Refine listing
Actions for selected content:
148 results in 62Gxx
DISTRIBUTION-FREE CONFIDENCE INTERVALS FOR FUNCTIONS OF QUANTILES
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 103 / Issue 3 / June 2021
- Published online by Cambridge University Press:
- 17 September 2020, pp. 520-522
- Print publication:
- June 2021
-
- Article
-
- You have access
- Export citation
Limit theory for unbiased and consistent estimators of statistics of random tessellations
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 57 / Issue 2 / June 2020
- Published online by Cambridge University Press:
- 16 July 2020, pp. 679-702
- Print publication:
- June 2020
-
- Article
- Export citation
On the multi-state signatures of ordered system lifetimes
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 52 / Issue 1 / March 2020
- Published online by Cambridge University Press:
- 29 April 2020, pp. 291-318
- Print publication:
- March 2020
-
- Article
- Export citation
Some new results on stochastic comparisons of coherent systems using signatures
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 57 / Issue 1 / March 2020
- Published online by Cambridge University Press:
- 04 May 2020, pp. 156-173
- Print publication:
- March 2020
-
- Article
- Export citation
ROUGH INTEGERS WITH A DIVISOR IN A GIVEN INTERVAL
- Part of
-
- Journal:
- Journal of the Australian Mathematical Society / Volume 111 / Issue 1 / August 2021
- Published online by Cambridge University Press:
- 08 January 2020, pp. 17-36
- Print publication:
- August 2021
-
- Article
- Export citation
-
We determine, up to multiplicative constants, the number of integers
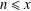 $n\leq x$ that have a divisor in
$n\leq x$ that have a divisor in 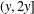 $(y,2y]$ and no prime factor
$(y,2y]$ and no prime factor 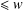 $\leq w$. Our estimate is uniform in
$\leq w$. Our estimate is uniform in 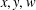 $x,y,w$. We apply this to determine the order of the number of distinct integers in the
$x,y,w$. We apply this to determine the order of the number of distinct integers in the 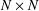 $N\times N$ multiplication table, which are free of prime factors
$N\times N$ multiplication table, which are free of prime factors 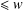 $\leq w$, and the number of distinct fractions of the form
$\leq w$, and the number of distinct fractions of the form 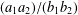 $(a_{1}a_{2})/(b_{1}b_{2})$ with
$(a_{1}a_{2})/(b_{1}b_{2})$ with 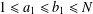 $1\leq a_{1}\leq b_{1}\leq N$ and
$1\leq a_{1}\leq b_{1}\leq N$ and 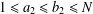 $1\leq a_{2}\leq b_{2}\leq N$.
$1\leq a_{2}\leq b_{2}\leq N$.
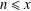
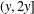
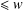
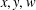
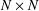
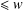
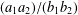
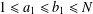
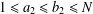
ODD–EVEN DECOMPOSITION OF FUNCTIONS
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 102 / Issue 1 / August 2020
- Published online by Cambridge University Press:
- 08 January 2020, pp. 104-108
- Print publication:
- August 2020
-
- Article
-
- You have access
- Export citation
On resampling schemes for polytopes
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 56 / Issue 4 / December 2019
- Published online by Cambridge University Press:
- 11 December 2019, pp. 959-980
- Print publication:
- December 2019
-
- Article
- Export citation
-
The convex hull of a sample is used to approximate the support of the underlying distribution. This approximation has many practical implications in real life. To approximate the distribution of the functionals of convex hulls, asymptotic theory plays a crucial role. Unfortunately most of the asymptotic results are computationally intractable. To address this computational intractability, we consider consistent bootstrapping schemes for certain cases. Let
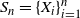 $S_n=\{X_i\}_{i=1}^{n}$ be a sequence of independent and identically distributed random points uniformly distributed on an unknown convex set in
$S_n=\{X_i\}_{i=1}^{n}$ be a sequence of independent and identically distributed random points uniformly distributed on an unknown convex set in 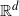 $\mathbb{R}^{d}$ (
$\mathbb{R}^{d}$ (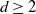 $d\ge 2$). We suggest a bootstrapping scheme that relies on resampling uniformly from the convex hull of
$d\ge 2$). We suggest a bootstrapping scheme that relies on resampling uniformly from the convex hull of 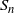 $S_n$. Moreover, the resampling asymptotic consistency of certain functionals of convex hulls is derived under this bootstrapping scheme. In particular, we apply our bootstrapping technique to the Hausdorff distance between the actual convex set and its estimator. For
$S_n$. Moreover, the resampling asymptotic consistency of certain functionals of convex hulls is derived under this bootstrapping scheme. In particular, we apply our bootstrapping technique to the Hausdorff distance between the actual convex set and its estimator. For 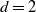 $d=2$, we investigate the asymptotic consistency of the suggested bootstrapping scheme for the area of the symmetric difference and the perimeter difference between the actual convex set and its estimate. In all cases the consistency allows us to rely on the suggested resampling scheme to study the actual distributions, which are not computationally tractable.
$d=2$, we investigate the asymptotic consistency of the suggested bootstrapping scheme for the area of the symmetric difference and the perimeter difference between the actual convex set and its estimate. In all cases the consistency allows us to rely on the suggested resampling scheme to study the actual distributions, which are not computationally tractable.
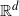
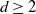
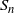
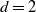
ORDERING RESULTS ON EXTREMES OF EXPONENTIATED LOCATION-SCALE MODELS
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 35 / Issue 2 / April 2021
- Published online by Cambridge University Press:
- 18 October 2019, pp. 331-354
-
- Article
- Export citation
Conditional tail independence in Archimedean copula models
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 56 / Issue 3 / September 2019
- Published online by Cambridge University Press:
- 01 October 2019, pp. 858-869
- Print publication:
- September 2019
-
- Article
- Export citation
-
Consider a random vector
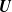 $\textbf{U}$ whose distribution function coincides in its upper tail with that of an Archimedean copula. We report the fact that the conditional distribution of
$\textbf{U}$ whose distribution function coincides in its upper tail with that of an Archimedean copula. We report the fact that the conditional distribution of 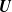 $\textbf{U}$, conditional on one of its components, has under a mild condition on the generator function independent upper tails, no matter what the unconditional tail behavior is. This finding is extended to Archimax copulas.
$\textbf{U}$, conditional on one of its components, has under a mild condition on the generator function independent upper tails, no matter what the unconditional tail behavior is. This finding is extended to Archimax copulas.
EXPLORATION–EXPLOITATION POLICIES WITH ALMOST SURE, ARBITRARILY SLOW GROWING ASYMPTOTIC REGRET
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 34 / Issue 3 / July 2020
- Published online by Cambridge University Press:
- 26 January 2019, pp. 406-428
-
- Article
- Export citation
Asymptotic analysis of the Ginzburg–Landau functional on point clouds
- Part of
-
- Journal:
- Proceedings of the Royal Society of Edinburgh. Section A: Mathematics / Volume 149 / Issue 2 / April 2019
- Published online by Cambridge University Press:
- 27 December 2018, pp. 387-427
- Print publication:
- April 2019
-
- Article
- Export citation
Convergence rates for estimators of geodesic distances and Frèchet expectations
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 55 / Issue 4 / December 2018
- Published online by Cambridge University Press:
- 16 January 2019, pp. 1001-1013
- Print publication:
- December 2018
-
- Article
-
- You have access
- Export citation
Effective procedure of verifying stochastic ordering of system lifetimes
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 55 / Issue 4 / December 2018
- Published online by Cambridge University Press:
- 16 January 2019, pp. 1261-1271
- Print publication:
- December 2018
-
- Article
- Export citation
Large data limit for a phase transition model with the p-Laplacian on point clouds
- Part of
-
- Journal:
- European Journal of Applied Mathematics / Volume 31 / Issue 2 / April 2020
- Published online by Cambridge University Press:
- 14 November 2018, pp. 185-231
-
- Article
- Export citation
On the consistency of the spacings test for multivariate uniformity, including on manifolds
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 55 / Issue 2 / June 2018
- Published online by Cambridge University Press:
- 26 July 2018, pp. 659-665
- Print publication:
- June 2018
-
- Article
- Export citation
A Note on Rényi's ‘Record’ Problem and Engel's Series
- Part of
-
- Journal:
- Proceedings of the Edinburgh Mathematical Society / Volume 61 / Issue 2 / May 2018
- Published online by Cambridge University Press:
- 15 February 2018, pp. 363-369
-
- Article
- Export citation
On sequences of expected maxima and expected ranges
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 54 / Issue 4 / December 2017
- Published online by Cambridge University Press:
- 30 November 2017, pp. 1144-1166
- Print publication:
- December 2017
-
- Article
- Export citation
Estimating perimeter using graph cuts
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 49 / Issue 4 / December 2017
- Published online by Cambridge University Press:
- 17 November 2017, pp. 1067-1090
- Print publication:
- December 2017
-
- Article
- Export citation
Simulation from quasi-stationary distributions on reducible state spaces
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 49 / Issue 3 / September 2017
- Published online by Cambridge University Press:
- 08 September 2017, pp. 960-980
- Print publication:
- September 2017
-
- Article
- Export citation
A new analytical approach to consistency and overfitting in regularized empirical risk minimization
- Part of
-
- Journal:
- European Journal of Applied Mathematics / Volume 28 / Issue 6 / December 2017
- Published online by Cambridge University Press:
- 20 July 2017, pp. 886-921
-
- Article
-
- You have access
- Export citation
