure that the value of z(G) may be estimated within an error of ε with probability at least 2/3. In this paper, for any fixed monotone graph property
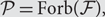 $\mathcal{P}= \text{Forb}\!(\mathcal{F}),$ we study the sample complexity of estimating a bounded graph parameter z that, for an input graph G, counts the number of spanning subgraphs of G that satisfy
$\mathcal{P}= \text{Forb}\!(\mathcal{F}),$ we study the sample complexity of estimating a bounded graph parameter z that, for an input graph G, counts the number of spanning subgraphs of G that satisfy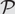 $\mathcal{P}$. To improve upon previous upper bounds on the sample complexity, we show that the vertex set of any graph that satisfies a monotone property $\mathcal{P}$ may be partitioned equitably into a constant number of classes in such a way that the cluster graph induced by the partition is not far from satisfying a natural weighted graph generalization of $\mathcal{P}$. Properties for which this holds are said to be recoverable, and the study of recoverable properties may be of independent interest.
$\mathcal{P}$. To improve upon previous upper bounds on the sample complexity, we show that the vertex set of any graph that satisfies a monotone property $\mathcal{P}$ may be partitioned equitably into a constant number of classes in such a way that the cluster graph induced by the partition is not far from satisfying a natural weighted graph generalization of $\mathcal{P}$. Properties for which this holds are said to be recoverable, and the study of recoverable properties may be of independent interest.
The string of diamonds is nearly tight for rumour spreading
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 2 / March 2020
- Published online by Cambridge University Press:
- 04 November 2019, pp. 190-199
-
- Article
- Export citation
-
For a rumour spreading protocol, the spread time is defined as the first time everyone learns the rumour. We compare the synchronous push&pull rumour spreading protocol with its asynchronous variant, and show that for any n-vertex graph and any starting vertex, the ratio between their expected spread times is bounded by
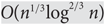 $O({n^{1/3}}{\log ^{2/3}}n)$. This improves the
$O({n^{1/3}}{\log ^{2/3}}n)$. This improves the 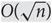 $O(\sqrt n)$ upper bound of Giakkoupis, Nazari and Woelfel (2016). Our bound is tight up to a factor of O(log n), as illustrated by the string of diamonds graph. We also show that if, for a pair α, β of real numbers, there exist infinitely many graphs for which the two spread times are nα and nβ in expectation, then
$O(\sqrt n)$ upper bound of Giakkoupis, Nazari and Woelfel (2016). Our bound is tight up to a factor of O(log n), as illustrated by the string of diamonds graph. We also show that if, for a pair α, β of real numbers, there exist infinitely many graphs for which the two spread times are nα and nβ in expectation, then 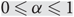 $0 \le \alpha \le 1$ and
$0 \le \alpha \le 1$ and  $\alpha \le \beta \le {1 \over 3} + {2 \over 3} \alpha $; and we show each such pair α, β is achievable.
$\alpha \le \beta \le {1 \over 3} + {2 \over 3} \alpha $; and we show each such pair α, β is achievable.
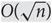
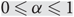

Weighted counting of solutions to sparse systems of equations
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 5 / September 2019
- Published online by Cambridge University Press:
- 15 April 2019, pp. 696-719
-
- Article
- Export citation
-
Given complex numbers w1,…,wn, we define the weight w(X) of a set X of 0–1 vectors as the sum of
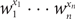 $w_1^{x_1} \cdots w_n^{x_n}$ over all vectors (x1,…,xn) in X. We present an algorithm which, for a set X defined by a system of homogeneous linear equations with at most r variables per equation and at most c equations per variable, computes w(X) within relative error ∊ > 0 in (rc)O(lnn-ln∊) time provided
$w_1^{x_1} \cdots w_n^{x_n}$ over all vectors (x1,…,xn) in X. We present an algorithm which, for a set X defined by a system of homogeneous linear equations with at most r variables per equation and at most c equations per variable, computes w(X) within relative error ∊ > 0 in (rc)O(lnn-ln∊) time provided 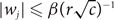 $|w_j| \leq \beta (r \sqrt{c})^{-1}$ for an absolute constant β > 0 and all j = 1,…,n. A similar algorithm is constructed for computing the weight of a linear code over
$|w_j| \leq \beta (r \sqrt{c})^{-1}$ for an absolute constant β > 0 and all j = 1,…,n. A similar algorithm is constructed for computing the weight of a linear code over 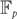 ${\mathbb F}_p$. Applications include counting weighted perfect matchings in hypergraphs, counting weighted graph homomorphisms, computing weight enumerators of linear codes with sparse code generating matrices, and computing the partition functions of the ferromagnetic Potts model at low temperatures and of the hard-core model at high fugacity on biregular bipartite graphs.
${\mathbb F}_p$. Applications include counting weighted perfect matchings in hypergraphs, counting weighted graph homomorphisms, computing weight enumerators of linear codes with sparse code generating matrices, and computing the partition functions of the ferromagnetic Potts model at low temperatures and of the hard-core model at high fugacity on biregular bipartite graphs.
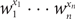
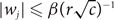
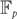
Perturbation Analysis of Orthogonal Least Squares
- Part of
-
- Journal:
- Canadian Mathematical Bulletin / Volume 62 / Issue 4 / December 2019
- Published online by Cambridge University Press:
- 22 March 2019, pp. 780-797
- Print publication:
- December 2019
-
- Article
-
- You have access
- Export citation
-
The Orthogonal Least Squares (OLS) algorithm is an efficient sparse recovery algorithm that has received much attention in recent years. On one hand, this paper considers that the OLS algorithm recovers the supports of sparse signals in the noisy case. We show that the OLS algorithm exactly recovers the support of
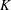 $K$-sparse signal
$K$-sparse signal  $\boldsymbol{x}$ from
$\boldsymbol{x}$ from 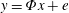 $\boldsymbol{y}=\boldsymbol{\unicode[STIX]{x1D6F7}}\boldsymbol{x}+\boldsymbol{e}$ in
$\boldsymbol{y}=\boldsymbol{\unicode[STIX]{x1D6F7}}\boldsymbol{x}+\boldsymbol{e}$ in 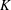 $K$ iterations, provided that the sensing matrix
$K$ iterations, provided that the sensing matrix 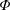 $\boldsymbol{\unicode[STIX]{x1D6F7}}$ satisfies the restricted isometry property (RIP) with restricted isometry constant (RIC)
$\boldsymbol{\unicode[STIX]{x1D6F7}}$ satisfies the restricted isometry property (RIP) with restricted isometry constant (RIC) 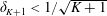 $\unicode[STIX]{x1D6FF}_{K+1}<1/\sqrt{K+1}$, and the minimum magnitude of the nonzero elements of
$\unicode[STIX]{x1D6FF}_{K+1}<1/\sqrt{K+1}$, and the minimum magnitude of the nonzero elements of  $\boldsymbol{x}$ satisfies some constraint. On the other hand, this paper demonstrates that the OLS algorithm exactly recovers the support of the best
$\boldsymbol{x}$ satisfies some constraint. On the other hand, this paper demonstrates that the OLS algorithm exactly recovers the support of the best 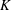 $K$-term approximation of an almost sparse signal
$K$-term approximation of an almost sparse signal  $\boldsymbol{x}$ in the general perturbations case, which means both
$\boldsymbol{x}$ in the general perturbations case, which means both 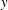 $\boldsymbol{y}$ and
$\boldsymbol{y}$ and 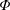 $\boldsymbol{\unicode[STIX]{x1D6F7}}$ are perturbed. We show that the support of the best
$\boldsymbol{\unicode[STIX]{x1D6F7}}$ are perturbed. We show that the support of the best 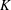 $K$-term approximation of
$K$-term approximation of  $\boldsymbol{x}$ can be recovered under reasonable conditions based on the restricted isometry property (RIP).
$\boldsymbol{x}$ can be recovered under reasonable conditions based on the restricted isometry property (RIP).
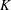

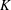
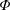
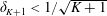

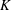

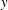
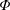
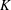

Analysis of Robin Hood and Other Hashing Algorithms Under the Random Probing Model, With and Without Deletions
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 4 / July 2019
- Published online by Cambridge University Press:
- 14 August 2018, pp. 600-617
-
- Article
- Export citation
Dual-Pivot Quicksort: Optimality, Analysis and Zeros of Associated Lattice Paths
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 4 / July 2019
- Published online by Cambridge University Press:
- 14 August 2018, pp. 485-518
-
- Article
- Export citation
Asymmetric Rényi Problem
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 28 / Issue 4 / July 2019
- Published online by Cambridge University Press:
- 27 June 2018, pp. 542-573
-
- Article
- Export citation
-
In 1960 Rényi, in his Michigan State University lectures, asked for the number of random queries necessary to recover a hidden bijective labelling of n distinct objects. In each query one selects a random subset of labels and asks, which objects have these labels? We consider here an asymmetric version of the problem in which in every query an object is chosen with probability p > 1/2 and we ignore ‘inconclusive’ queries. We study the number of queries needed to recover the labelling in its entirety (Hn), before at least one element is recovered (Fn), and to recover a randomly chosen element (Dn). This problem exhibits several remarkable behaviours: Dn converges in probability but not almost surely; Hn and Fn exhibit phase transitions with respect to p in the second term. We prove that for p > 1/2 with high probability we need
queries to recover the entire bijection. This should be compared to its symmetric (p = 1/2) counterpart established by Pittel and Rubin, who proved that in this case one requires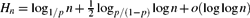 $$H_n=\log_{1/p} n +{\tfrac{1}{2}} \log_{p/(1-p)}\log n +o(\log \log n)$$queries. As a bonus, our analysis implies novel results for random PATRICIA tries, as the problem is probabilistically equivalent to that of the height, fillup level, and typical depth of a PATRICIA trie built from n independent binary sequences generated by a biased(p) memoryless source.
$$H_n=\log_{1/p} n +{\tfrac{1}{2}} \log_{p/(1-p)}\log n +o(\log \log n)$$queries. As a bonus, our analysis implies novel results for random PATRICIA tries, as the problem is probabilistically equivalent to that of the height, fillup level, and typical depth of a PATRICIA trie built from n independent binary sequences generated by a biased(p) memoryless source.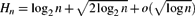 $$ H_n=\log_{2} n +\sqrt{2 \log_{2} n} +o(\sqrt{\log n})$$
$$ H_n=\log_{2} n +\sqrt{2 \log_{2} n} +o(\sqrt{\log n})$$
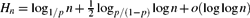
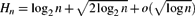
GLOBAL A PRIORI IDENTIFIABILITY OF MODELS OF FLOW-CELL OPTICAL BIOSENSOR EXPERIMENTS
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 98 / Issue 2 / October 2018
- Published online by Cambridge University Press:
- 14 June 2018, pp. 350-352
- Print publication:
- October 2018
-
- Article
-
- You have access
- Export citation
Fast Property Testing and Metrics for Permutations
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 27 / Issue 4 / July 2018
- Published online by Cambridge University Press:
- 24 May 2018, pp. 539-579
-
- Article
- Export citation
