Refine search
Actions for selected content:
53194 results in Statistics and Probability
High prevalence of asymptomatic malaria in Forest Guinea: Results from a rapid community survey
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 05 December 2023, e1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Analysis of a SARIMA-XGBoost model for hand, foot, and mouth disease in Xinjiang, China
-
- Journal:
- Epidemiology & Infection / Volume 151 / 2023
- Published online by Cambridge University Press:
- 04 December 2023, e200
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
APR volume 55 issue 4 Cover and Back matter
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 19 December 2023, pp. b1-b2
- Print publication:
- December 2023
-
- Article
-
- You have access
- Export citation
Speed of extinction for continuous-state branching processes in a weakly subcritical Lévy environment
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 01 December 2023, pp. 886-908
- Print publication:
- September 2024
-
- Article
- Export citation
JPR volume 60 issue 4 Cover and Back matter
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 22 December 2023, pp. b1-b2
- Print publication:
- December 2023
-
- Article
-
- You have access
- Export citation
A subgeometric convergence formula for finite-level M/G/1-type Markov chains: via a block-decomposition-friendly solution to the Poisson equation of the deviation matrix
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 56 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 01 December 2023, pp. 389-429
- Print publication:
- June 2024
-
- Article
- Export citation
JPR volume 60 issue 4 Cover and Front matter
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 22 December 2023, pp. f1-f2
- Print publication:
- December 2023
-
- Article
-
- You have access
- Export citation
Daryl John Daley, 4 April 1939 – 16 April 2023 An internationally acclaimed researcher in applied probability and a gentleman of great kindness
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 22 December 2023, pp. 1516-1531
- Print publication:
- December 2023
-
- Article
-
- You have access
- HTML
- Export citation
Precise large deviations for a multidimensional risk model with regression dependence structure
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 2 / April 2024
- Published online by Cambridge University Press:
- 01 December 2023, pp. 448-457
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In this paper, we consider a nonstandard multidimensional risk model, in which the claim sizes
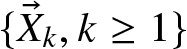 $\{\vec{X}_k, k\ge 1\}$ form an independent and identically distributed random vector sequence with dependent components. By assuming that there exists the regression dependence structure between inter-arrival time and the claim-size vectors, we extend the regression dependence to a more practical multidimensional risk model. For the univariate marginal distributions of claim vectors with consistently varying tails, we obtain the precise large deviation formulas for the multidimensional risk model with the regression size-dependent structure.
$\{\vec{X}_k, k\ge 1\}$ form an independent and identically distributed random vector sequence with dependent components. By assuming that there exists the regression dependence structure between inter-arrival time and the claim-size vectors, we extend the regression dependence to a more practical multidimensional risk model. For the univariate marginal distributions of claim vectors with consistently varying tails, we obtain the precise large deviation formulas for the multidimensional risk model with the regression size-dependent structure.
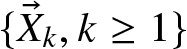
Optimal Stopping Methodology for the Secretary Problem with Random Queries – ADDENDUM
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 22 December 2023, p. 1532
- Print publication:
- December 2023
-
- Article
- Export citation
Seasonal mortality amongst UK occupational pension scheme members 2000–2016
-
- Journal:
- British Actuarial Journal / Volume 28 / 2023
- Published online by Cambridge University Press:
- 01 December 2023, e11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
APR volume 55 issue 4 Cover and Front matter
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 19 December 2023, pp. f1-f2
- Print publication:
- December 2023
-
- Article
-
- You have access
- Export citation
Chapter Six - Simple Linear Regression
-
- Book:
- Statistics Using Stata
- Published online:
- 26 January 2024
- Print publication:
- 30 November 2023, pp 204-230
-
- Chapter
- Export citation
Preface
-
- Book:
- Statistics and Data Visualization in Climate Science with R and Python
- Published online:
- 09 November 2023
- Print publication:
- 30 November 2023, pp xiii-xviii
-
- Chapter
- Export citation
Dedication
-
- Book:
- Statistics Using Stata
- Published online:
- 26 January 2024
- Print publication:
- 30 November 2023, pp v-vi
-
- Chapter
- Export citation
Chapter Three - Measures of Location, Spread, and Skewness
-
- Book:
- Statistics Using Stata
- Published online:
- 26 January 2024
- Print publication:
- 30 November 2023, pp 75-118
-
- Chapter
- Export citation
7 - Introduction to Time Series
-
- Book:
- Statistics and Data Visualization in Climate Science with R and Python
- Published online:
- 09 November 2023
- Print publication:
- 30 November 2023, pp 243-286
-
- Chapter
- Export citation
Appendix D - Solutions
-
- Book:
- Statistics Using Stata
- Published online:
- 26 January 2024
- Print publication:
- 30 November 2023, pp 745-745
-
- Chapter
- Export citation
2 - Elementary Probability and Statistics
-
- Book:
- Statistics and Data Visualization in Climate Science with R and Python
- Published online:
- 09 November 2023
- Print publication:
- 30 November 2023, pp 35-72
-
- Chapter
- Export citation
Appendix A - Data Set Descriptions
-
- Book:
- Statistics Using Stata
- Published online:
- 26 January 2024
- Print publication:
- 30 November 2023, pp 707-719
-
- Chapter
- Export citation
